 By
By Give a front-end to your data insights
Pandas is one of the most popular data science libraries for analysing and manipulating data. But what if you want to take the data that you have manipulated with Pandas and present it to other people in a visual manner? With Anvil, you can take a local script or a Jupyter notebook and turn it into an interactive dashboard — all for free and entirely in Python.
In this tutorial, we’re going to build a dashboard app using the Netflix Movies and TV Shows dataset by Shivam Bansal. You can also download the data directly in the link below:
We’ll use Pandas to manipulate our data in a local script or a notebook, Plotly to visualize it, and the Anvil Uplink to connect it to an app and turn it into an interactive dashboard.
These are the steps that we will cover:
- We’ll start by creating our Anvil app.
- Then, we’ll design our dashboard using Anvil components.
- After that, we’ll clean and prepare the data for plotting.
- We will then connect our script or notebook to our app via the Uplink.
- Using Plotly, we will build our plots.
- Finally, we will add some finishing touches to our dashboard.
Let’s get started!
Step 1: Create your Anvil app
Go to the Anvil Editor, click on “Blank App”, and choose “Rally”. We just want an empty app, so we’ll delete the current Form1 and then add a new Blank Panel form:
Now let’s rename our app. Click on the app’s name, on the top left corner of the screen. This takes us to the General Settings page, where we can modify our app’s name.
Step 2: Design your dashboard
We will build our user interface by adding drag-and-drop components from the Toolbox. First, add a ColumnPanel  , where we will fit all our other components. Then, let’s add three Plots
, where we will fit all our other components. Then, let’s add three Plots ![]() into the ColumnPanel - we can adjust their sizes by clicking and dragging their edges (use Ctrl+Drag for finer adjustments).
into the ColumnPanel - we can adjust their sizes by clicking and dragging their edges (use Ctrl+Drag for finer adjustments).
We’ll also drop a Label ![]() into our app and place it above the plots. Select your Label and, in the Properties Panel on the right, change the text to “Netflix Content Dashboard”. Set the
into our app and place it above the plots. Select your Label and, in the Properties Panel on the right, change the text to “Netflix Content Dashboard”. Set the font_size to 32 and, if you want, you can customize the font.
Finally, we’ll set the spacing_above property of all the components to large (you can find this under the Layout section of the Properties Panel).
Step 3: Get the data into shape
It’s time to clean our data and get it ready to display. Create a file in your favorite development enviroment – open up a new Jupyter notebook, or create a new script in your IDE of choice. All the code included in this tutorial will work with both options.
First, import Pandas at the top. Then, write the csv_to_df function, which will fetch the data in from our CSV file and convert it into a Pandas DataFrame.
import pandas as pd
def csv_to_df(f):
return pd.read_csv(f, index_col=0)Before we can plot our data, we need to clean it and prepare it for plotting. We’ll do all the necessary transformations to our data inside a function that we’ll call prepare_netflix_data. In it, we’ll first call our csv_to_df function to fetch our data.
def prepare_netflix_data():
netflix_df = csv_to_df('netflix_titles.csv')Our figures will only use data from the type, country and date_added columns, so we’ll slice our DataFrame using the loc property.
netflix_df = netflix_df.loc[:,['type', 'country', 'date_added']]There are also some missing values that we’ll have to deal with, so that we don’t include missing data in our plots. Pandas has a few different ways to handle missing values, but in this case we’ll just use dropna to get rid of them:
netflix_df = netflix_df.dropna(subset=['country'])The country column contains the production country of each movie or TV Show in Netflix. However, some of them have more than one country listed. For simplicity, we’re going to assume the first one mentioned is the most important one, and we’ll ignore the others. We’ll also create a separate DataFrame that only contains the value counts for this column, sorted by country – this will be useful later on when we input the data into our plots.
netflix_df['country'] = [countries[0] for
countries in netflix_df['country'].str.split(',')]
country_counts = pd.DataFrame(
netflix_df['country'].value_counts().rename_axis('countries').reset_index(name='counts')).sort_values(by=['countries'])Our date_added variable currently contains only strings, which is not a very easy format to work with when we want to plot something in chronological order. Because of this, we’ll convert it into datetime format using to_datetime, which will allow us to easily order the data by year later on.
netflix_df['date_added'] = pd.to_datetime(netflix_df['date_added'], exact=False)We’ll return our transformed dataframe and the country_counts variable that we just created. This is how the full function should look by the end:
def prepare_netflix_data():
netflix_df = csv_to_df('netflix')
netflix_df = netflix_df.loc[:,['type', 'country', 'date_added']]
netflix_df = netflix_df.dropna()
netflix_df['country'] = [countries[0] for countries in netflix_df['country'].str.split(',')]
country_counts = pd.DataFrame(netflix_df['country'].value_counts().rename_axis('countries').reset_index(name='counts')).sort_values(by=['countries'])
netflix_df['date_added'] = pd.to_datetime(netflix_df['date_added'], exact=False)
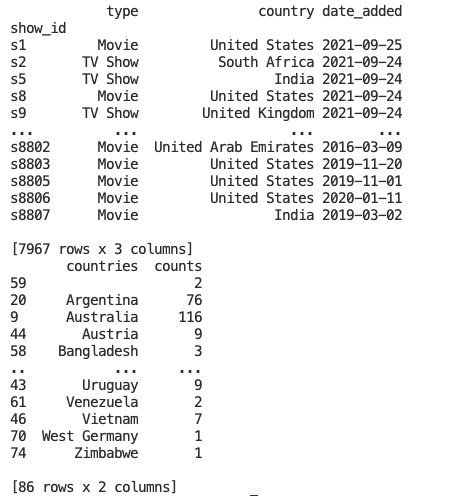
return netflix_df, country_countsFinally, we can print the output of netflix_df and country_counts, to make sure everything looks right.
print(prepare_netflix_data())This is what the output should look like:
Now that we’re happy with how our data looks, we can build our plots but, before that, we’ll have to connect our local script to our Anvil app.
Step 4: Making the connection
Right now, our code is running on our computer or in our Jupyter notebook, but we will want the plots we build to display on our app and run on the web browser. To be able to do this, we will have to connect our local code to our Anvil app and make the functions we’ve written in our local code callable from the app. In this way, the local code acts as the server, while the app runs all the client-side code in the web browser.
To connect our local script to our app, let’s first enable the Anvil Uplink. In the Editor, click the + button in the Sidebar Menu, select Uplink and click on + Enable server Uplink.
After this, we need to pip install the Uplink library on our local machine (use !pip install instead, if working on a Jupyter notebook):
pip install anvil-uplinkNow we’ll add the following lines at the top of our local script (you can copy them from your Uplink window dialog):
import anvil.server
anvil.server.connect("<your-uplink-key-here>")If you’re using a local script, we will also add anvil.server.wait_forever() at the very bottom of our script, which will keep our script running to allow our app to call functions in it. All the rest of the code we write going forward will go above this line. This is not necessary for Jupyter notebooks.
anvil.server.wait_forever()anvil.server.callable functions will only remain accessible while your notebook kernel is active. Many hosted notebook environments, such as Google Colab, will shutdown kernels that have been idle for some time. You may be able to increase this timeout by having a cell continually running - while True: sleep(1) will do, and this is exactly what anvil.server.wait_forever() does. Even then, hosted kernels are unlikely to run forever, and for production deployments you should see our Deploy a Google Colab Notebook with Docker guide.With this, our local script is connected to our app. This means it can now do anything we can do in an Anvil Server Module.
Step 5: Build the plots
We now need to take our processed data and turn it into the plots that we will want to display. Our data is in a pandas DataFrame right now, which means that we require pandas to read it. Because of this, we can’t send the data directly to our app because pandas is not available to the web browser, or client (learn more about why certain packages are not available in the client in our Client vs Server code in Anvil explainer).
However, we can send already built plots instead. Because of this, we’ll first build our figures in our script or notebook, and then we’ll return the plots to our app to display them.
Our dashboard will contain three figures:
- A map showing the number of films per production country
- A content type pie chart
- A line chart of content added through time
Now, we need to create them. We’ll first import plotly.graph_objects, then write the create_plots function. Before anything else, we’ll call our prepare_netflix_data function to fetch our transformed data. After that, we’ll first create and return our map plot, using Plotly’s Scattergeo. Remember to add this code above the anvil.server.wait_forever() call if working on a local script.
import plotly.graph_objects as go
@anvil.server.callable
def create_plots():
netflix_df, country_counts = prepare_netflix_data()
fig1 = go.Scattergeo(
locations=sorted(netflix_df['country'].unique().tolist()),
locationmode='country names',
text=country_counts['counts'],
marker=dict(size=country_counts['counts'], sizemode='area'))
return fig1We made this function available from the client side of our app by decorating it as @anvil.server.callable, which means we can access our function’s output from our Anvil app in order to display our figures. We’ll do this by using anvil.server.call inside the __init__ method in our Form1 code to call our function. Then, we’ll assign the output to our plot’s data property.
class Form1(Form1Template):
def __init__(self, **properties):
# Set Form properties and Data Bindings.
super().__init__(**properties)
fig1 = anvil.server.call('create_plots')
self.plot_1.data = fig1We can check that everything is working like we want it to by running our local script or notebook and our app. This is how it looks so far:

Let’s now do the same with our other two plots. We’ll add a pie chart and a line chart to our create_plots function:
@anvil.server.callable
def create_plots():
netflix_df, country_counts = prepare_netflix_data()
fig1 = go.Scattergeo(
locations=sorted(netflix_df['country'].unique().tolist()),
locationmode='country names',
text=country_counts['counts'],
marker=dict(
size=country_counts['counts'],
line_width=0,
sizeref=2,
sizemode='area',
reversescale=True
))
fig2 = go.Pie(
labels=netflix_df['type'],
values=netflix_df['type'].value_counts(),
hole=.4,
textposition='inside',
textinfo='percent+label'
)
fig3 = go.Scatter(
x=netflix_df['date_added'].dt.year.value_counts().sort_index().index,
y=netflix_df['date_added'].dt.year.value_counts().sort_index()
)
return fig1, fig2, fig3And we’ll call them from the client in the same way we did our previous plot:
class Form1(Form1Template):
def __init__(self, **properties):
# Set Form properties and Data Bindings.
super().__init__(**properties)
fig1, fig2, fig3 = anvil.server.call('create_plots')
self.plot_1.data = fig1
self.plot_2.data = fig2
self.plot_3.data = fig3With that, we have a functional dashboard:
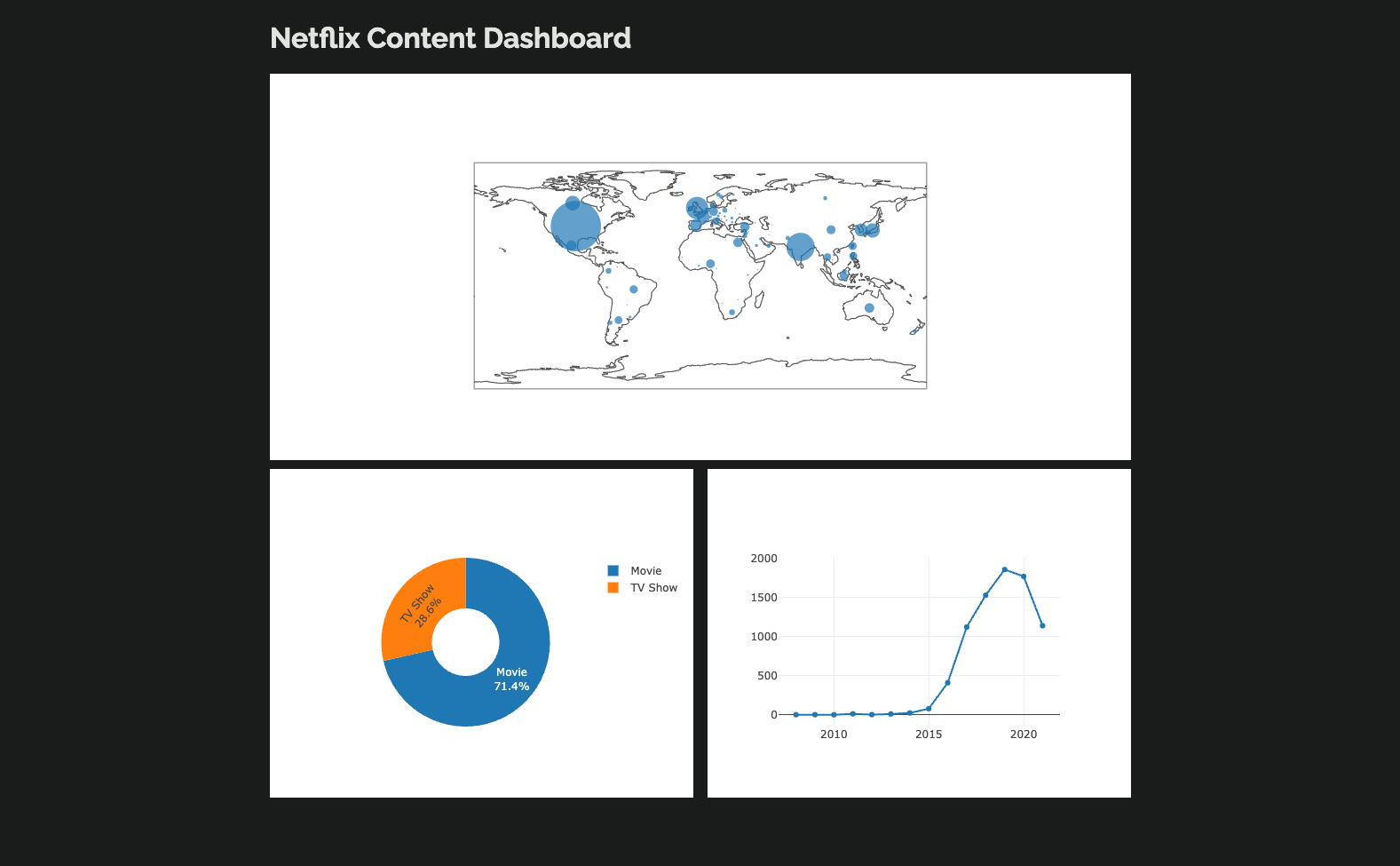
How our dashboard looks so far.
Step 6: Finishing touches
With everything set up, we can move onto customizing our plots. Plotly supports pre-configured templates that describe plot styling, and Anvil provides pre-built templates to match our Rally and M3 themes. We can apply these through the templates property.
For this dashboard, I’m going to choose the rally plot theme, which will match the colour scheme and styling of our app. I will set it as the default plot theme for the app by adding this line of code to the __init__ method:
class Form1(Form1Template):
def __init__(self, **properties):
# Set Form properties and Data Bindings.
super().__init__(**properties)
Plot.templates.default = "rally"This is how the plots look now:
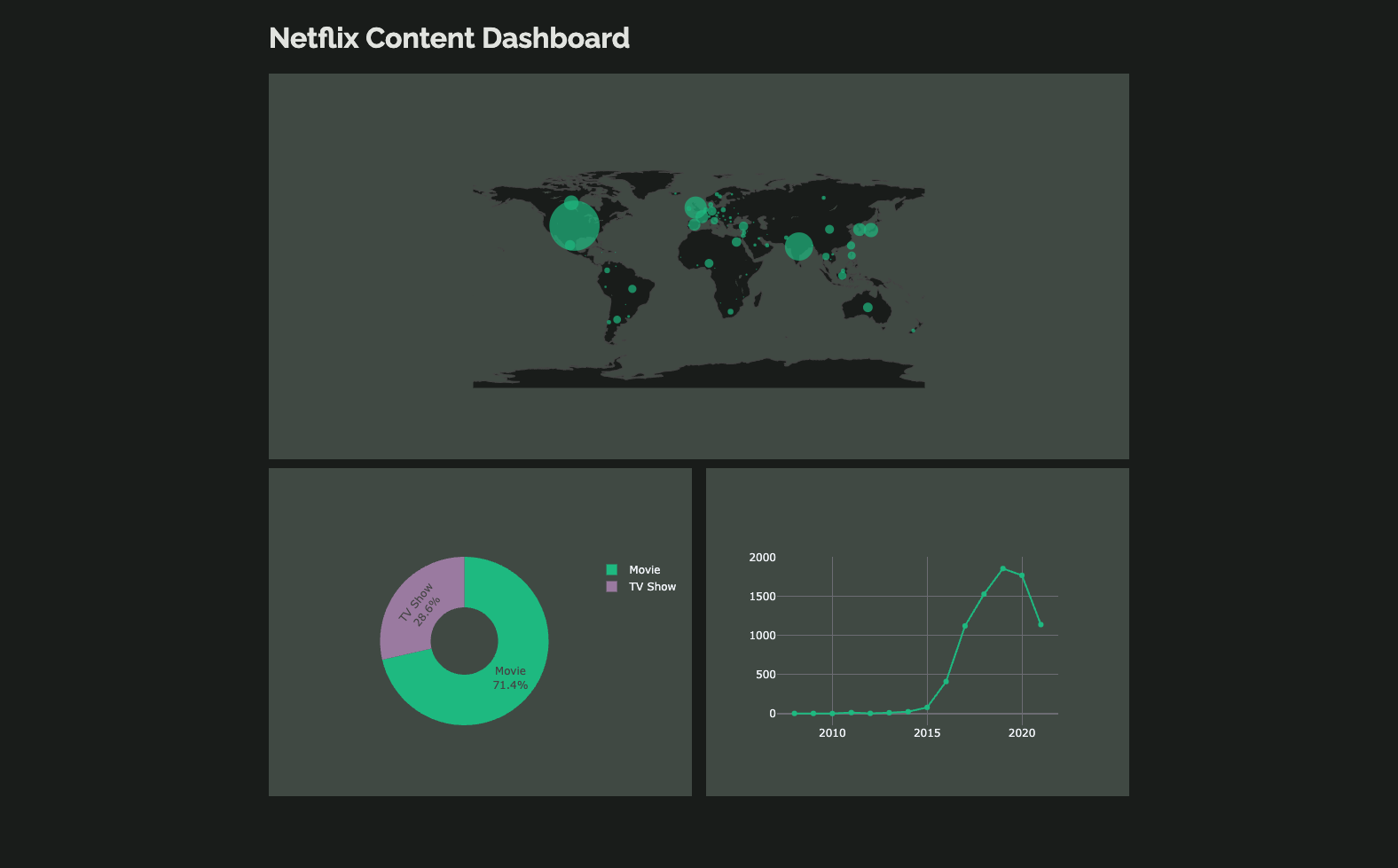
Our dashboard styled with the Rally plots theme.
Finally, we’ll change our plots’ margins and font by using their layout property. We’ll also add titles to each one:
fig1, fig2, fig3 = anvil.server.call('create_plots')
self.plot_1.data = fig1
self.plot_1.layout.margin = dict(t=60, b=30, l=0, r=0)
self.plot_1.layout.font.family = 'Raleway'
self.plot_1.layout.title = 'Production countries'
self.plot_2.data = fig2
self.plot_2.layout.margin = dict(t=60, b=30, l=10, r=10)
self.plot_2.layout.font.family = 'Raleway'
self.plot_2.layout.title = 'Content breakdown by type'
self.plot_3.data = fig3
self.plot_3.layout.margin = dict(t=60, b=40, l=50, r=50)
self.plot_3.layout.font.family = 'Raleway'
self.plot_3.layout.title = 'Content added over time'After these changes, our dashboard is ready to be shared! All you need to do now is publish your app to make it available to the world.
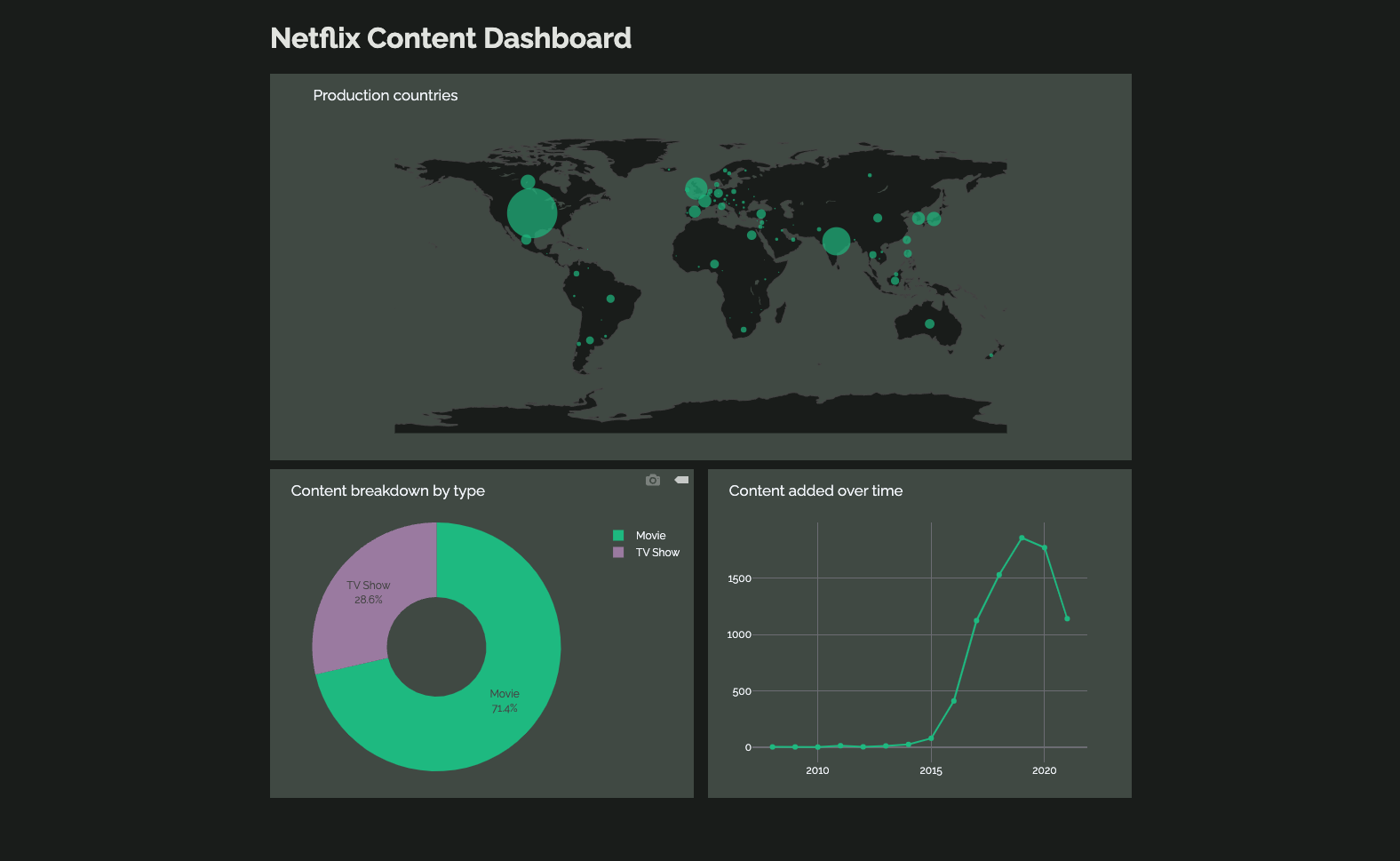
The final result.
Want to turn off your computer?
Now that we’ve finished developing our dashboard, you might want to want to stop relying on your local script. You can upload the data set to Anvil, and run our data processing code in an Anvil Server Module, so our dashboard will still work if we stop our script or turn off our computer.
If you want to learn how to do this, check out this tutorial:
Clone the App
If you want to check out the source code for our Netflix dashboard, click on the links below and clone the app, download the local script and access the Jupyter notebook on Colab:
New to Anvil?
If you’re new here, welcome! Anvil is a platform for building full-stack web apps with nothing but Python. No need to wrestle with JS, HTML, CSS, Python, SQL and all their frameworks – just build it all in Python.
Yes – Python that runs in the browser. Python that runs on the server. Python that builds your UI. A drag-and-drop UI editor. We even have a built-in Python database, in case you don’t have your own.
Why not have a play with the app builder? It’s free! Click here to get started: