 By
By I’m building a search engine using Anvil. So far, I’ve built a machine that roams the internet digesting pages, and a simple query engine. I can make some search queries, but the most important pages don’t always show up at the top of the results.
I need a way to score pages based on how important they are. I need PageRank - the secret sauce that won Google the search engine wars of the late 90s.
Let’s look at how PageRank works, then I’ll build a Python web app that implements it.
How it works
PageRank was developed in 1996 at Stanford by Sergey Brin and Larry Page, after whom it is named. It was the ‘key technical insight’ that made Google work so well, so they kept it a tightly-guarded secret.
Only kidding! Page and Brin wrote a brilliant and openly-available paper about it in 1998, which contains this priceless quote:
To test the utility of PageRank for search, we built a web search engine called Google.
The algorithm is based on the idea that important pages will get linked to more. Some terminology: if python.org links to my page, then my page has a ‘backlink’ from python.org. The number of ‘backlinks’ that a page has gives some indication of its importance.
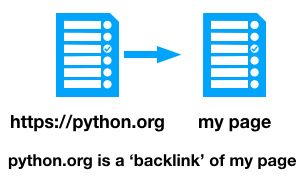
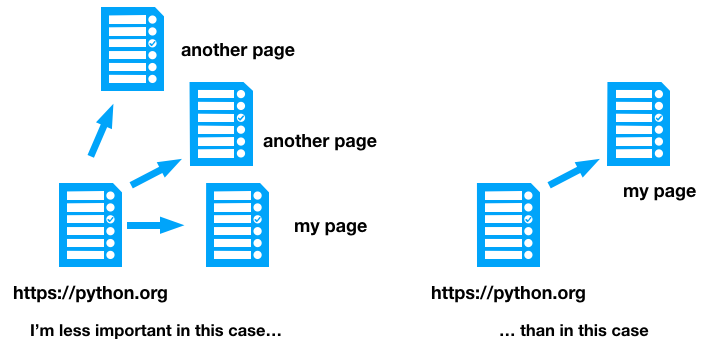
PageRank takes this one step further - backlinks from highly-ranked pages are worth more. Lots of people link to python.org, so if they link to my page, that’s a bigger endorsement than the average webpage.
If my page is the only one linked to from python.org, that’s a sign of great importance, so it should be given a reasonably high weighting. But if it’s one of fifty pages python.org links to, perhaps it’s not so significant.
An equation paints a thousand words, so for the mathematically-inclined reader, this version of the algorithm can be written:
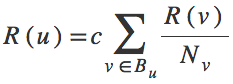
where R(u) is the rank of the page we’re ranking, R(v) is the ranking of its backlinks, Nv is the number of links page v contains, and c is a constant we can tweak at will. The sum is over all the backlinks of the page we’re ranking. (If equations aren’t your thing - this equation just re-states what I said above.)
It turns out that PageRank models exactly what a random web surfer would do. Our random surfer is equally likely to click each link on her current page, and her chance of being on this page is based on the number of pages that link to it.
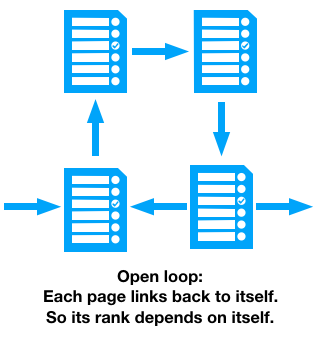
We can’t calculate this all in one go, because pages can link to each other in a loop. If the links between pages form a loop, we don’t know what rank to give them, since they all depend on each other’s rank.
We solve this by splitting the calculation into iterations. A page in iteration i + 1 has its rank worked out using the PageRanks from iteration i. So the ranks of pages in loops don’t depend on themselves, they depend on the previous iteration of themselves.
In terms of the equation from earlier, we plug the ranks from iteration i into the right-hand side of the equation, and the ranks for iteration i + 1 come out on the left-hand side.

We have to make a guess about what ranks to start with. Luckily, this is a convergent algorithm, meaning wherever we start, if we do it enough times, the ranks will eventually stop changing and we know we have something that satisfies our equation.
So that solves the problem of self-referential pages. There’s another problem with loops - if none of the pages in the loop link to a page outside of the loop, our random surfer can never escape:
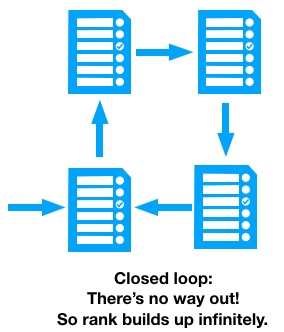
This is solved by adding an extra little bit of rank to every page, to balance out the rank that flows into dead-end loops. In our random surfer analogy, the surfer gets bored every so often and types a random URL into her browser. This changes our equation: there’s a bit of rank added, which we denote E(u):
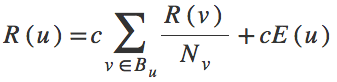
And that’s the PageRank equation!
PageRank was revolutionary. The paper compares the results from a simple PageRank-based engine against the leading search engine at the time. The top result for “University” in the PageRank engine was the Stanford University homepage. The competing engine returned “Optical Physics at the University of Oregon”.
That sounds like exactly what I need to improve my search results. Luckily, it’s fairly simple to implement if you have a relatively small number of pages. Here goes…
Implementing PageRank
First I need to calculate the backlinks for each page. My crawler has figured out the forward links from each page, so all the information is there. I just need to iterate through the pages adding ‘page X’ as a backlink on everything ‘page X’ links to.
def calculate_backlinks():
# Reset the backlinks for each page
for page in app_tables.pages.search():
page['backlinks'] = []
# We have forward links for each page - calculate the backlinks
for page in app_tables.pages.search():
if page['urls'] is None:
continue
# Add this page as a backlink to everything it links to
for url in page['urls']:
forward_linked = app_tables.pages.get(url=url.strip('/'))
if forward_linked:
forward_linked['backlinks'] += [page['url']]That’s the backlinks figured out. Now to set up the initial condition. The PageRank calculation gradually refines the answer by a series of iterations, so I must set the initial values to start off with. For newly-discovered pages, I’ll just guess at 0.5. Pages I’ve seen before will have a PageRank from previous runs, so those pages can start with that old value.
@anvil.server.background_task
def ranking_agent():
calculate_backlinks()
for page in app_tables.pages.search():
# Initial condition
if page['rank'] is None:
page['rank'] = 0.5Now for the PageRank calculation itself. I expect the calculated values of the PageRanks to converge on the correct solution. So I want to invent a metric to tell if the calculation has stopped changing much. I’ll calculate how much the average page has changed in rank, and if that’s small, my calculation has converged.
# ... still in the ranking_agent ...
# Iterate over all pages, and repeat until the average rank change is small
average_rank_change = 0.
while average_rank_change > 1.001 or average_rank_change < 0.999:
# Work out the next PageRank
new_ranks = calculate_pagerank(page)
# Step on the calculation
average_rank_change = step_calculation()Inside the loop, I calculate the PageRank for the next iteration, then
step the calculation on by putting the values from step i+1 into box i, and calculating the average rank change.
And that’s how to calculate PageRank! I’ve left out two important details. First, the actual PageRank calculation. This
is just the equation from above, but written out in Python. The CONSTANT is c and the RATING_SOURCE_FACTOR is
E(u) (I’ve assumed it’s the same value, 0.4, for each page).
CONSTANT = 0.7
RATING_SOURCE_FACTOR = 0.4
def calculate_pagerank():
"""Calculate the PageRank for the next iteration."""
new_ranks = {}
for page in app_tables.pages.search():
rank = RATING_SOURCE_FACTOR
for backlink in page['backlinks']:
backlinked_page = app_tables.pages.get(url=backlink)
rank += backlinked_page['rank'] / len(backlinked_page['forward_links'])
rank = CONSTANT * rank
new_ranks[page['url']] = rank
return new_ranksAnd for completeness, here’s exactly how I step the calculation forward:
def step_calculation():
"""Put 'next rank' into the 'current rank' box and work out average change."""
num_pages = 0.
sum_change = 0.
for page in app_tables.pages.search():
sum_change += new_ranks[page['url']] / page['rank']
page['rank'] = new_ranks[page['url']]
num_pages += 1
return sum_change / num_pagesTo make the search engine order results by PageRank, I just need to use tables.order_by in my Data Tables
query:
@anvil.server.callable
def ranked_search(query):
pages = app_tables.pages.search(
tables.order_by("rank", ascending=False),
html=q.full_text_match(query)
)
return [{"url": p['url'], "title": p['title']} for p in pages]If you want to see the code in its natural habitat, you can clone the final app, which contains everything I’ve talked about in this series of posts.
Let’s spin it up and get some ranks!
Crunch those numbers
I built a UI that tracks the progress of the calculation. It polls the Background Task using a Timer component and plots the convergence metric with each iteration. This means you can watch it run and see the calculation gradually converge in real time.
I put some test data together to check that my results make sense intuitively. Consider the four pages (and links) shown in the diagram below:
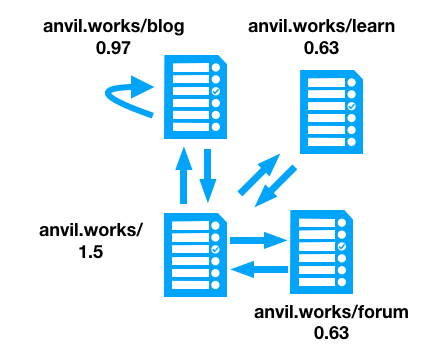
The PageRank for each page is also shown in the diagram, as calculated by my ranking
engine. The page with 3 backlinks has a PageRank of 1.5, the page with 2 backlinks has a PageRank of 0.97, and the pages
with 1 backlink each from the same page have rankings of 0.63. This sounds about right. I can tune the spread of these
numbers by changing CONSTANT in my code.
Test queries
In Part 1, I tested the basic version of the search engine by running three queries and making judgements about the quality of the results.
Let’s run the same queries again to see how PageRank has improved things.
‘Plots’
‘Plots’ is my example of a fairly generic word that appears a lot in technical writing. There are a few pages that are specifically about plots in Anvil, and I want to see whether they come up.
Overall, the PageRank search seems to do better. Five of the results are specifically about plotting:
The basic search only manages to get three of these into the top ten.
The basic search also included some pages from the middle of the blog. These have been ranked lower by PageRank, so the more-relevant pages have had a fighting chance.
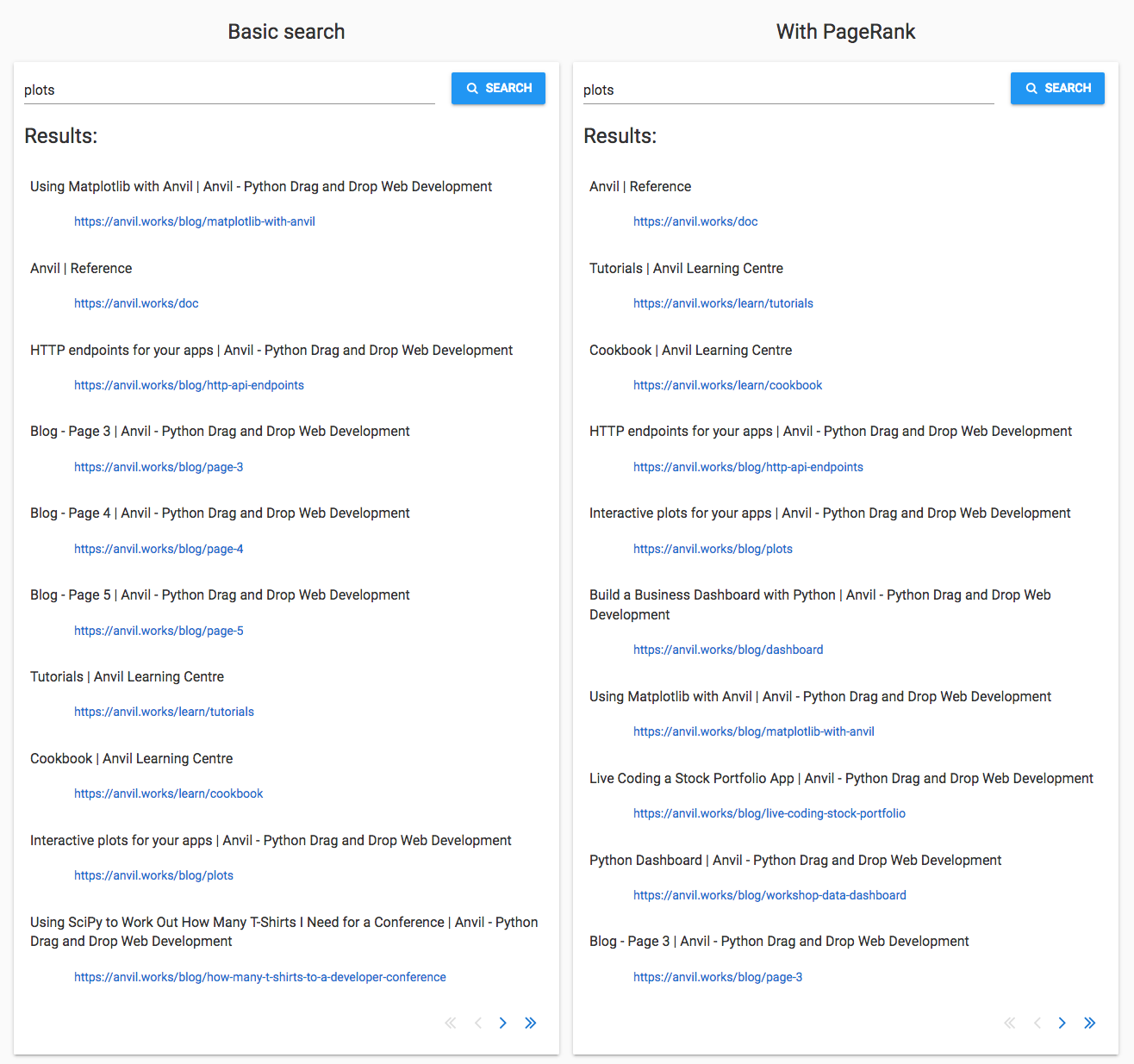
The PageRank search does worse in one respect - the top spot has been taken by the reference docs, replacing the Using Matplotlib with Anvil guide. I’m ranking pages purely based on importance and not on relevance. The reference documentation is clearly ‘more important’ overall than the Matplotlib guide - but not more relevant to a search for ‘plots’.
‘Uplink’
I’m using ‘Uplink’ as an example of a word that’s not likely to be used accidentally - it’s not commonly
used in normal speech, so any uses of it are probably about the Anvil Uplink. If you’re not familiar with it, the Uplink allows you to anvil.server.call functions in any Python environment outside Anvil.
There are three relevant pages in the basic search results, and they appear in the PageRank results too. They are Using Code Outside Anvil, Escape Hatches and Ejector Seats and Remote Control Panel. Sadly, these pages have lost position to more ‘major’ pages, the tutorials and reference docs.
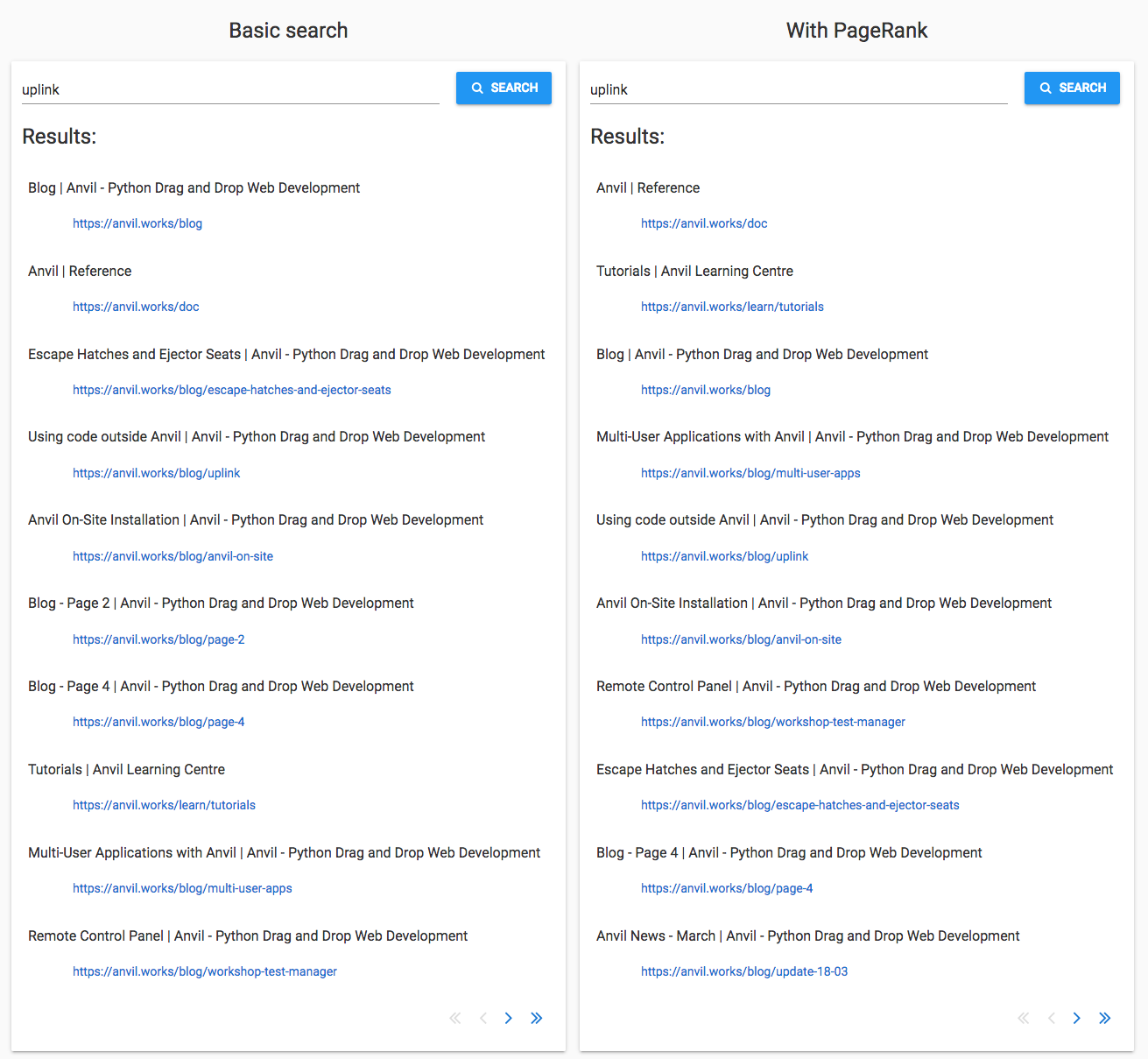
The basic search just presents pages in the order it crawled them, so the ranking is ‘more random’ than the PageRank’s importance-based ordering. It looks like the PageRank search is doing worse than chance in this case, because it’s placing pages that have more backlinks at the top regardless of relevance.
We’ve learnt something - even something as powerful as PageRank can be counterproductive in some circumstances.
‘Building a dashboard in Python’
A query with multiple words is harder because it’s difficult to work out which words are the subject of the query, and which words are incidental. I’m using ‘building a dashboard in Python’ to test this. This tripped up the basic search because of the noise introduced by the words ‘building’ and ‘Python’, which are very common on the Anvil site.
The PageRank search did slightly better. The basic search missed Building a Business Dashboard in Python and the Python Dashboard workshop, but they appear in the PageRank search. Again, some minor pages such as page 6 of the blog are now ranked lower, making room for these better-matching pages.
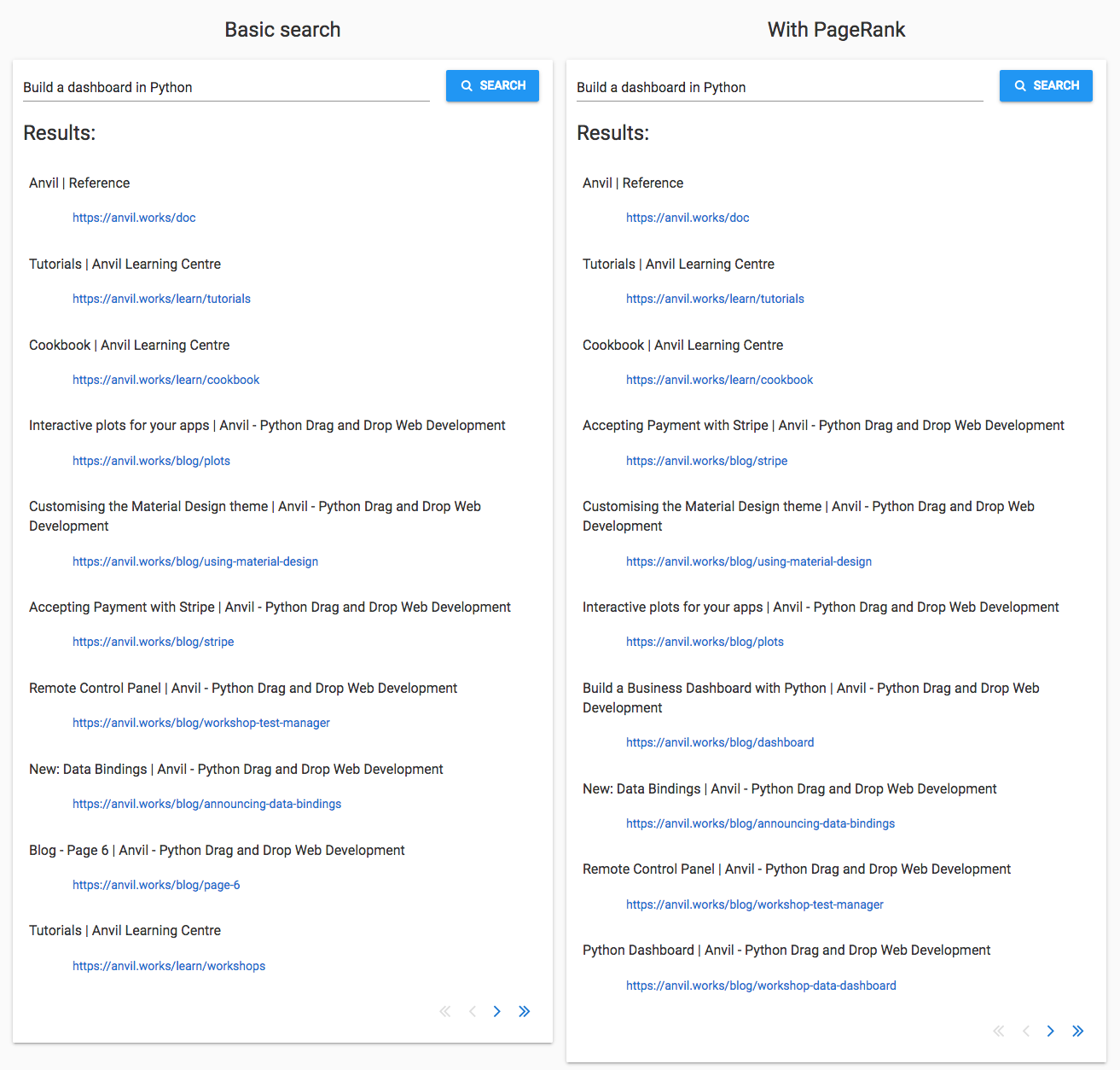
That said, PageRank has put Interactive Plots for Your Apps lower and Accepting Payment with Stripe higher. As with the ‘Uplink’ query, the ranking system does not take page content into account, so sometimes the ‘more random’ ranking of the basic search happens to do better.
So how did it do?
The PageRank search de-ranked pages 2 to 6 of the blog, because they don’t have many backlinks. This made room for other matching pages. Sometimes those pages were good matches, sometimes they were not.
It favoured the main pages such as ‘Tutorials’ and ‘Documentation’ above pages that deal with specific subjects. Older pages were also favoured because pages gradually acquire backlinks over time.
PageRank is much more powerful when used to choose between sites, rather than pages on the same site. A single site is a curated system where there are only a small number of relevant results. The web is an unmanaged jungle where there will be many sites on the same topic, and PageRank is a great way to decide which sites are better than others.
So it’s made things better, but I still need to do more.
Next time: Tokenization and indexing
I need to relate the search rankings to the contents of the page. I’ll take advantage of two trusty Computer Science workhorses: tokenization and indexing.
Once I’ve done that, I think my search engine will be good enough to show to the public!
Read about it here:
Or sign up for free, and open our search engine app in the Anvil editor: