 By
By Background Tasks
This tutorial assumes some basic knowledge of Anvil. If you want to understand all the details, it might help to have built something in Anvil already - try following the Feedback Form tutorial first.
When you’re done there, come back here to learn about Background Tasks.
We’re going to look at Background Tasks by building a web crawler that downloads all the pages on a site. The final result is a very simple search engine.
Launching a Background Task
Let’s write a minimal Background Task to start with, and fill in the long-running code it will contain later.
Define a function called crawl in a Server Module. For now, it will just take in a URL and print it back to you.
@anvil.server.background_task
def crawl(sitemap_url):
print('Crawling: ' + sitemap_url)Decorating it with @anvil.server.background_task tells Anvil this can be run in the background.
Tasks are launched by calling anvil.server.launch_background_task from a server function. This works just like anvil.server.call - the first argument is the function name, and all other arguments are passed to the function. It returns a Task object, which the app can use to access data from the Background Task.
Write a server function to launch the crawl task:
@anvil.server.callable
def launch_one_crawler(sitemap_url):
"""Launch a single crawler background task."""
task = anvil.server.launch_background_task('crawl', sitemap_url)
return taskWe’re going to have a Button that launches this Background Task.
Drop a Label, a TextBox and a Button into Form1:
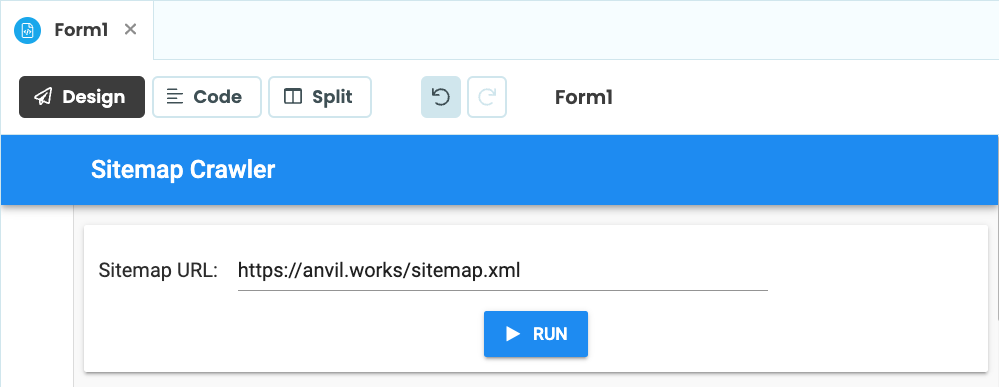
Form1 with a Label, a TextBox and a button.
Now configure the Button’s click handler to launch the Background Task and store the Task object:
def button_run_click(self, **event_args):
"""This method is called when the button is clicked"""
self.task = anvil.server.call('launch_one_crawler', self.text_box_sitemap.text)(Remember to bind this method to the Button’s click event by double-clicking on the Button or using the Properties panel.)
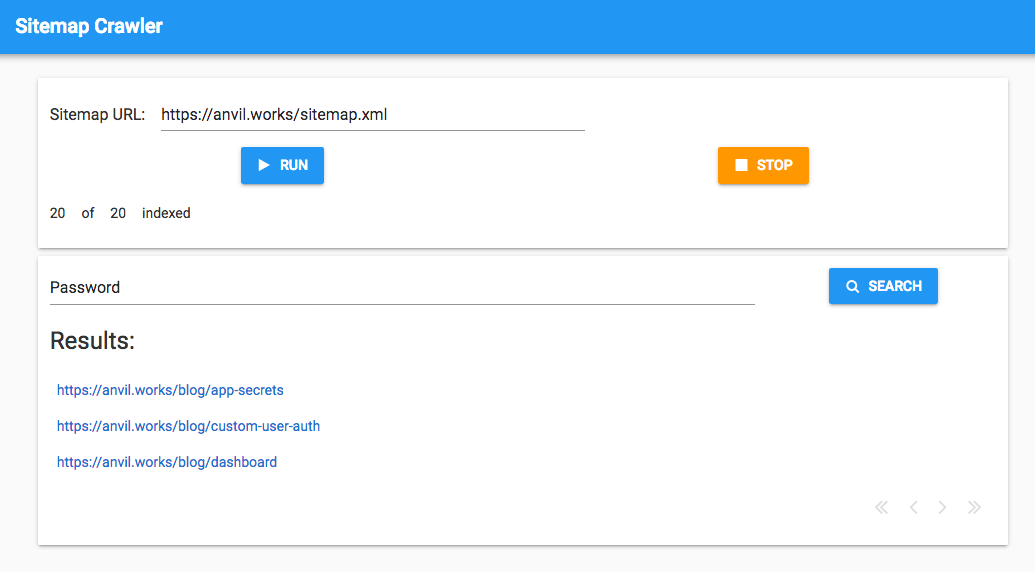
Run the app and click the Button - a Background Task has been launched! But how can you tell?
Viewing your tasks and their logs
So your tasks are being launched, but since they’re in the background, how do you see what they’re doing?
Answer: The Background Tasks dialog, which can be found by opening the app’s Logs ![]() in the Sidebar Menu. Then select
in the Sidebar Menu. Then select background Tasks. the Gear menu. Running tasks will also appear in the Background Tasks Output window when you are developing your app, allowing you to keep track of them easily.
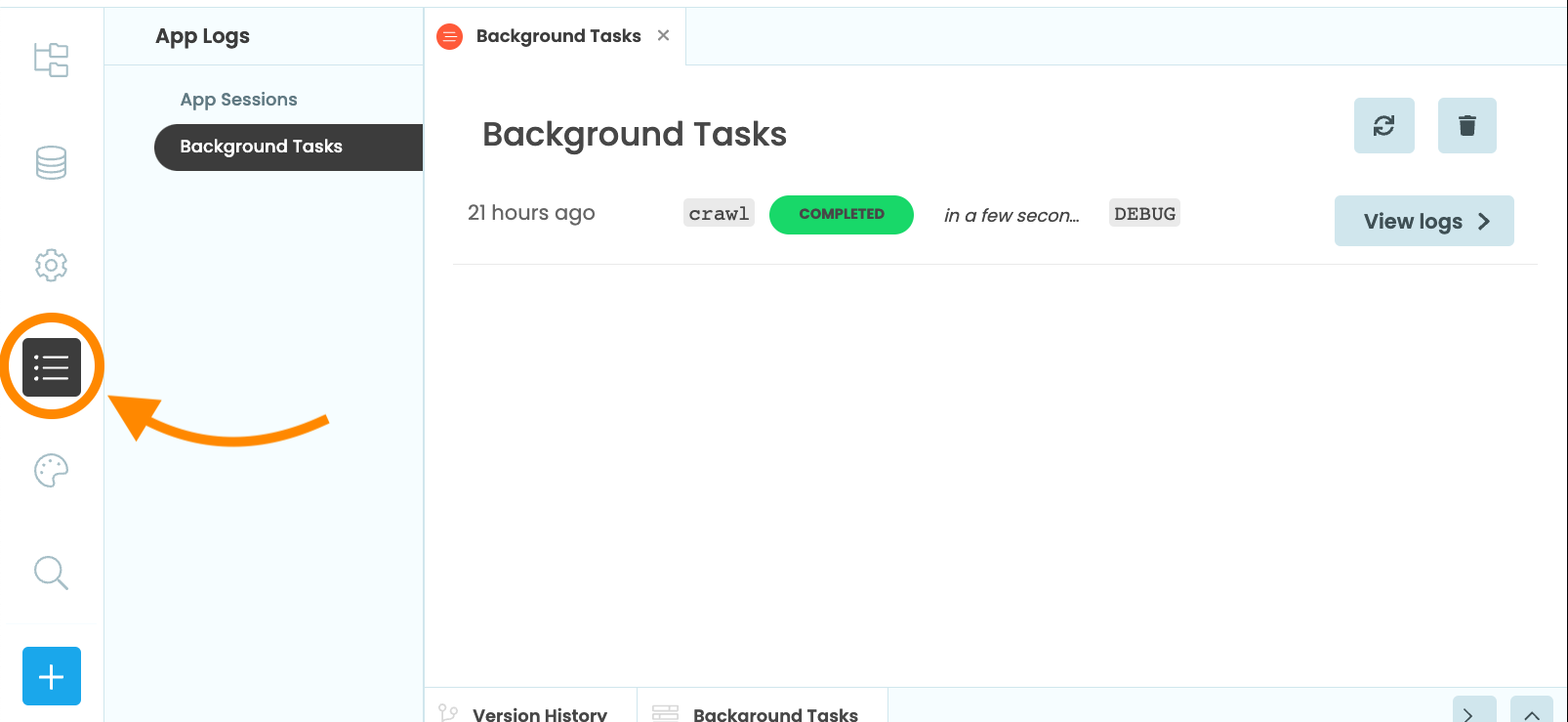
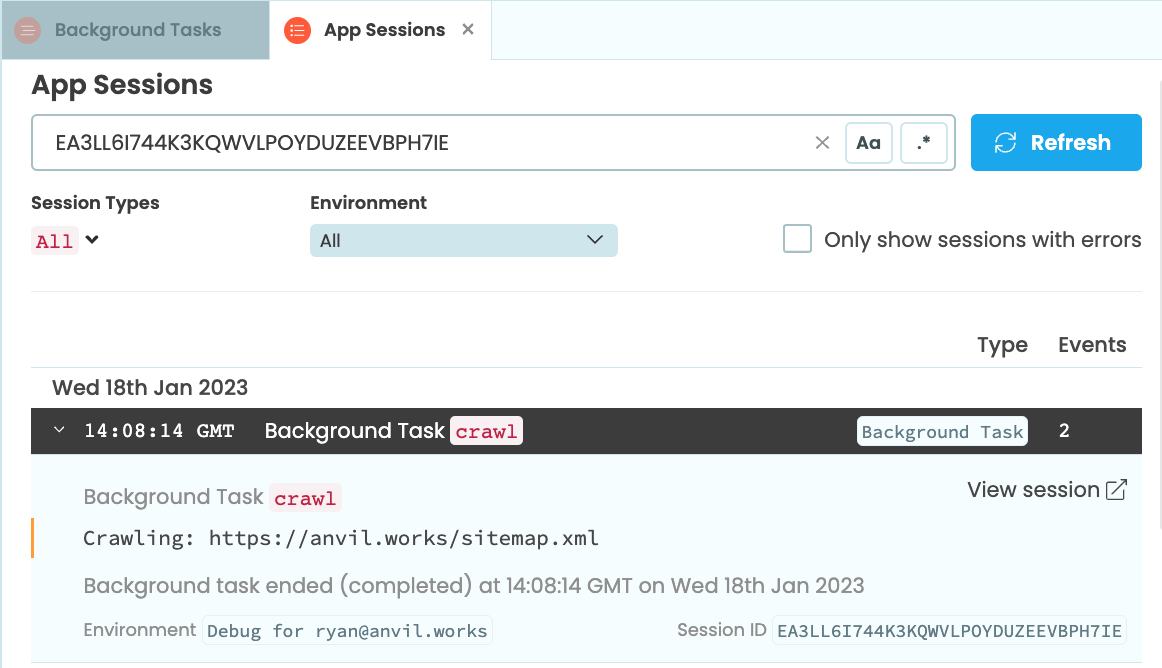
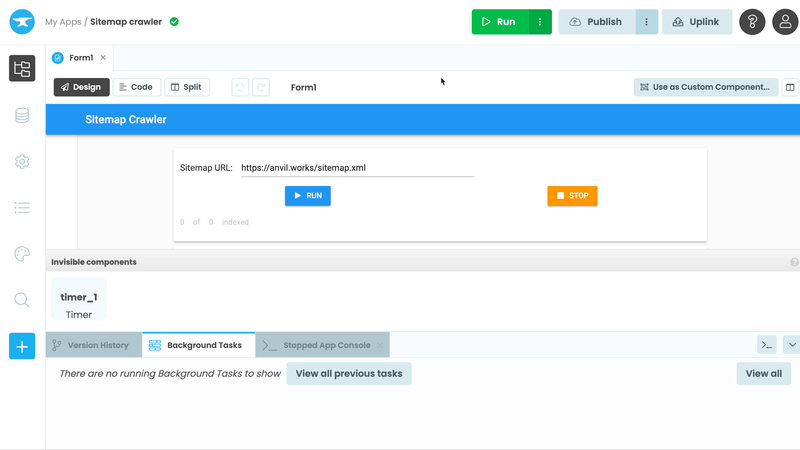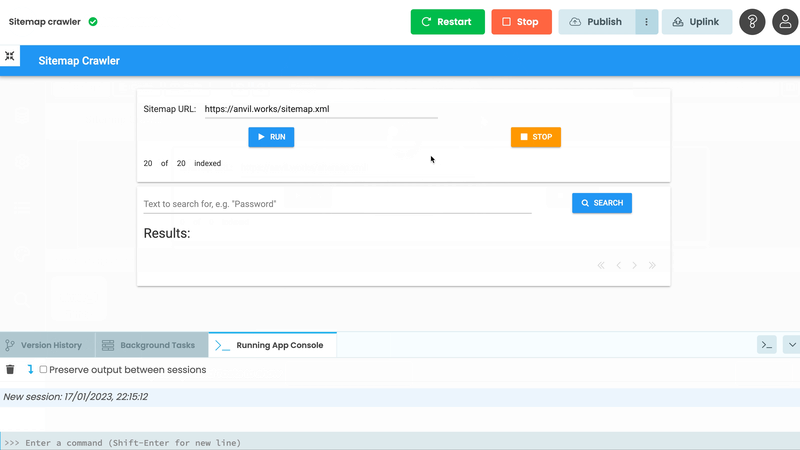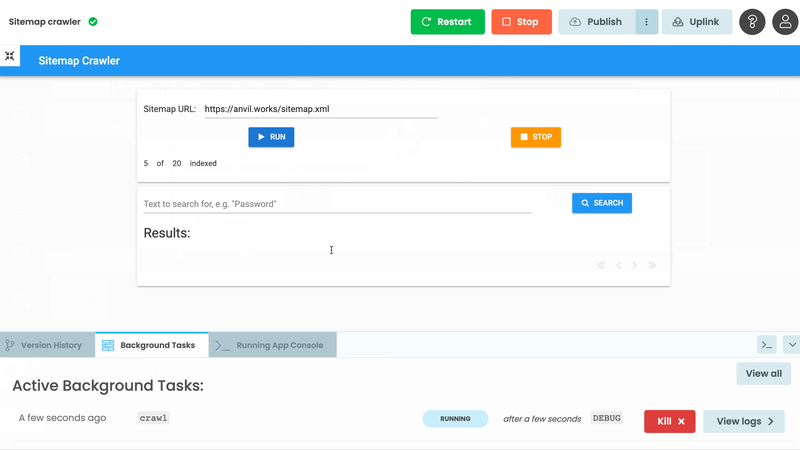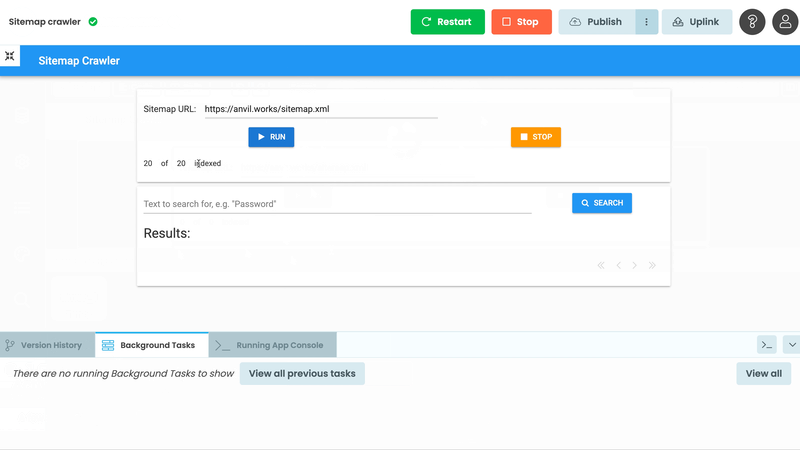
The Background Tasks dialog lists all the tasks that the app has run along with their status. In our case, we see one task that has completed a few seconds ago, and it ran for a few seconds. If it were still running, we’d have a button to kill it.
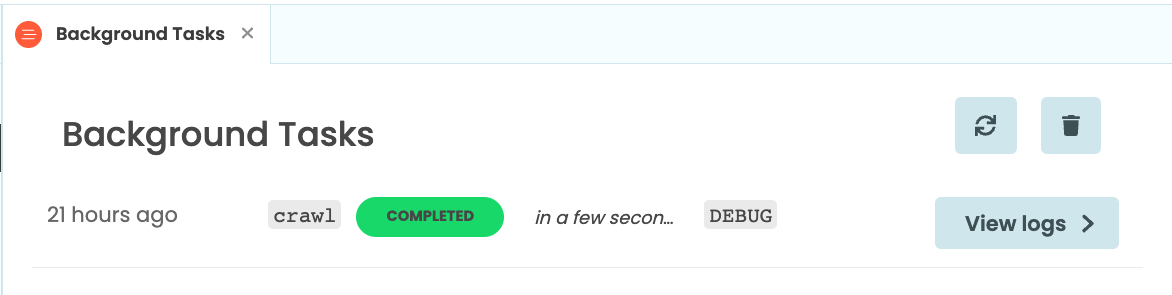
The ‘View logs’ button next to each task takes you to the App Logs entry for this task. There is one entry for each Background Task - all the logs from a particular task are grouped together.
In our app, we see that our task printed Crawling: https://anvil.works/sitemap.xml before finishing. If the task had raised an exception, that would appear here too.
That’s all very well, but we want to build a web crawler, so let’s make it do some crawling!
Making the task harvest pages
Time to make the task do something useful.
First, we’ll request the sitemap and get a list of the pages. Pages are stored as strings between <loc> tags, so we need to look at each line and cut out the bit between the <loc> tags:
@anvil.server.background_task
def crawl(sitemap_url):
# ... the code we wrote before, then ...
# Get the contents of the sitemap
response = anvil.http.request(sitemap_url)
sitemap = response.get_bytes().decode(“utf-8”)
# Parse out the URLs
urls = []
for line in sitemap.split('\n'):
if '<loc>' in line:
urls.append(line.split('<loc>')[1].split('</loc>')[0])Now urls will be a list of URLs to pages on the Anvil site.
Import anvil.http at the top of your modile, and write a function to request each page:
def get_pages(urls):
for n, url in enumerate(urls):
url = url.rstrip('/')
# Get the page
try:
print("Requesting URL " + url)
response = anvil.http.request(url)
except:
# If the fetch failed, just try the other URLs
continueCreate a Data Table to store the url and html of each page, and when it was last_indexed. See the Data Tables documentation if you’re not familiar with Data Tables for a more detailed explanation of how to do this.
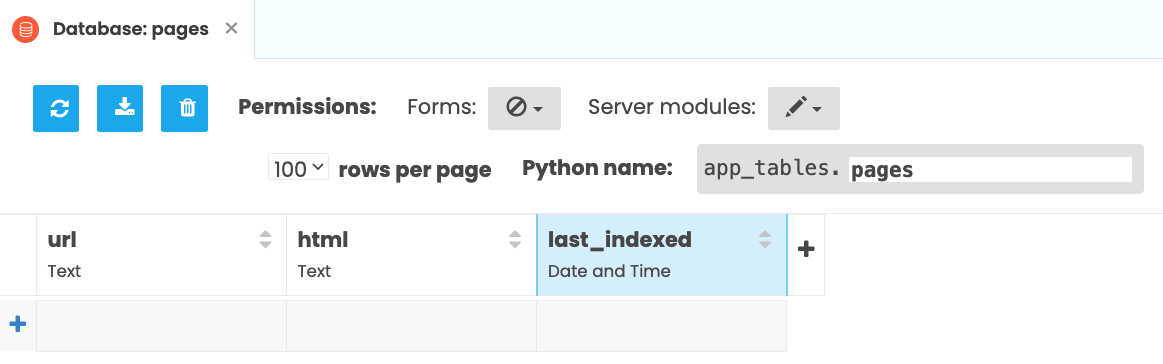
Now write a function to populate the table. It takes the URL and HTML as arguments:
from datetime import datetime
def store_page(url, html):
# Find the Data Tables row, or add one
with anvil.tables.Transaction() as txn:
data = app_tables.pages.get(url=url) or app_tables.pages.add_row(url=url)
# Update the data in the Data Tables
data['html'] = html
data['last_indexed'] = datetime.now()Call this at the end of get_pages:
def get_pages(urls):
for n, url in enumerate(urls):
# ... the code we wrote before, then ...
html = response.get_bytes()
store_page(url, html)Finally, call get_pages at the end of crawl, and everything will be ready to go:
@anvil.server.background_task
def crawl(sitemap_url):
# ... the code we wrote before, then ...
get_pages(urls[:20])Run the app and click the ‘Run’ Button. Crawling begins behind the scenes.
Now, quit the app. Your Background Task is still harvesting web pages!
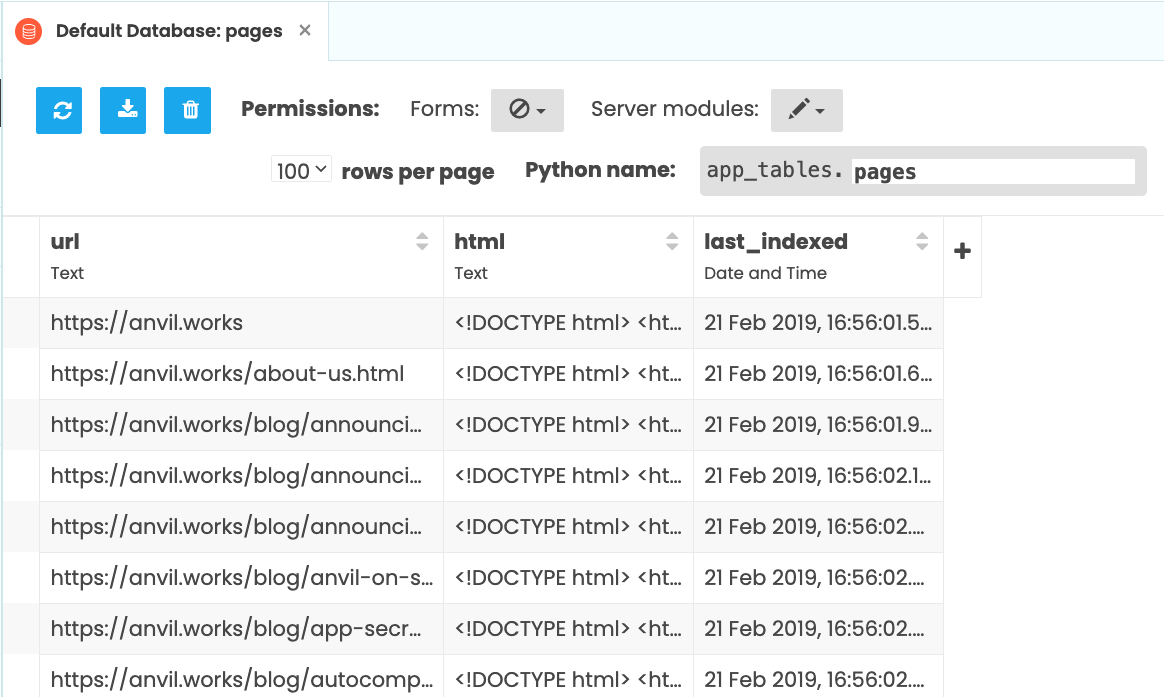
Check your Data Table to see it filling up with web pages (there’s a refresh button on the Data Tables UI, so click that a few times to watch more arrive).
The task you’ve just run will be visible in the Background Tasks dialog:
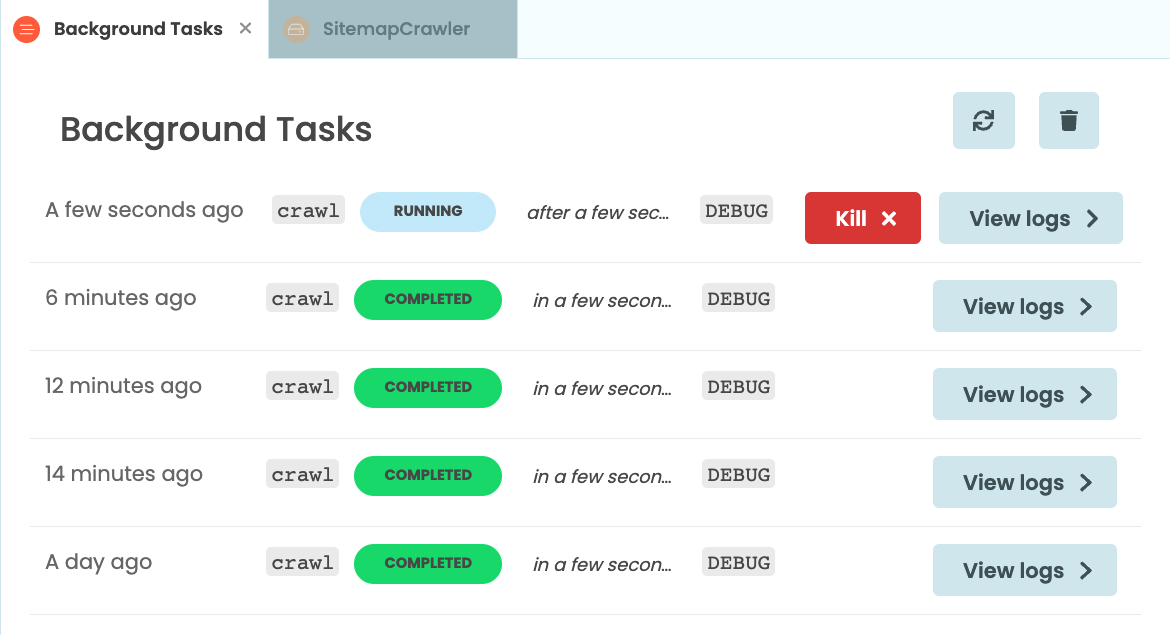
and in the App Logs you can see it printing a line every time it requests a page:
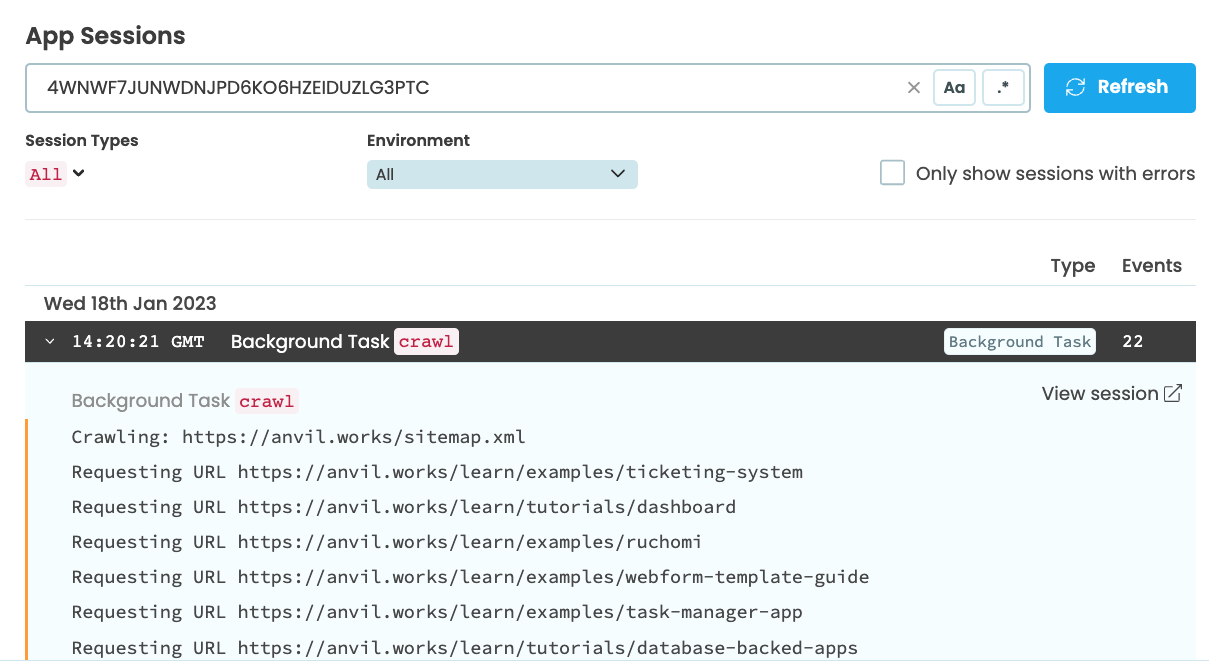
Having the task running in the background is great, but we need to get some information out of it. First, we’ll search the pages it’s storing. Then, we’ll display the crawling process in the UI in real time.
Search the results
Let’s build a simple search widget - add a Button, TextBox and Data Grid to the page.
Set the Data Grid to have a single column whose key is url, and uncheck the box for the auto_header property (see our Data Grids tutorial for more information):
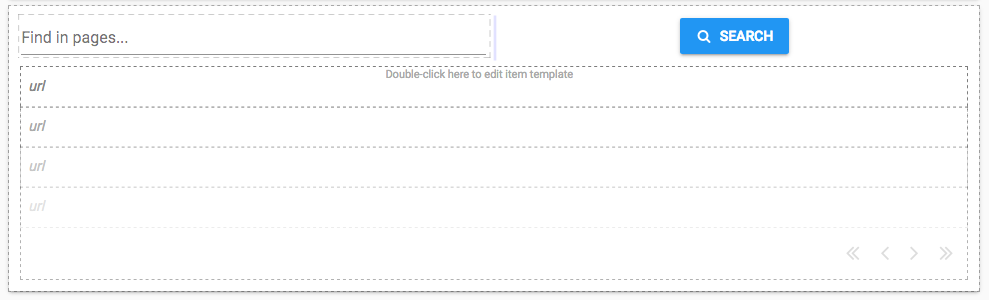
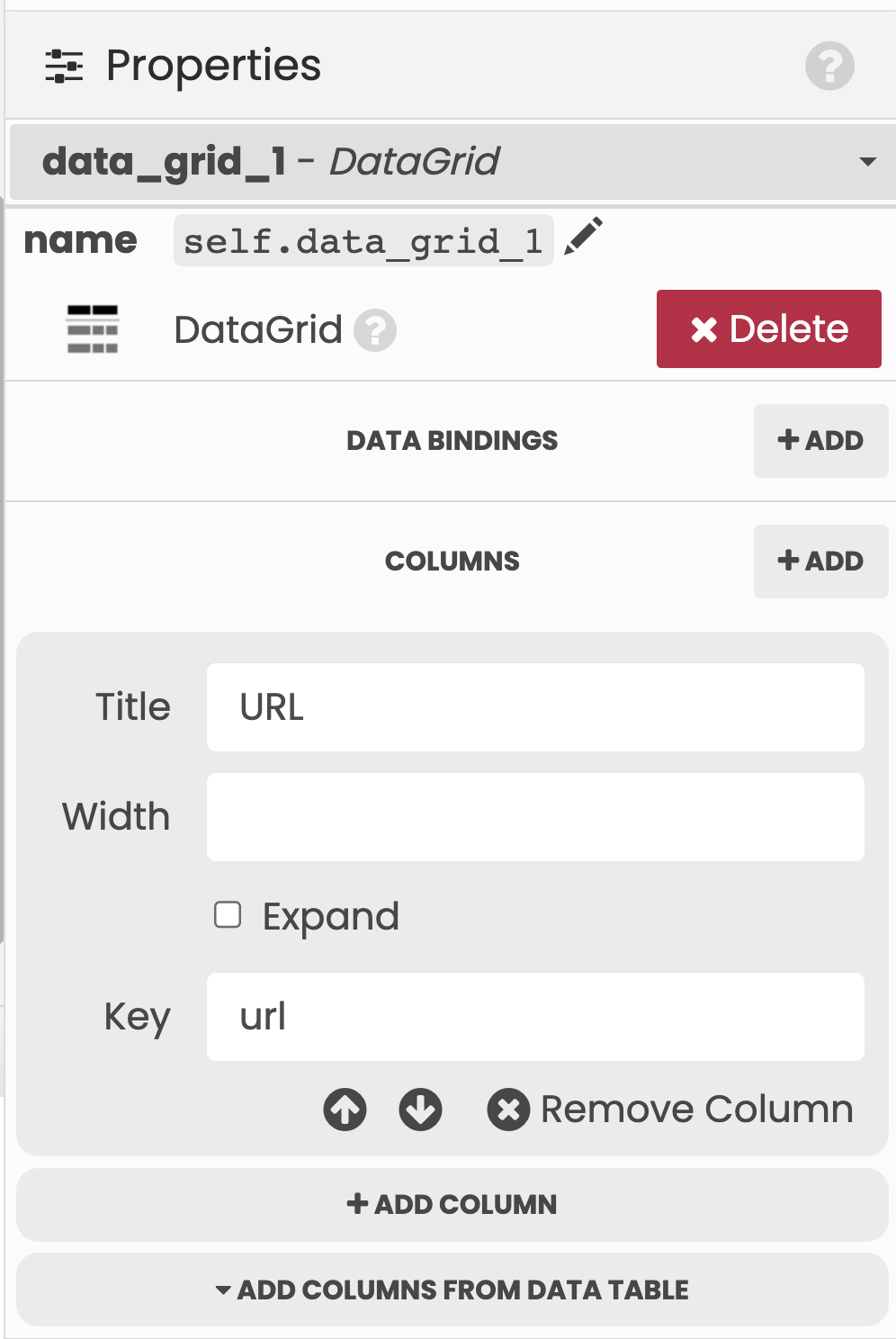
When the Button is clicked, we want to update the Data Grid based on the results in the Data Table.
So write a simple server function to get the data from the Data Table. For speed, we use Anvil’s full-text search capability, then return only the page URLs to the client:
@anvil.server.callable
def search(query):
pages = app_tables.pages.search(html=q.full_text_match(query))
return [{"url": p['url']} for p in pages]Now double-click on the ‘Search’ Button to automatically create a click event handler and call the server-side search function inside it:
def button_search_click(self, **event_args):
"""This method is called when the button is clicked"""
query = self.text_box_search.text
self.repeating_panel_1.items = anvil.server.call('search', query)Now the user can search within all the pages on the Anvil site to find a particular string - try it out!
(Optional extra: In our example app, we’ve used Links in the Data Grid to link to the URL of the page.)

So we can communicate from our Background Task via a persistent data store such as Data Tables, but what if we want to do something more lightweight to communicate about the task’s state?
Track the crawling process in real-time
The other way we can get data from the Background Task is by using anvil.server.task_state. This is a special object that allows the Background Task function to store data about itself. By default, it’s a dictionary, so you can assign things to its keys. Let’s first store the total number of URLs we’re crawling:
def get_pages(urls):
anvil.server.task_state['total_urls'] = len(urls)
# ... then the rest of get_pages ...Now let’s add a loop inside to store the number of URLs processed so far:
def get_pages(urls):
anvil.server.task_state['total_urls'] = len(urls)
for n, url in enumerate(urls):
# ... after the processing is done ...
anvil.server.task_state['n_complete'] = n + 1Now to display that progress to the user. Put a new FlowPanel inside Form1 and inside that, add some Labels to show the number of pages indexed. Set the FlowPanel’s visible property to False - we’ll only show it when it’s relevant. Add a Timer as well, which can be found under ‘More Components’ in the ToolBox.
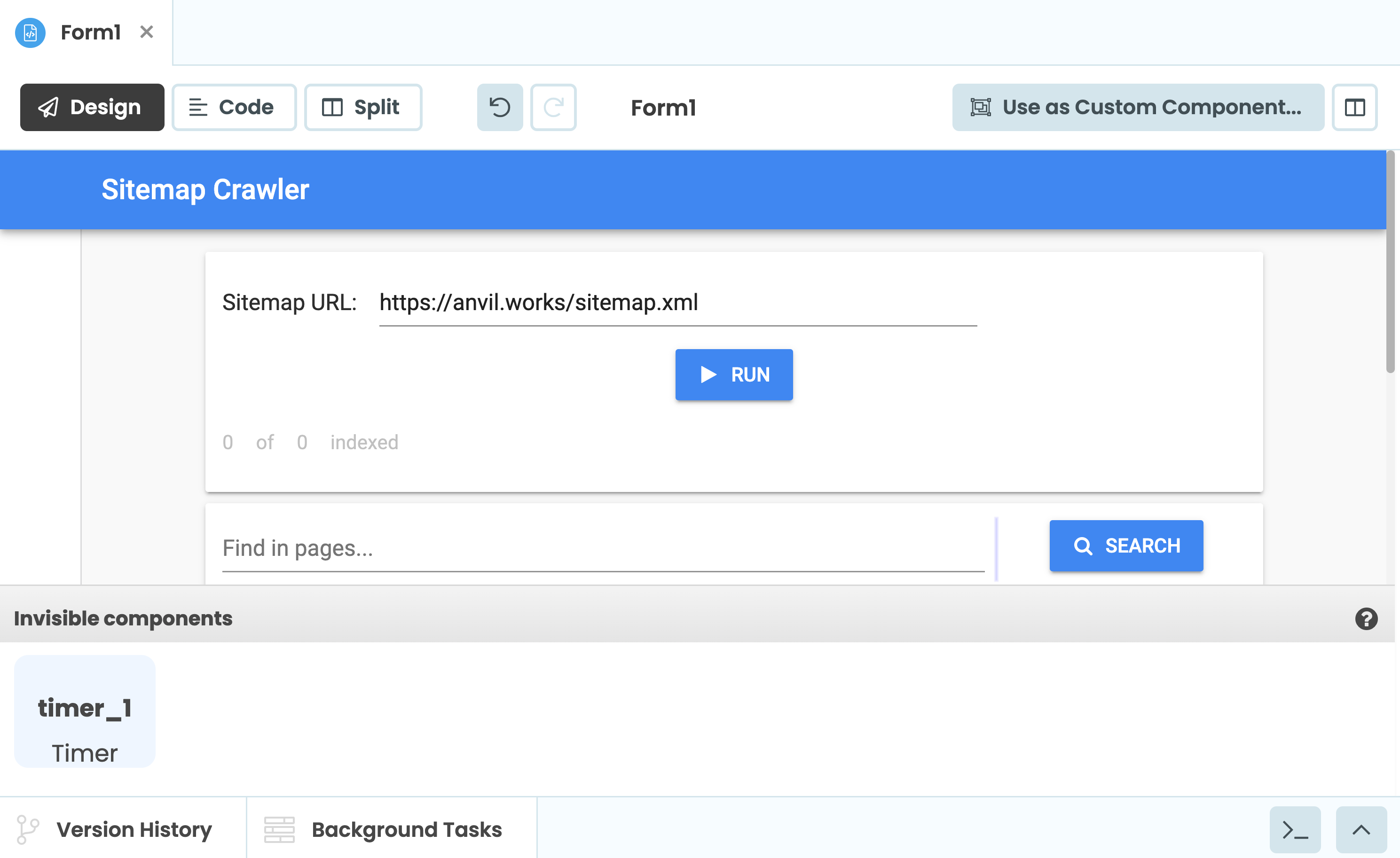
Set the Timer’s interval property to 0 - this means the Timer does nothing at first. When the ‘Run’ button is clicked, we want the Timer to start ticking, so in the code, set its interval to 0.5 and show the FlowPanel:
def button_run_click(self, **event_args):
"""This method is called when the button is clicked"""
self.timer_1.interval = 0.5
self.flow_panel_1.visible = True
# ... and the rest of the click handler as before ...We want to update our progress labels whenever the timer ticks. We’ll explain how to do that, then show you the full tick event handler.
First it must get hold of the task_state that our Background Task has been writing to. When we launched the task, we stored an object in self.task that allows us to get its task_state:
state = self.task.get_state()We want the task state’s n_complete and total_urls values. Since it’s a dictionary, it has the get method, which we can use to default to 0 if those keys aren’t present:
n_complete, total_urls = state.get('n_complete', 0), state.get('total_urls', 0)Then we simply assign those values to the relevant Labels:
self.label_num_crawled.text = n_complete
self.label_total_pages.text = total_urlsFinally, we check whether the Background Task is still running. If it isn’t, we switch the Timer off:
# Switch Timer off if process is complete
if not self.task.is_running():
self.timer_1.interval = 0The full event handler is shown below. Double-click the Timer component in the Design view to
bind a tick event handler, and write this method.
def timer_1_tick(self, **event_args):
"""This method is called Every [interval] seconds. Does not trigger if [interval] is 0."""
# Hide the loading spinner so the user is not interrupted by the polling
with anvil.server.no_loading_indicator:
# Show progress
state = self.task.get_state()
n_complete, total_urls = state.get('n_complete', 0), state.get('total_urls', 0)
self.label_num_crawled.text = n_complete
self.label_total_pages.text = total_urls
# Switch Timer off if process is not running
if not self.task.is_running():
self.timer_1.interval = 0Note that we’ve used not self.task.is_running() here rather than self.task.is_completed(). The latter only returns True if the task completed successfully, but the task might also stop running if it is failed, missing or killed.
And that’s it! Now we have a progress tracker that tells us how many pages we’ve crawled, in real time:
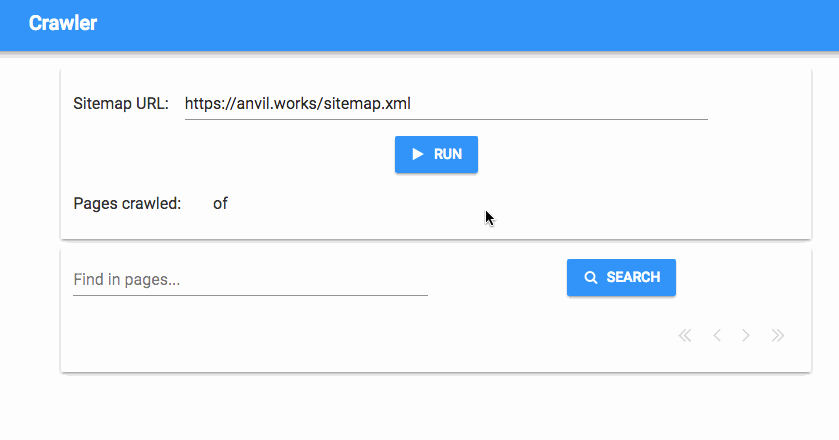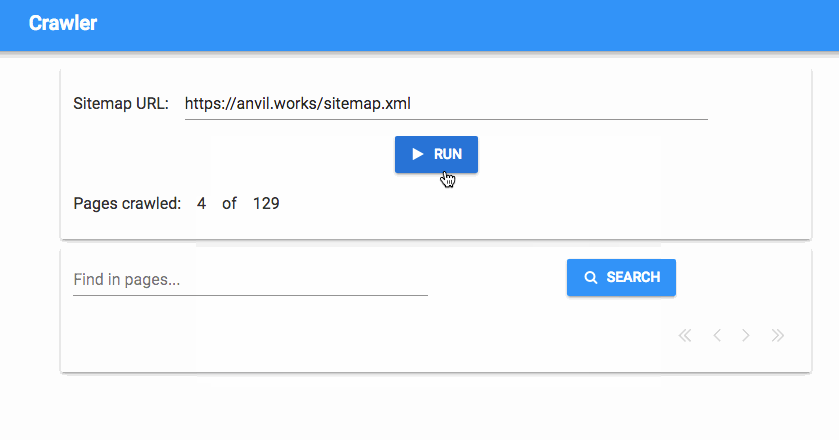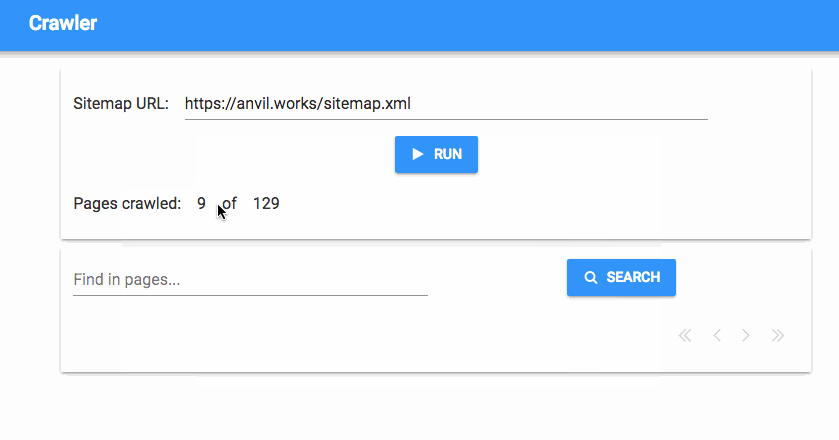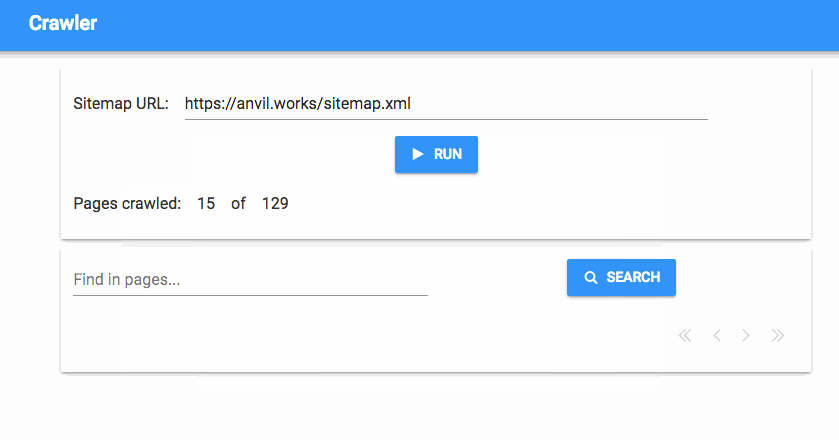
We’ve got a fully working simple search engine now, but we’d like to have a bit more control - how do we stop the crawl process once it’s started?
Killing the Background Task before it is finished
What if we decide we’ve crawled enough pages and we want to stop the Background Task before it has crawled everything? As the developer, we can use the Kill button in the Background Tasks dialog. But how do we give the user the ability to kill tasks?
The Task object has a kill method for this. When kill is called, the Background Task stops running and its state goes to killed. The client doesn’t have access to the kill method for security reasons, so we write a very simple server function to kill a given task. In a production app, you should make sure that the caller of this function is authorised to kill the task (perhaps using Anvil’s built-in Users Service), but for our example this will do:
@anvil.server.callable
def kill_crawler(task):
task.kill()Add a Button to your form to use as a ‘stop’ button. To make the Stop button work, pass the Task object through from the client when the Stop button is clicked:
def button_stop_click(self, **event_args):
"""This method is called when the button is clicked"""
anvil.server.call('kill_crawler', self.task)Now we can hit this button to stop the crawling process. That should prove useful if a site turns out to be much bigger than we thought!
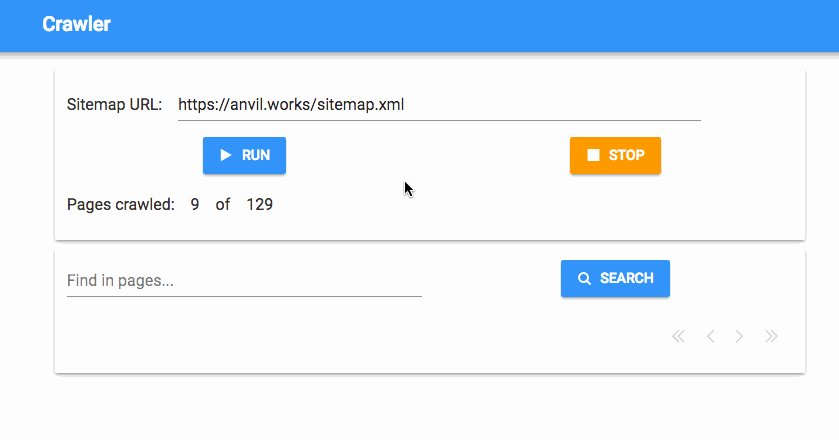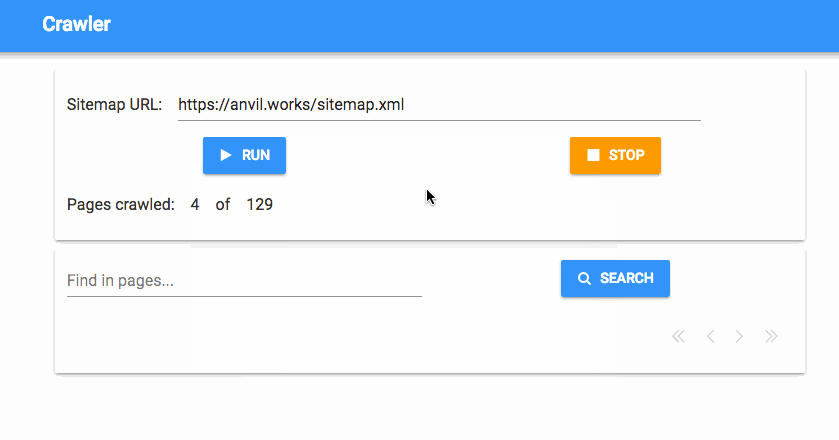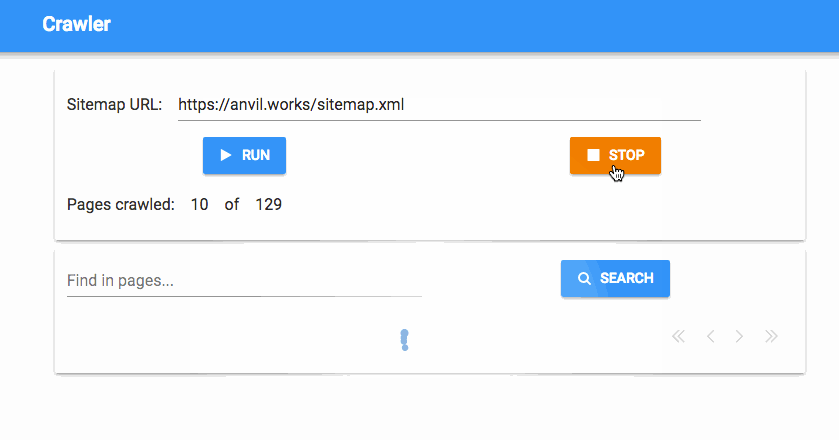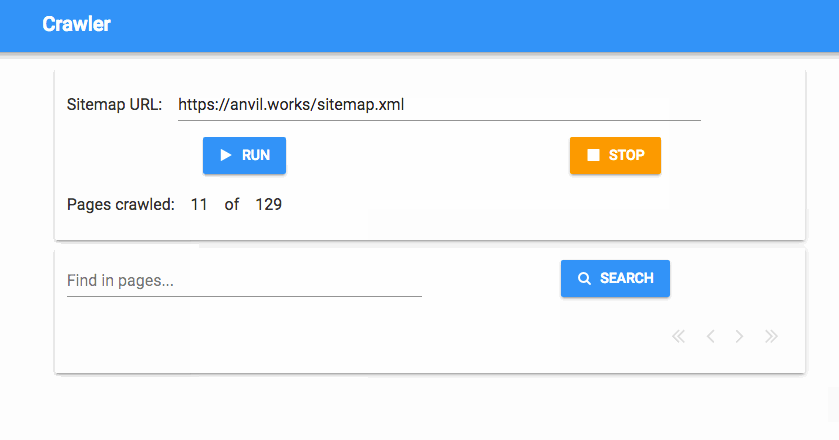
Check if anything’s running when the app starts
If you momentarily close the app and re-open it, it loses track of the crawl progress. It would be nice if it picked up the latest Background Task and showed you the progress. Luckily, you can connect to existing Background Tasks from previous runs of your app.
In a Server Module, call anvil.server.list_background_tasks():
@anvil.server.callable
def get_existing_tasks():
return anvil.server.list_background_tasks()This returns a list of Task objects. The Task object has a method to get the name of the task -
this is usually the name of the relevant server function. Modify that line to filter out crawl tasks in case other task types get added:
@anvil.server.callable
def get_existing_tasks():
return [
t for t in anvil.server.list_background_tasks() if t.get_task_name() == 'crawl'
]Call this in Form1’s __init__ method. If there are any existing tasks, keep track of the latest one and turn on the progress display (we could use task.get_start_time() to figure out which Task is the newest, but tasks is ordered by start time so we’ve used tasks[-1]).
def __init__(self, **properties):
# ... the existing code, then ...
tasks = anvil.server.call('get_existing_tasks')
if len(tasks) > 0:
# Keep track of the latest task
self.task = tasks[-1]
# Turn on the progress display
self.timer_1.interval = 0.5
self.flow_panel_1.visible = TrueYour app will now find any existing Background Tasks when it starts up!
Taking it further
So now we can crawl a website using its sitemap, download the whole site to a Data Table, and search within it to find all the pages that contain a particular string.
Clone our final version of the app, then see how yours compares:
Having read this far, you’ve seen everything you need to launch and manage Background Tasks. You’re ready to start using them in your apps! Perhaps you need to perform a database migration, download a large file, or keep a message list below a certain length.
Check out the reference docs entry when you need to refresh your memory.
Here are some tutorials exploring features your Background Tasks might use:
- Using an external database
- Integrating with an external HTTP API
- Sending and receiving email
- Connecting to Python running anywhere
Happy building!