 By
By I’m building a search engine using Anvil. So far I’ve built a Python web app that crawls the web downloading pages. I’ve also implemented PageRank so my app surfaces the most important pages.
PageRank weeded out minor pages and made room for more important matches. But it doesn’t take page content into account, so the ranking was still a bit hit-and-miss.
I’m currently using Anvil’s full_text_match to perform the search for me. I’m treating it as a black box, which
has saved me effort. But it’s time to take matters into my own hands. I’m going to explore more about how the actual search
process works.
Tokens
I want to rank pages higher if they have more matching words in them.
My pages are currently just stored as big unrefined strings of characters. It’s time to digest each page and get a precise definition of its meaning. I need to tokenize the page - split it into the elemental parts of language.
Python is great for string processing, so this is really easily accomplished. First I use BeautifulSoup
to get rid of the <script> and <style> blocks that don’t tell me much about the page’s meaning. I also discard the HTML
tags and punctuation:
from string import punctuation
def tokenize(html):
soup = BeautifulSoup(html)
# Remove script and style blocks
for script in soup.find_all('script'):
script.decompose()
for style in soup.find_all('style'):
style.decompose()
# Remove HTML
text = soup.get_text()
# Remove punctuation
text = text.translate(str.maketrans('', '', punctuation))
# Split the string into a list of words
tokens = text.split()The last step splits the string into a list of separate words. These are one kind of token, but I want more useful tokens, so I’m going to go a bit further.
I’m going to stem my tokens, and I’m going to remove stop words. I mentioned these techinques when I discussed
full_text_search in my first search engine post. To recap:
- Stemming means each token will be the stem of the word, rather than the word itself. The words ‘build’, ‘building’ and ‘builds’ will all get stored as ‘build’, so they all have the same impact on the search results.
- Stop words are common words like ‘how’ and ’to’ that don’t have much bearing on the meaning of a page.
I’m going to remove any words from the stop words list used by PostgreSQL’s
tsquery.
I’m going to do stemming the way you do anything in Python - import a library that does it all for you!
In this case I’m using nltk, the Natural Language Toolkit that has a selection of stemming algorithms.
from nltk import PorterStemmer
stemmer = PorterStemmer()
STOP_WORDS = [
'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves',
'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their',
'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are',
'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an',
'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about',
'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up',
'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when',
'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor',
'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now'
]
def tokenize(html):
# The code I had before, which got me a list of words, then...
# Stem
tokens = [stemmer.stem(t) for t in tokens]
# Remove stop words
tokens = [t for t in tokens if t not in STOP_WORDS]
# Count occurrances of each token
return dict(Counter(tokens))The final bit of processing in the return statement counts the occurrence of each token in the list.
So if my list was originally:
[
'application'
'build',
'python',
'web',
'application',
'web'
]I end up with:
{'application': 2, 'build': 1, 'web': 2, 'python': 1}This is just what I need to improve my search results - a count of each meaningful word in the page. Now I can order the pages based on how many times they mention each query word.
It’s more than that though – it’s also going to let me make my search a lot more scalable. If I ever hope to handle the entire web, I can’t rely on scanning every page for each query. Loading 130 Trillion HTML documents into memory every time somebody searches is a little sub-optimal.
Luckily, I already have everything I need to build a search index.
Scaling search using an index
Think of an index just like an index in the back of a book. If you’re looking for a particular word in a book, you don’t read the entire book hoping to spot it. You look in the back of the book at the index - you find the word, and it tells you which pages it’s on. That’s exactly what I’m going to do with my web pages.
I’ll create a Data Table to list each token I know about alongside the pages it appears on:
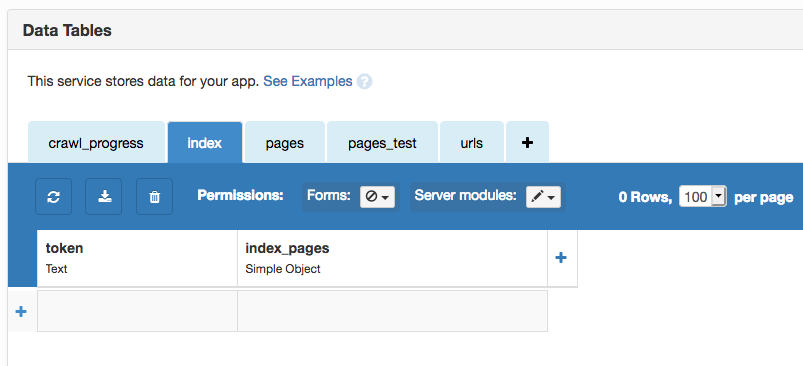
To populate this table, I need to run my tokenize function on all the pages I have stored.
@anvil.server.background_task
def index_pages():
"""Build an index to find pages by looking up words."""
index = {}
for n, page in enumerate(app_tables.pages.search()):
# Tokenize the page
page['token_counts'] = tokenize(page['html'])
# Then organize the tokens into the index
index = collate_tokens(page, index)
# Now persist the index
for token, pages in index.items():
app_tables.index.add_row(token=token, pages=pages)That second for loop writes the index to the database. It’s much faster to build the index in-memory and
persist it all at once than to build it directly into the database.
Here’s how I’m building the index. For each token in the page, I check if there’s an entry for it in the index. If there is, I add this page to it. If not, I create a new row in the index for this token.
def collate_tokens(page, index):
# For each token on the page, add a count to the index
for token, count in page['token_counts'].items():
# Add this count to the index
entry = [{'url': page['url'], 'count': count}]
if token in index:
index[token] += entry
else:
index[token] = entry
return indexI’ve created a UI to launch the indexing process. There’s a button to trigger the Background Task, and I’m keeping track of its progress by plotting the size of the index vs. the number of pages indexed.
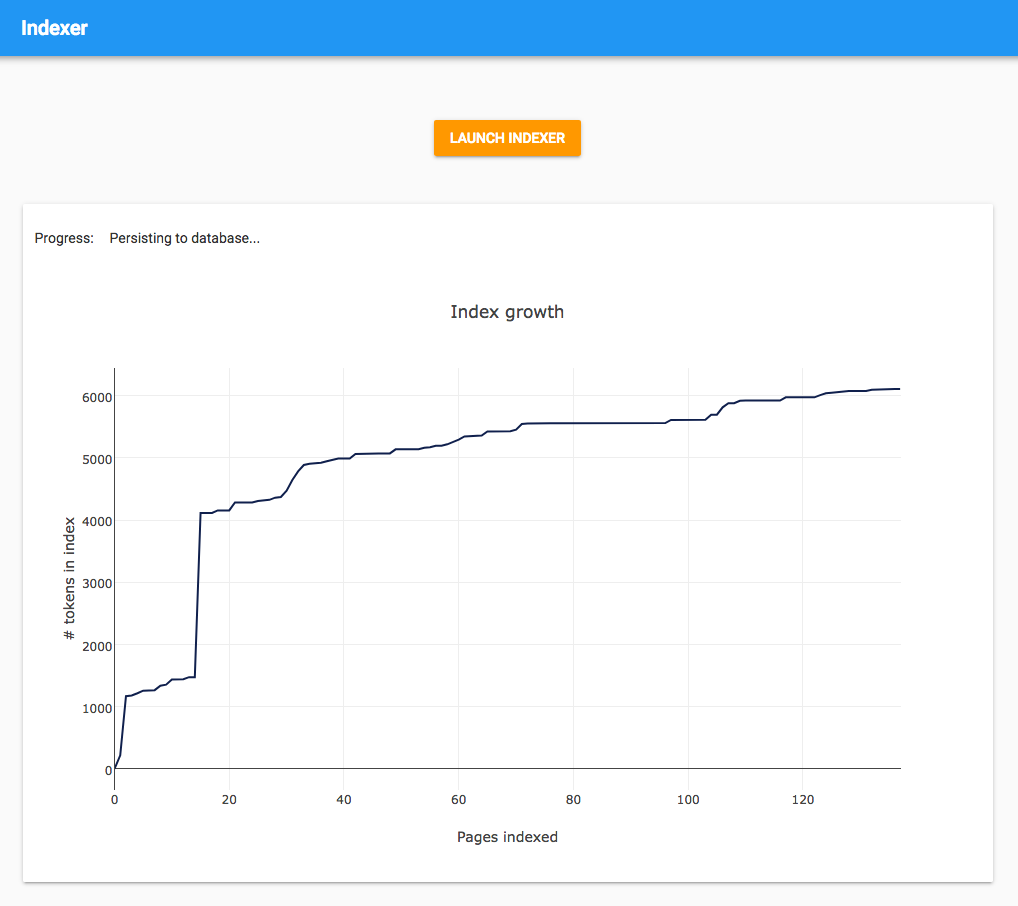
The graph is pretty interesting. You would probably expect it to smoothly approach a particular value, “the number of commonly-used English words”, but actually there are a couple of sudden jumps at the beginning. This must be where it processes large pages with many words, so it discovers a large proportion of the English language at once.
Here’s my index in my Data Table. Now I can look up any word stem and instantly get a list of pages it’s on!
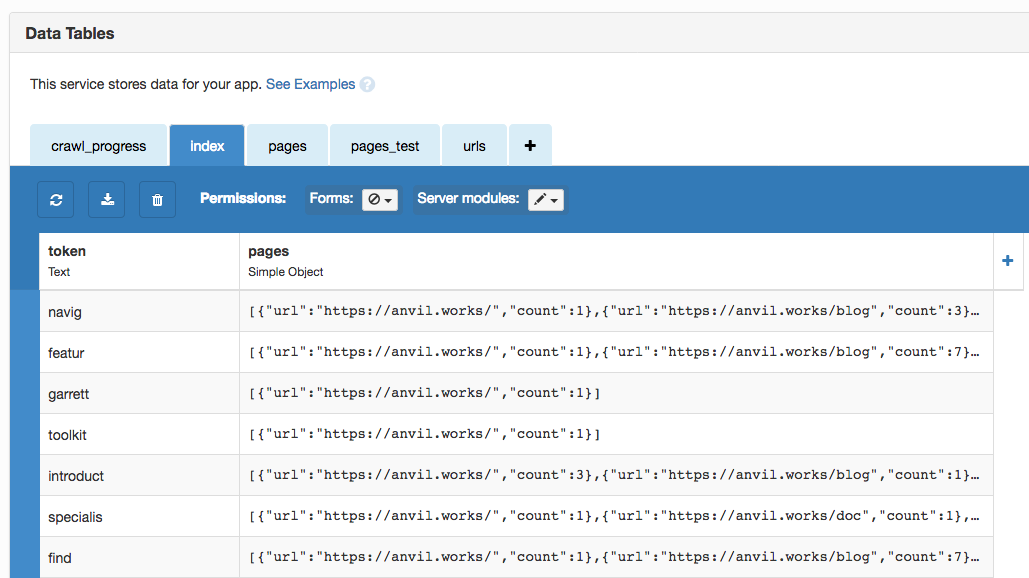
This has been remarkably simple to build, so it’s easy to miss how powerful this is. If I wanted to search all the pages on the web without an index, I would have to scan 130 Trillion HTML documents, each on avarage a few kilobytes in size. Let’s say the avarage size is 10 kB, that’s
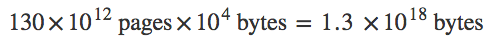
or 1.3 Exabytes of data. You’d need one million 1 Terabyte hard disks to store that much data, and you couldn’t possibly scan it in time to answer a query.
The upper limit on my index size is much, much smaller. There are about 170,000 words in English, and about 6,500 languages in the world. That gives us an estimate of the size of the index:
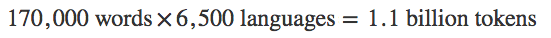
And each entry is just a word, average length around 10 bytes. So about 11 Gigabytes of data. And of course, we can store that in an easily searchable order – for example, alphabetically, so we can find records we want quickly. (Anvil’s Data Tables take care of that for us.)
Somewhere in the multiverse, there’s a universe where the laws of mathematics don’t permit indexing. In that universe, the web never took off.
Ranking by match strength
I’m just moments away from my production-quality search engine. I just need to concoct an algorithm that combines the token counts I’ve created with the PageRank data from the previous post. This will rank pages based on both relevance and importance.
Just as I split my pages into tokens, I can split the search query into tokens too:
query_tokens = tokenize(query)Then I can look up each query token in the index:
index_entries = app_tables.index.search(token=q.any_of(*query_tokens))(If you’d like to understand exactly how I put this line together, check out Querying Data Tables.)
So now I have every index entry that relates to my query. Now we have to work out which of these pages is most relevant! This is where most of Google’s secret sauce is, but we’ll start simple. To compute how relevant each page is to my query, I’ll just sum up the token counts for each page, and use that as the relevance score for the page:
# Sum up the word count scores
page_scores = defaultdict(int)
for index_entry in index_entries:
for index_page in index_entry['pages']:
page = app_tables.pages.get(url=index_page['url'])
page_scores[page] += index_page['count']defaultdict(int) sets unknown keys to have a value of 0, so it’s a great way to calculate sums.)
My page_scores dictionary is just what its name suggests: it maps each page to a total score. This is already a set of ranked search
results! But they’re only ranked by match strength. I’ll multiply each value by the PageRank as well.
# Calculate total scores
final_scores = {}
for page, score in page_scores.items():
final_scores[page] = score * page['rank']If PageRank is Google’s secret sauce, it’s important to know how much to add. In the real app, I’ve used a slightly more complicated formula that uses a constant to tweak the influence of PageRank vs. the relevance score:
score * (1 + (page['rank']-1)*PAGERANK_MULTIPLIER)You can change the PAGERANK_MULTIPLIER to make PageRank more or less important - smaller numbers squeeze the PageRanks towards 1.
What value should I use? You could tune it automatically by changing PAGERANK_MULTIPLIER and comparing
the search results against training data. I did a manual version of this - I tweaked it and ran queries until I was happy with the results.
I went with 1/3.
So now I have a list of pages and a final score for each. I’ll sort in descending order of score, and return only the data I’m interested in - the URL and title of each page, in order.
# Sort by total score
pages = sorted(final_scores.keys(), key=lambda page: -final_scores[page])
# ... and return the page info we're interested in.
return [{"url": p['url'], "title": p['title']} for p in pages]And that’s my final search function! It takes in the same arguments as my other search functions - the query as a string - and returns the pages in the same format, so I can use it from the same UI as the other search functions. Time to compare results and see if I really have improved things.
Final search tests
In each of these posts, I’ve been running three test queries to make a (pretty unscientific) judgement about the quality of my search results. Let’s see how the final algorithm stacks up.
‘Plots’
I selected ‘plots’ as a word that would be common in general technical writing. There are a few pages on the Anvil site that are directly related to plotting, so I’m hoping to see them near the top.
And I do! In fact, the new search algorithm knocks it out of the park.
Four of the top five results directly cover how to make plots in Anvil:
-
the Python Dashboard workshop
Two other results use plots in a big way: SMS Surveys in Pure Python and Using SciPy to work out how many T-shirts I need for a conference.
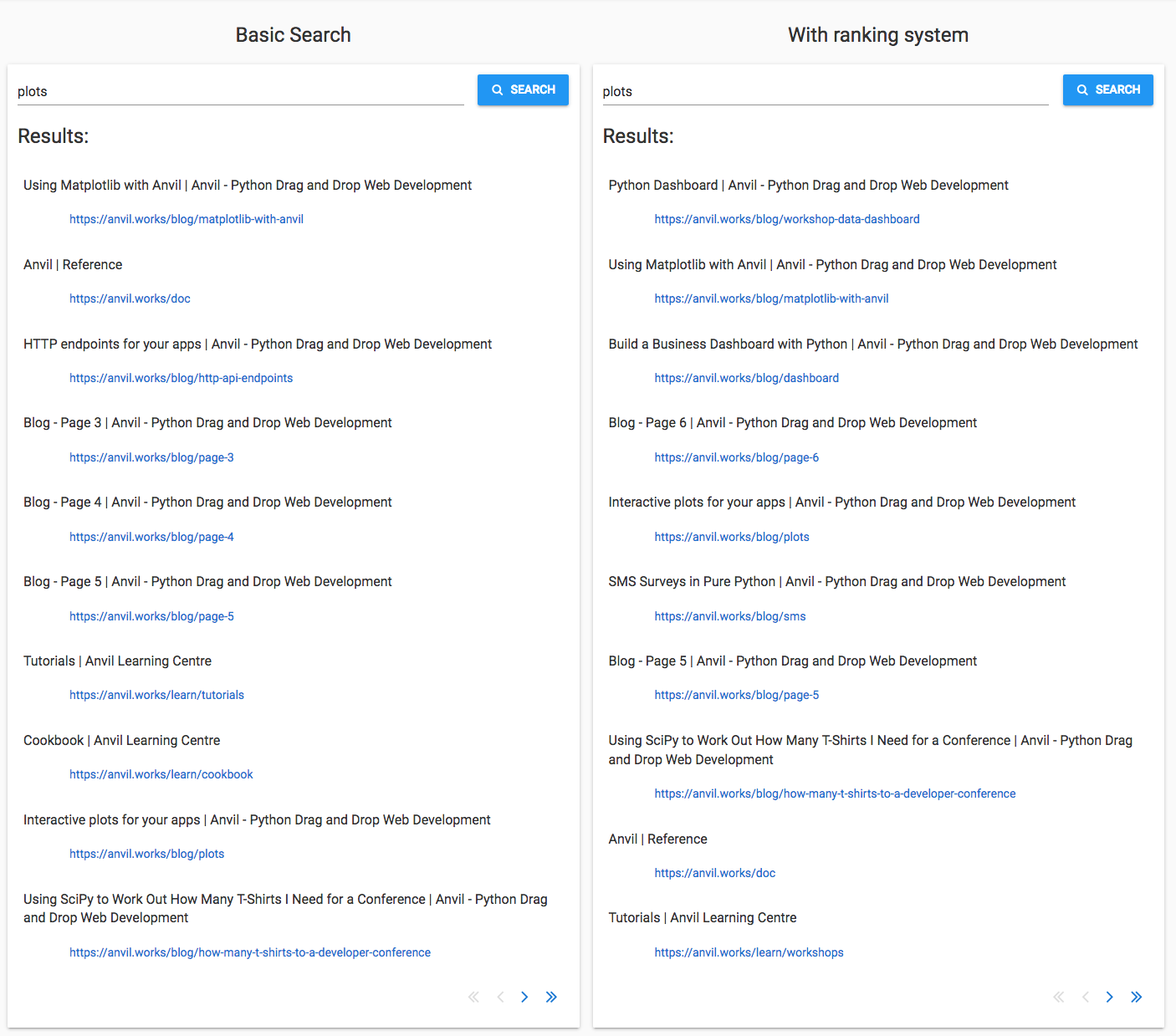
A user who wants to learn about plots in Anvil is pretty well served by this algorithm!
‘Uplink’
I selected ‘Uplink’ because it has a specific meaning for Anvil, and it’s not a commonly-used word otherwise. (If you’re
not familiar with the Anvil Uplink: it allows you to anvil.server.call to and from Python running anywhere.)
The new algorithm does brilliantly at this one too.
The two most relevant pages appear at the top: Using code outside Anvil, followed by Remote Control Panel. The first of these is the Uplink tutorial, so that’s probably what a user searching for ‘Uplink’ is looking for.
The Anvil On-Site Installation page is also in the top five. Among other things, it describes how to connect your app to a Python instance running on your private network, and the answer is ‘Use the Uplink’. That is indeed something somebody interested in the Uplink would like to know.
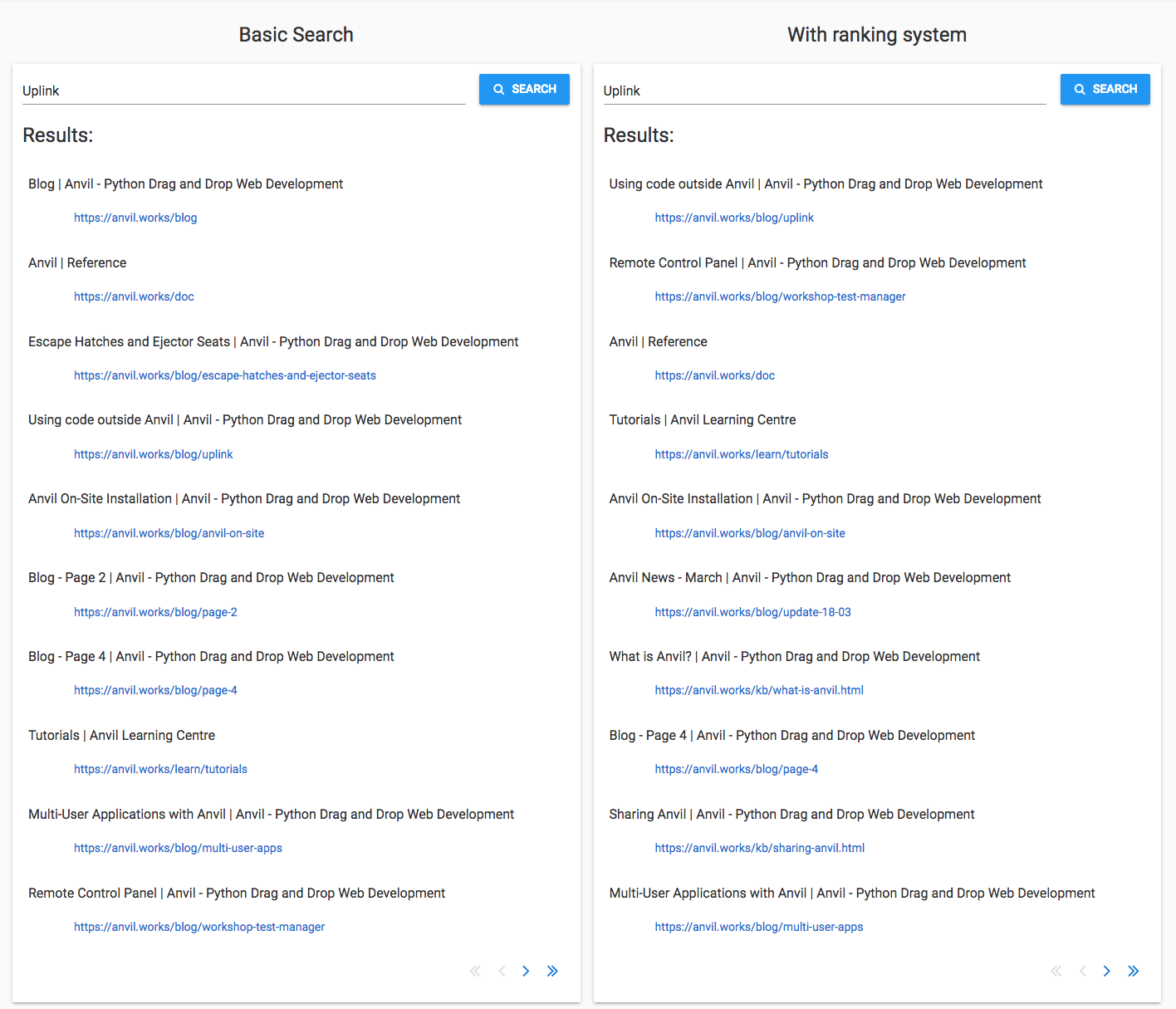
Overall, a great job.
‘Build a dashboard in Python’
This is the most challenging query to answer because it has multiple words, and only one of them particularly signals what the user is looking for - ‘dashboard’.
Item three in the results is Build a Business Dashboard with Python, so that’s a plus point. It doesn’t appear in the Basic Search results at all.
The other page I’d expect to see, the Python Dashboard workshop, isn’t there on the first page. Most of the other pages seem to be included because they mention ‘build’ and ‘Python’ a lot, rather than because they talk about building dashboards in Python.
A couple of partially-related results from the Basic Search don’t appear in the new search: Interactive plots for your apps and the Remote Control Panel workshop.
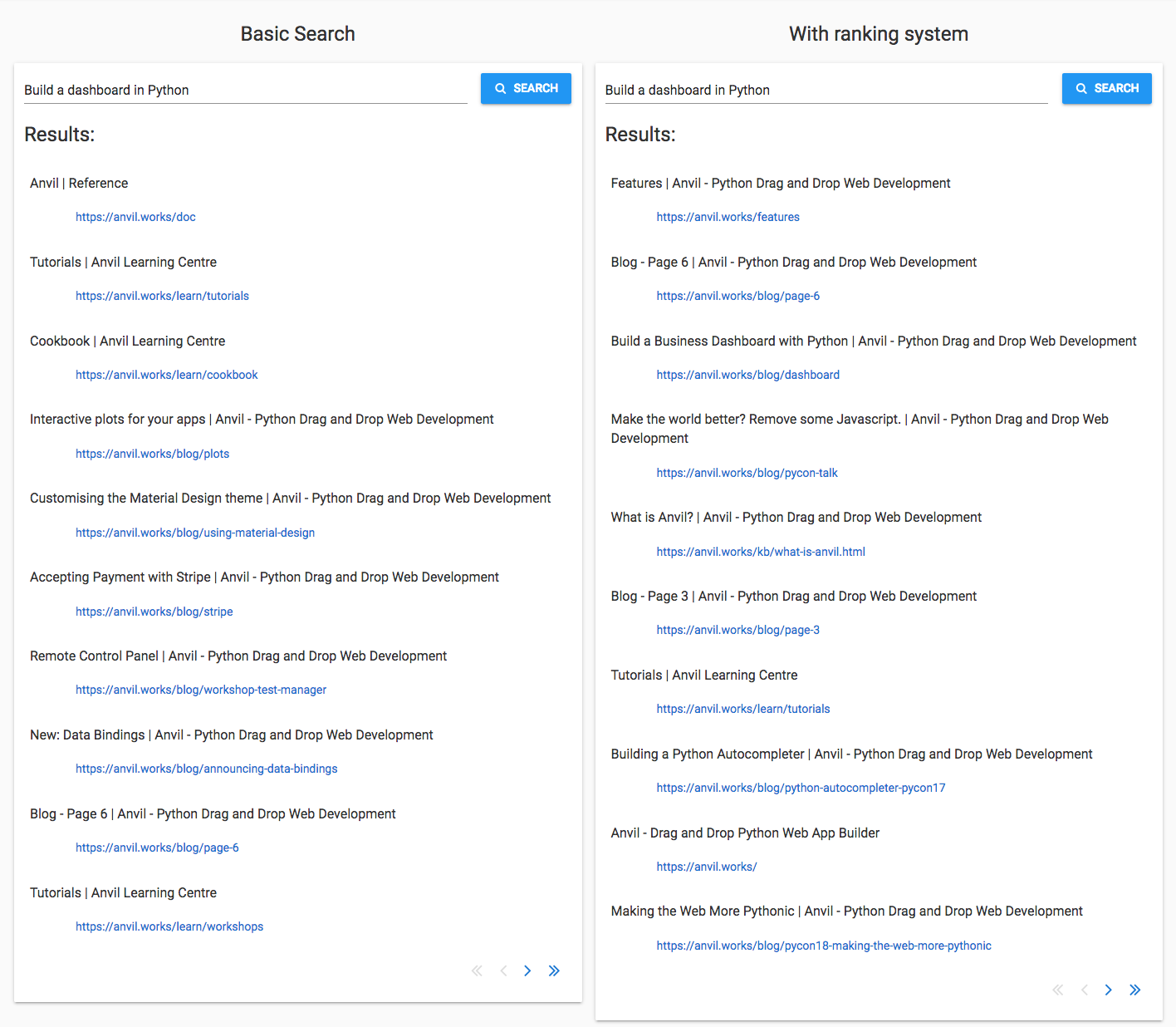
So mixed results for the multi-word query. Neither a massive improvement, nor any worse.
So how did it do?
Nearly perfect results for ‘plots’ and ‘Uplink’, but not much improvement for ‘build a dashboard in Python’. Calculating relevance is hard!
I was hoping that pages with a few mentions of ‘build’ and ‘Python’ would get dropped because they only had low counts of those words. But, this being Anvil, there are pages that mention ‘build’ and ‘Python’ a lot.
Next steps
I need to improve my relevance calculation, and to reduce the noise introduced by ‘build’ and ‘python’ in the multi-word query. Some ideas:
-
I could try matching the entire phrase and/or portions of the phrase (N-grams).
-
I could also start looking at the grammar of the query - ‘dashboard’ is the object noun, so I should weight it higher in the results.
-
Something as simple as giving more weight to words that appear in the page title could also make a big difference.
The most promising step, though, is to ask “which words appear more than usual on this page?” instead of “which words appear often on this page?”. I could do that simply by dividing the word frequencies by the average frequency across all pages. That means words like ‘build’ and ‘python’ that show up on lots of pages would be de-emphasised in the results, but the word ‘dashboard’ will still score highly on dashboard-related pages.
The fun thing about playing with search engines is how many things you can come up with to improve the results. I’ve constructed a simple heuristic based on word counts and PageRank, but you can roll things together in so many different ways. You could start analysing media as well as the pure HTML; you could take account of page structure; or you could even track browsing behaviour (anonymised and with permission, of course!).
Why not try some things out for yourself? Feel free to clone the final app and tinker with it to see if you can do better than me. Then get in touch via the Forum to show me and the rest of the Anvil community what you’ve done!
Make it live!
I’m quite pleased with what I’ve achieved. In a few hundred lines of code, I’ve built a search engine that does a really great job of serving single-word queries from the Anvil site. There’s still room for improvement with multi-word queries, but the results are good enough that the user can find the best match somewhere on the first page of results.
I’m ready to make it public.
As with any Anvil app, it’s auto-hosted at a private URL. To give it a public URL, I just enter my desired subdomain of
anvil.app in this box:
And now my search engine is hosted at https://search.anvil.app!
(If I wanted to use my own domain, rather than anvil.app, of course I could. That’s the “Add Custom Domain” button in that screenshot.)
Now it’s your turn
That’s the end of my search engine journey. I haven’t quite made a competitor to Google, but I’ve built a working search engine from first principles, and I’ve learnt about some important concepts in the process. Not only that, but I’ve implemented the PageRank algorithm in a few dozen lines of code!
You can see the full source code of my search engine app here:
I hope you’ve learnt something too. And I hope you’ve seen how easy Anvil has made this. Anvil allowed me to describe exactly how my search engine works, and show you the code.
If you’re not already an Anvil user, watch this 7-minute video to learn more. We build a database-backed multi-user web app in real-time and publish it on the internet.
Or sign up for free, and try it yourself: