By
By A tour of Python’s memory magic
Python is a wonderful thing that takes all the complication of memory management away from us. We don’t have to worry about pre-allocating memory for our objects, or remember to free it once we’re done. So, given that we’re not doing it manually, how do these things happen? Do we have to care? Well, sometimes. Maybe.
For example, ever wondered about the difference between is and ==, or why you might need to use deepcopy? Maybe you’ve been stumped by a variable changing when you didn’t expect it to, or an interview question about object lifetimes. Or, perhaps, you just really want to see some tuples behaving badly. This three-part series answers all these questions and more, covering the following:
- Part 1: what a pointer is, and where you’ll see them in Python
- Part 2: what the
idof a Python object is, and why it matters - Part 3: how CPython can tell when you’re done using an object in memory, and what it does next
Let’s dive in with Part 1!
What pointers are, and where you’ll find them
Firstly, we need to understand the concept of a namespace. A namespace in Python is the list of all the variables, keywords and functions that are in scope at any given point - that is, things you can write that the Python interpreter will understand. For example, all the built-in functions like print() and str(), and keywords like None and True are always in every namespace.
When you create a new variable, then that variable’s name is added to the namespace of whichever scope it’s in. So, for example, writing the following will add the name my_string to the global namespace:
>>> my_string = "Hello World!"For the purposes of this series of articles, we don’t need to worry about scopes; we can assume all our examples take place in the global namespace.
Pointers can be thought of as names - that is, entries in Python’s namespace - that correspond to objects in Python’s memory. In the above example, the pointer is my_string, and the object in memory is the string with value "Hello World!".
By using a pointer in namespace, you can access and manipulate the object in memory. And, just as a person might have multiple names, multiple pointers might point to the same object.
As an example, let’s consider a list object with the name my_list and two arbitrary elements.
my_list = ['string', 42]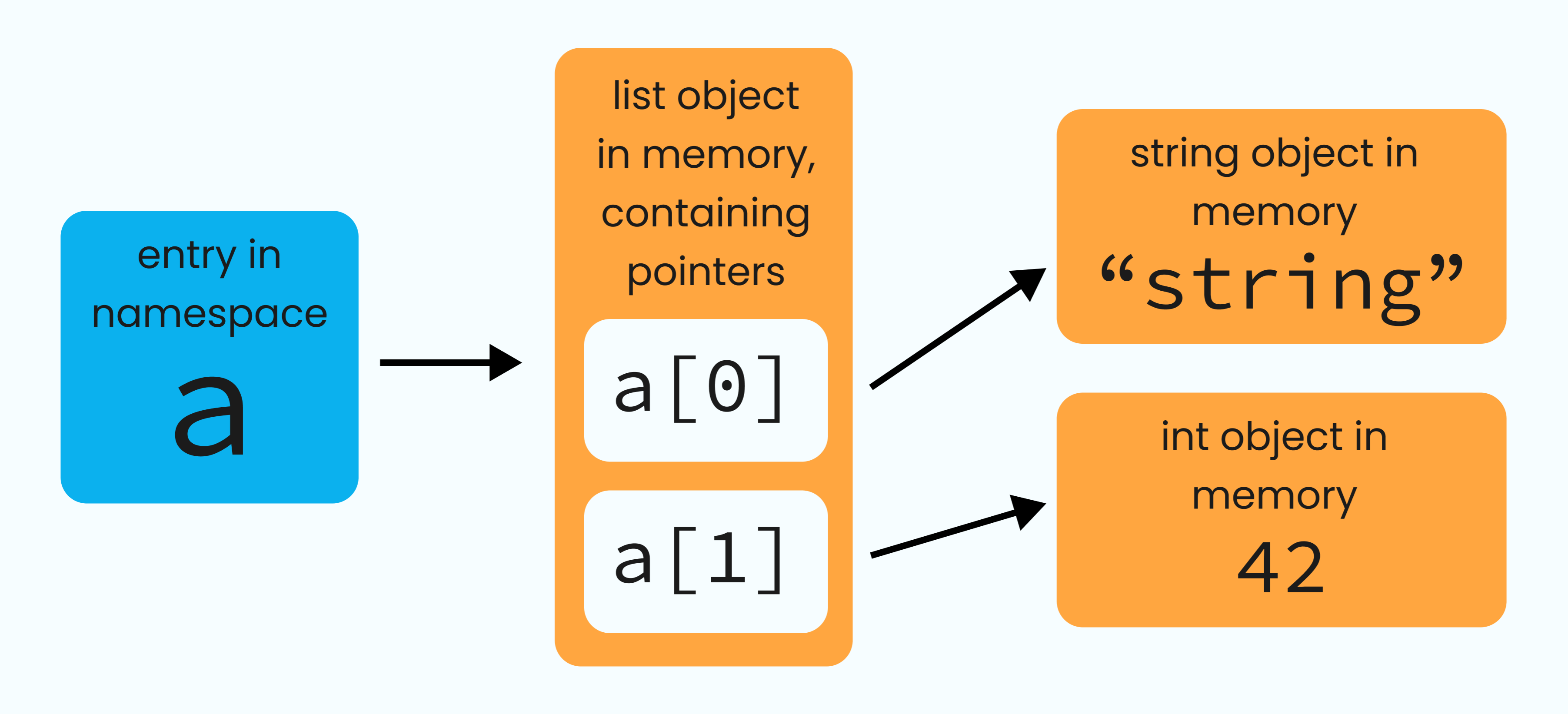
That name my_list then points to the list object. That list object then contains pointers to the two objects which are the elements of that list. So, when you create a list, it will automatically contain pointers if it has any elements. For that reason, we’ll be using a lot of lists as examples throughout this article.
Pointer aliasing
One Python behaviour that often trips up a lot of beginners is something called pointer aliasing, which is when two pointers refer to the same object in memory. Let’s look at an example: a list containing some strings.
>>> a = ["string", 42"]
>>> a
["string", 42]Here, we’ve defined our list a and got our interpreter to print it back out for us, just to check that it is as we expect. Next, we (naively) try to make a copy, and make some changes to it, namely changing "string" to "some words":
>>> b = a
>>> b[0] = "some words"
>>> b
["some words", 42]Great! Except, it turns out we’ve also changed our original list a:
>>> a
["some words", 42]The common misconception here is that a is the list object, when it’s actually just pointing at it, and might not be the only that that points at it. What’s happened above is that, in the line where we set b = a, we didn’t actually make a new list object. We just created a new pointer, b, and made it point to the same underlying list object that a already pointed to.
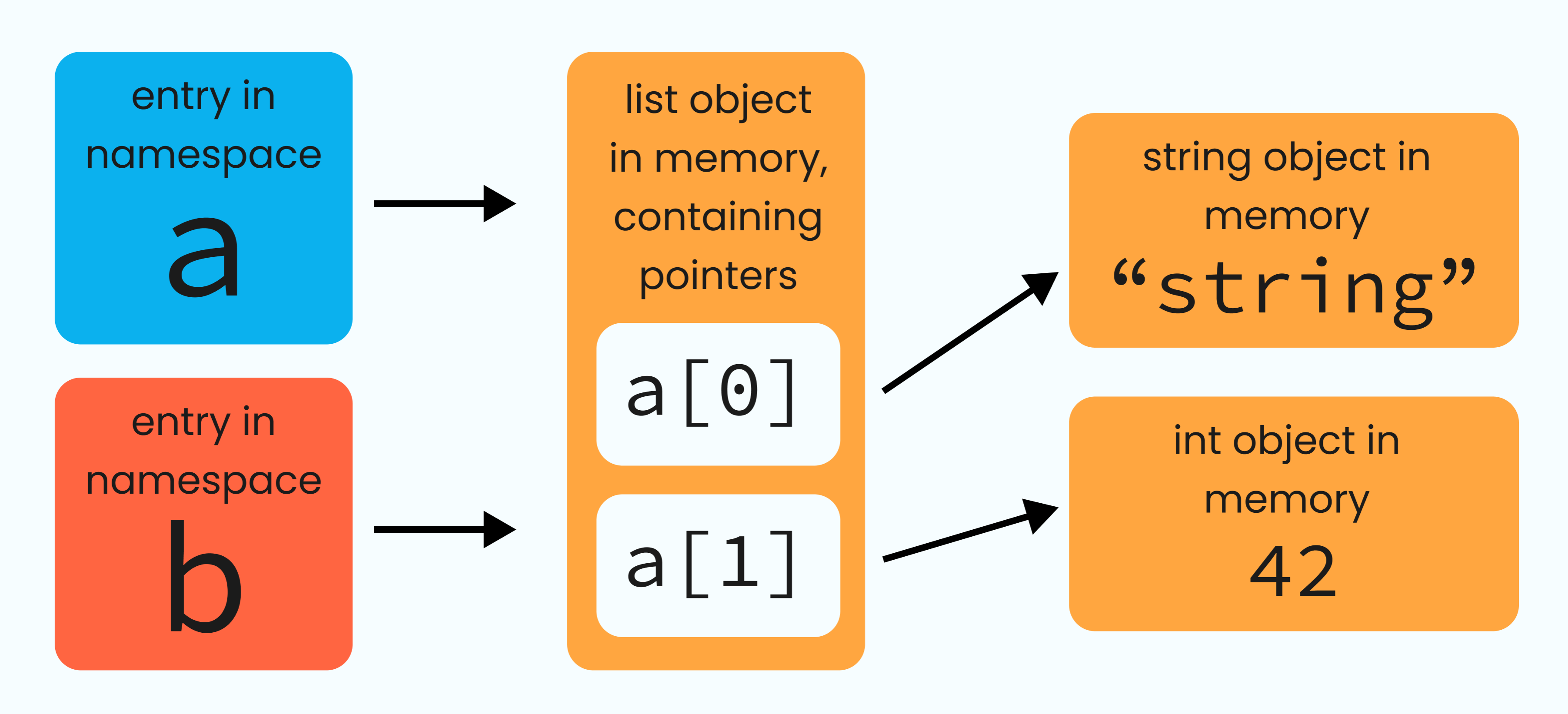
Using = on its own simply creates a new pointer to the same object - a simple pointer alias.
![So, when we change b[0], we change a[0] too.](img/pointers-in-my-python/006a-comparison-2.png)
So, when we change b[0], we change a[0] too.
So, when we change b, we’re changing a too. But what if we did want to make a new list object, and be able to make changes to it without affecting the original? Well, there’s a list method for that:
>>> c = a.copy()
>>> c[0] = "hello!"
>>> c
["hello!", 42]
>>> a
["some words", 42]We can use the copy method on our original list object, and this does create a new list object. That new list object will also contain new pointers - but, those pointers will then point to the same underlying elements of the original list.
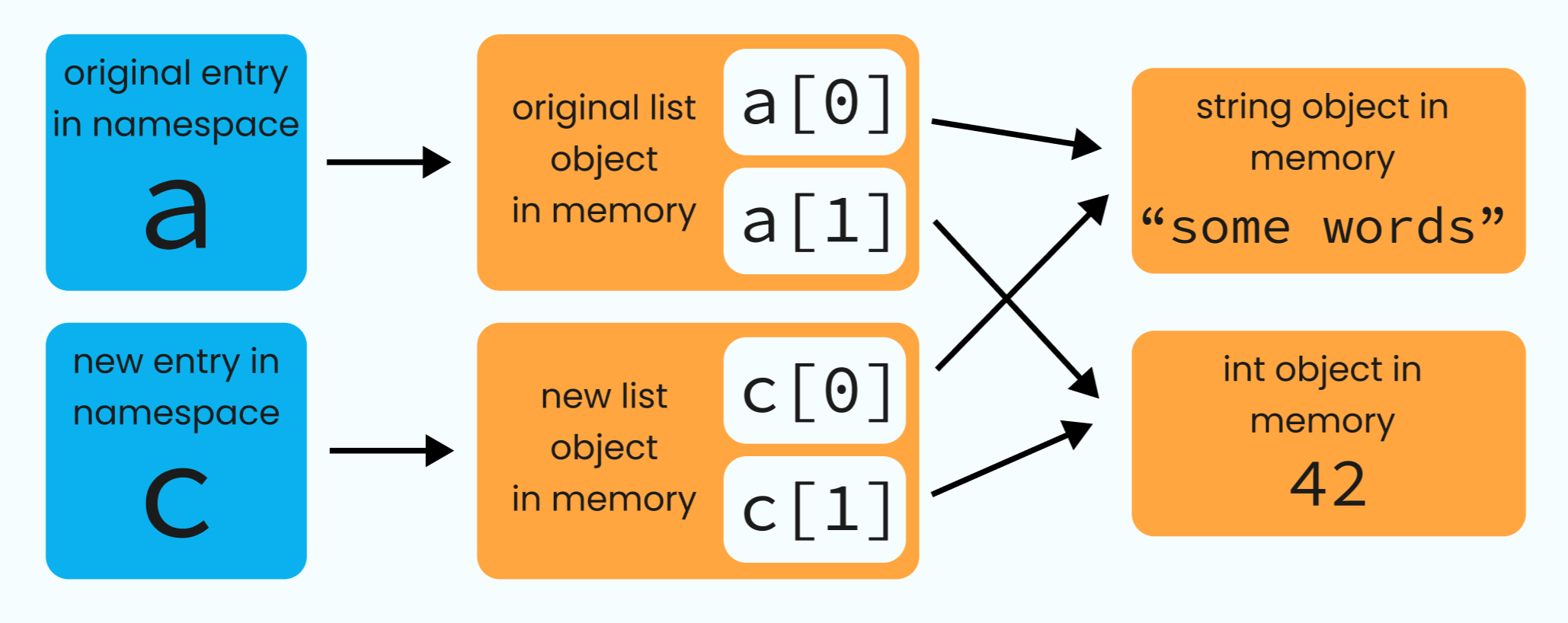
Using copy (whether as a list method or as a function from within the copy module) creates a new object, and populates it with new pointers to the existing elements.
![So, when we change c[0], we’re only changing that, and not a[0].](img/pointers-in-my-python/006b-comparison-2.png)
So, when we change c[0], we’re only changing that, and not a[0].
The outer list object - the thing that also has access to list methods, and which contains pointers to its contents, is different - but with copy, the elements of each list will still be the same objects in memory. So, what if those elements are themselves lists?
Let’s define a new list:
>>> a = [["alex", "beth"]]
>>> a
[["alex", "beth"]]Here’s a visual representation:
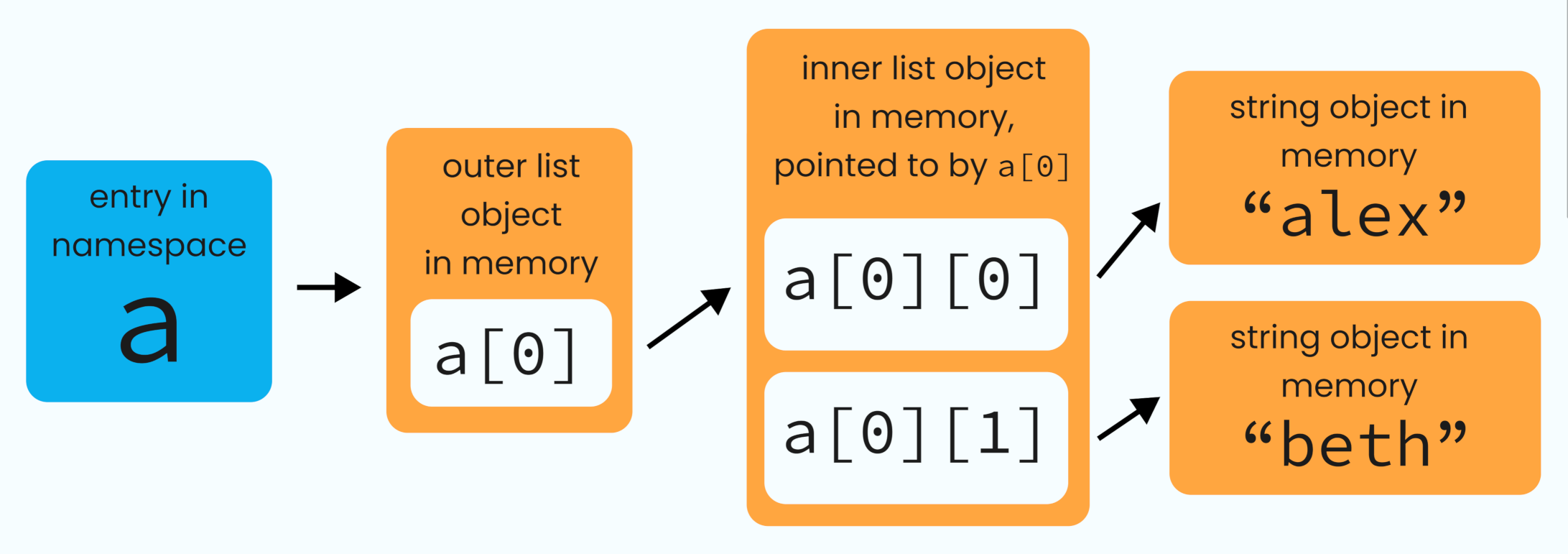
Here we have an outer list a whose only element is itself another list with two elements.
Now, let’s do as we did before, and make a new list object using the copy method. This time though, we’ll append something to the first element of b, not b itself.
>>> b = a.copy()
>>> b[0].append("charlie")
>>> b[0]
["alex", "beth", "charlie"]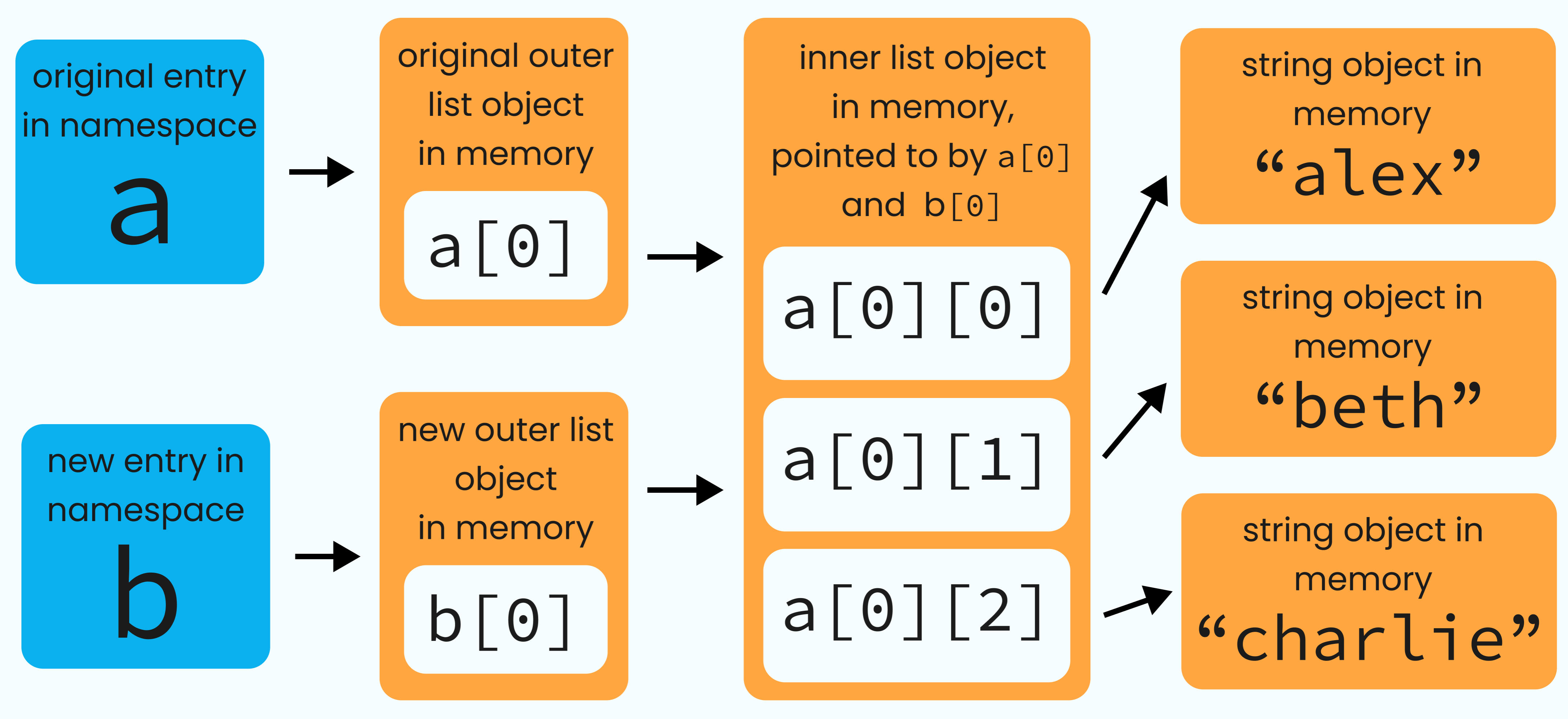
When we use copy, it creates a new outer list object in memory.
So far, so good, right? Except….
>>> a[0]
["alex", "beth", "charlie"]… we managed to alter the contents of a, even though we used the copy method. This is because, as stated above, the pointers in b still point at the same contents as the original list - so, we get the same pointer alisasing behaviour as we saw in the very first example, just one layer deeper. This kind of copy (only creating new objects one level deep, and pointer aliasing the rest) is called a ‘shallow copy’.
So, if we want to make a true, ‘deep’ copy - that is, to make not only a new list object, but new versions of all its contents - how do we do that? The answer is deepcopy, a function within the copy module of the standard library.
>>> from copy import deepcopy
>>> c = deepcopy(a)
>>> c[0].append("dan")
>>> c[0]
["alex", "beth", "charlie", "dan"]
>>> a[0]
["alex", "beth", "charlie"]What deepcopy does is recursively create new versions of every object it encounters - so, when it’s called on our list a, it’ll create a new list, and when it sees that the elements of a also contain pointers themselves, it’ll make new copies of the things those pointers point to as well. (Try saying that three times fast with a mouthful of spaghetti.)
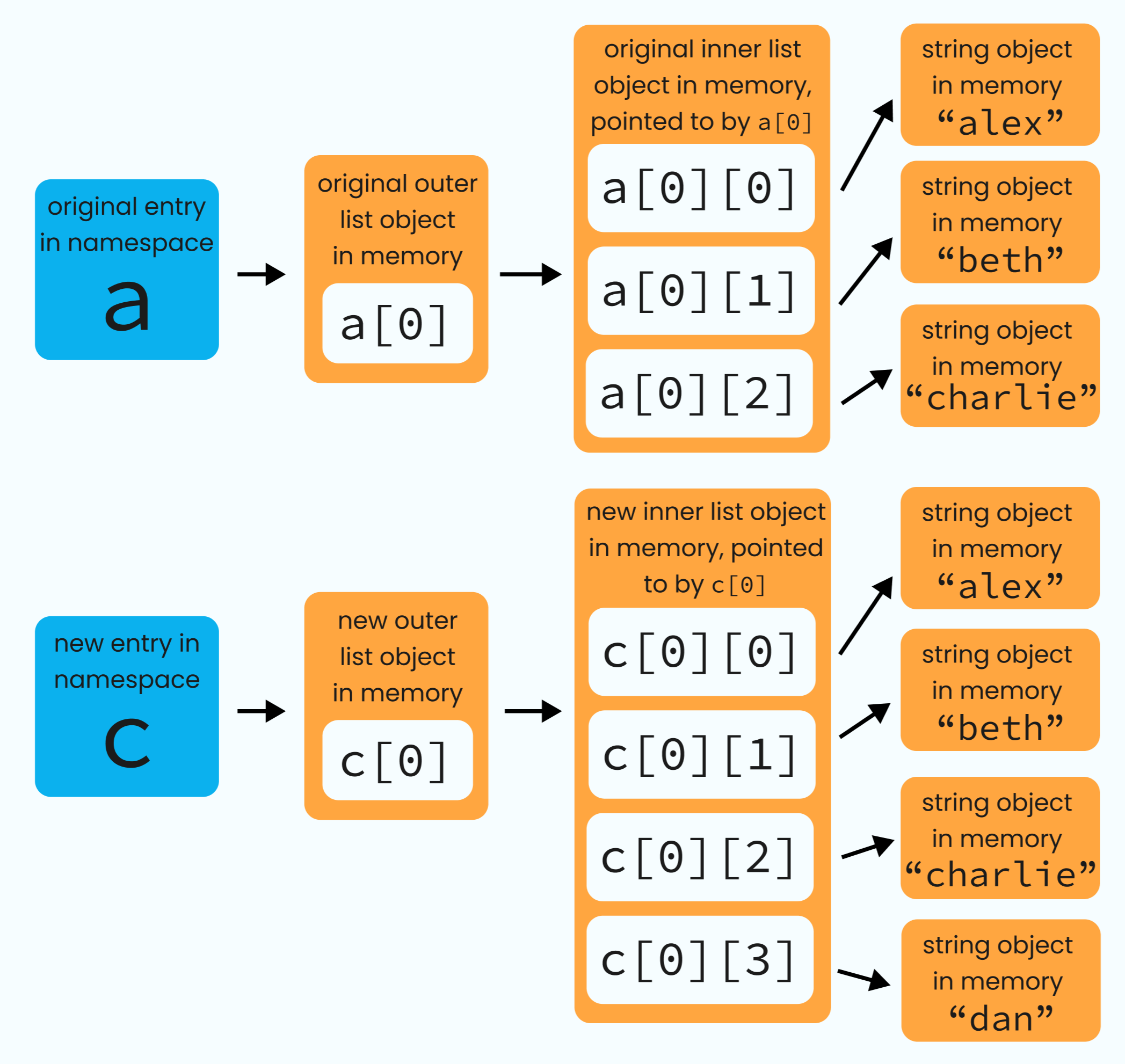
Using deepcopy creates a whole new inner list, complete with new contents. So, when we mutate the inner list of c, it’s not touching the original inner list that a points at - because deepcopy made a new, separate copy of that list when it created c.
alex pointed to by a[0][0] is also the same object in memory as the one pointed to by c[0][0], because Python has some memory optimisations that prevent it from creating the same immutable object twice if it doesn’t need to. If we’d used - for example - a user-defined class object instead of strings, then deepcopy would have caused Python to make new instances of those objects too.If we had an object with more layers of pointer nesting, such as a list containing a list containing a list, then deepcopy would make an entirely new copy of that entire object and all its contents, all the way down, with no pointer aliasing.
Immutable Objects (or: Tuples Behaving Badly)
So far, we’ve been looking at lists, which are mutable objects. What happens if we look at something immutable, like a tuple?
If we say that a tuple a is immutable, what we mean by that is that when a is created, all its elements - a[0], a[1], and so on - are fixed. If its elements are immutable, like strings or integers, it’s fairly simple to understand what this means.
>>> a = (42, 'beeblebrox')
>>> a[0] = 63
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignmentIf we try to change the value of a[0], we get an error. But, what if a[0] is a pointer to something mutable, like a list?
>>> a = ([1, 2, 3], "hello")
>>> a[0].append(4)
>>> a
([1, 2, 3, 4], "hello")As it turns out, we can mutate the elements of a in-place with no problem! This is because we’re not changing the value of a[0] itself - it’s just a pointer. What we’re changing is the value of the object that a[0] points to. If we gave a[0] its own name - a pointer alias - this would become a bit clearer:
>>> my_list = [1, 2, 3]
>>> a = (my_list, "hello")
>>> my_list.append(4)
>>> a
([1, 2, 3, 4], "hello")However, the append method isn’t the only way to add to a list!
The += operator
We can do the following:
>>> my_list = [1, 2, 3, 4]
>>> my_list += [5, ]
>>> my_list
[1, 2, 3, 4, 5]Here, we’re using the += operator, which does the following:
- First, it creates the desired object. For mutable objects, like a list, it does this by mutating the object in-place. For immutable objects, like strings, it creates an entirely new object. This is the ‘
+’ part of the operation. - Secondly, it reassigns the pointer it was given (in the above example,
my_list) to point at the desired object.
If += is called on a mutable object, then Step 2 is pretty redundant - after all, the pointer is already pointing at the desired object. But when it’s called on something immutable - like a string - it does need to change where the pointer points. For example:
>>> my_string = 'Hello'
>>> my_string += ', World!'
>>> my_string
'Hello, World!'Strings aren’t mutable, so in Step 1, += creates an entirely new string 'Hello, World!' and changes the my_string pointer to point at it.
Here’s a visual representation:

So what if we try the += operator with the first element of our tuple a? Spoiler alert: something silly is about to happen!
>>> a = ([1, 2, 3, 4], "hello")
>>> a[0] += [5, ]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> a
([1, 2, 3, 4, 5], "hello")What on earth is going on there? We get an error when we try to use the += with a tuple element, but the operation seems to have gone through anyway; the value of a[0] has changed, at least.
Step 2 is where we fall over: in this case, we can’t assign directly to a[0], since it’s an element of a tuple. In the my_list example, however, there was no problem at all, since we can set my_list to point at whatever we like.
But, in step 1, the list object that a[0] points at was mutated in-place, which is the change we wanted to happen. Then, in Step 2, += assigns to the pointer it’s called on - a[0] - and we can’t assign to that! So, we get both the change and the error.
So, what have we learned? We’ve covered namespaces, what pointers are, and where you’ll see them in code, along with some examples of how immutability and pointers can interact in confusing ways. But we’re only scratching the surface - check out Part 2, where we’ll learn about Object IDs and why they matter, how Python knows when two objects are really the same, and the difference between is and ==.
More about Anvil
If you’re new here, welcome! Anvil is a platform for building full-stack web apps with nothing but Python. No need to wrestle with JS, HTML, CSS, Python, SQL and all their frameworks – just build it all in Python.
Learn More
Get Started with Anvil
Nothing but Python required!
Seven ways to plot data in Python

Python is the language of Data Science, and there are many plotting libraries out there.
Which should you choose?
In this guide, we introduce and explain the best-known Python plotting libraries, with a detailed article on each one.
Deploy data science to the web with Deepnote

Generate PDF Invoices with Python
Rapid Prototyping: Building Calendly in 3 Hours