 By
By How many T-Shirts do I take to PyCon?
When you’re marketing to developers, you go where the developers are. We make a platform for building full-stack web apps with nothing but Python, so we go to developer conferences – particularly Python ones.
Like many sponsors, we give out nifty Anvil-branded T-shirts. But there’s a twist: in order to earn a T-shirt, you’ve got to build something with Anvil. So far, it’s gone pretty well - here’s what it looked like at EuroPython last week:

Now we’re home, and preparing for PyCon UK in September, it’s time to order more shirts. The trouble is, developers come in all shapes and sizes, and the first time we ordered we were way off the mark. (Apologies to the huge number of people who wanted a Women’s Small!)
This time, we can be smarter. We’re a bootstrapped company, so we can’t just blow VC cash on unnecessary mountains of shirts – but we do want every Anvil user to go home with a T-shirt.
How can we use this data to work out how many shirts we need?
Option 1: Exact numbers.
“If last conference used 13 Men’s Medium shirts, we should bring exactly 13 to the next conference.”
This is obviously a bad idea. If even one more medium-sized man writes an app with Anvil, we’re going to run out of shirts. And feel pretty stupid about it, too.
Option 2: Double up
OK, fine, so let’s order 200% of what we expect to need. This will cause us to order 4 rather than 2 Women’s XS (probably sensible)…and 54 rather than 27 Men’s Large (not so much!). That 54th Men’s Large shirt is much less likely to be claimed than the 4th Women’s XS shirt is. It’s the law of large numbers: Larger samples average out more reliably.
Wait. I’m sure there’s a more helpful way of thinking about this than waving my hands and saying “law of large numbers”. Can we capture this insight in a statistical model?
Option 3: Be a bit smarter
Let’s imagine that every person who comes to the conference is a dice-roll. Some percentage of the time, they build an Anvil app and claim their T-shirt. What size they want is also a dice-roll: X% of the time they want a women’s Medium; Y% of the time they want a men’s Small; and so on. We can estimate how big X and Y are, because we know how many shirts we gave out at PyCon US and EuroPython, and we know how many attendees were at those conferences.
Next month, we’re sponsoring PyCon UK, with 700 attendees. How many men’s Medium-size shirts will we need? We can simulate it by rolling that die 700 times, and counting how many times it comes up “men’s Medium”.
Of course, each time we do that “roll 700 dice” procedure, we could get a different total count. This total follows a binomial distribution:
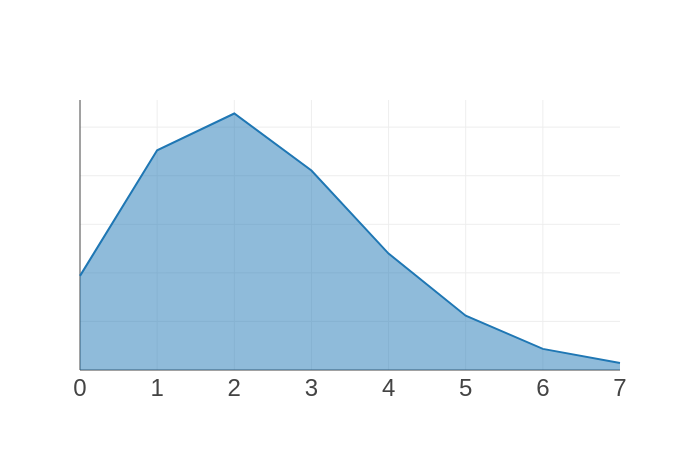
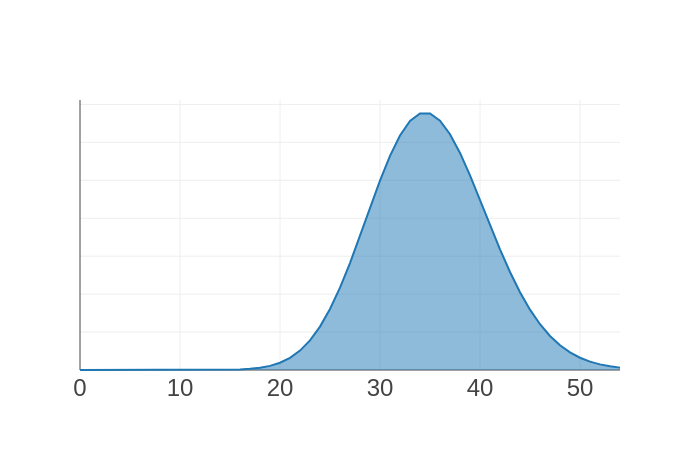
Here I’ve plotted two binomial distributions, using Anvil’s plotting tools. On the left, we’re expecting to give away about 2 shirts, but we could easily need twice that number. On the right, we’re expecting 35, but we’re unlikely to need more than 40 – we’re much more certain with larger numbers. This is the insight we had before – but now we’ve got a model, we can quantify it!
We can wrangle binomial distributions easily with SciPy. We’ll use SciPy’s ppf function to get the 95th centile of this distribution: If our model is correct, there’s a 95% probability we won’t need more shirts than this.
Let’s compute that number:
from scipy.stats import binom
# From 1500 attendees, we gave away 13 men’s Medium shirts
p_mens_medium = 13 / 1500
# For 700 attendees, there’s a 95% chance we will need no
# more than this many men's Medium shirts:
n_shirts_p95 = binom.ppf(0.95, 700, p_mens_medium)
print(n_shirts_p95)=> 10.0So we need to take 10 men’s Medium-size shirts to Cardiff!
Building a T-shirt calculator
Now we have some Python code, we can put a web interface on it really quickly with Anvil. I built a T-shirt calculator that can do this calculation for many sizes of shirt at once. You can use it below, or open the source code in Anvil to see how it works:
Feel free to use and share this app. And if you’re going to a developer conference soon, perhaps we’ll see you there!