 By
By Auto-completing Python on the Web
Why do you need autocompletion, and how does it work? My talk at PyCon UK 2017 explains how – and why – we built an in-browser autocompleter for Anvil.
Note: This guide includes screenshots of the Classic Editor. Since we created this guide, we've released the new Anvil Editor, which is more powerful and easier to use.
All the code in this guide will work, but the Anvil Editor will look a little different to the screenshots you see here!
Watch it below, or scroll down for a transcript:
<div class="figure-wrap ">
<figure class=" " ><img src="img/logo-black-no-tagline.png"
alt="Anvil logo"/> <figcaption>
<p>For more information about Anvil, check out <a href="/">anvil.works</a></p>
</figcaption>
</figure>
</div>
<div class="figure-wrap ">
<figure class=" " ><img src="img/skulpt.png"
alt="Skulpt logo"/> <figcaption>
<p>For more information about Skulpt, check out <a href="http://skulpt.org">skulpt.org</a></p>
</figcaption>
</figure>
</div>
Transcript:



Having proper code completion gives you discoverability. It lets you explore the APIs, without having to tab to the documentation all the time. It gives you speed, because you go a lot faster when you can hit the Tab key every few characters. It gives you confidence that what you’re doing is right, because there are whole classes of bugs you can fix without even hitting the Run button. And it just feels good to use.
We started out thinking we could make a good developer experience without autocomplete. I’m here to tell you that we were wrong.
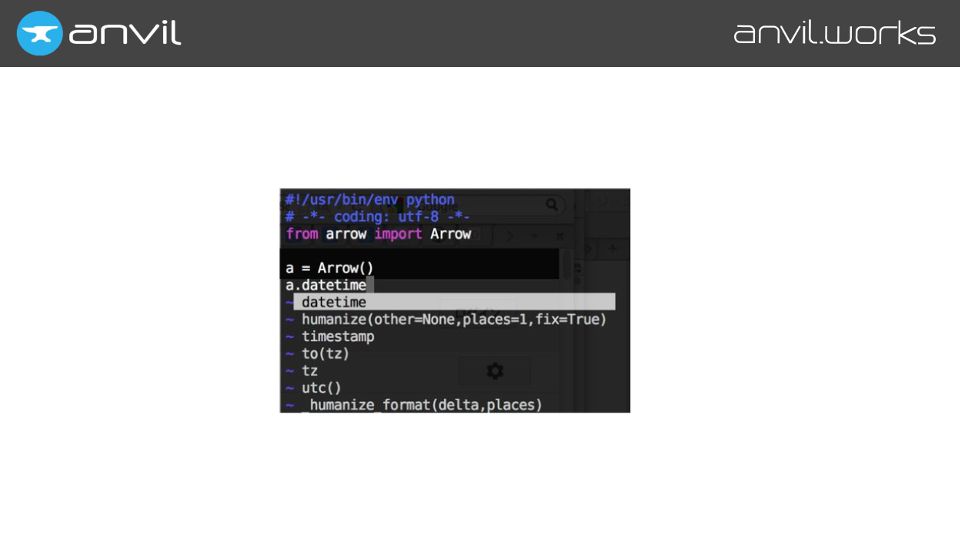
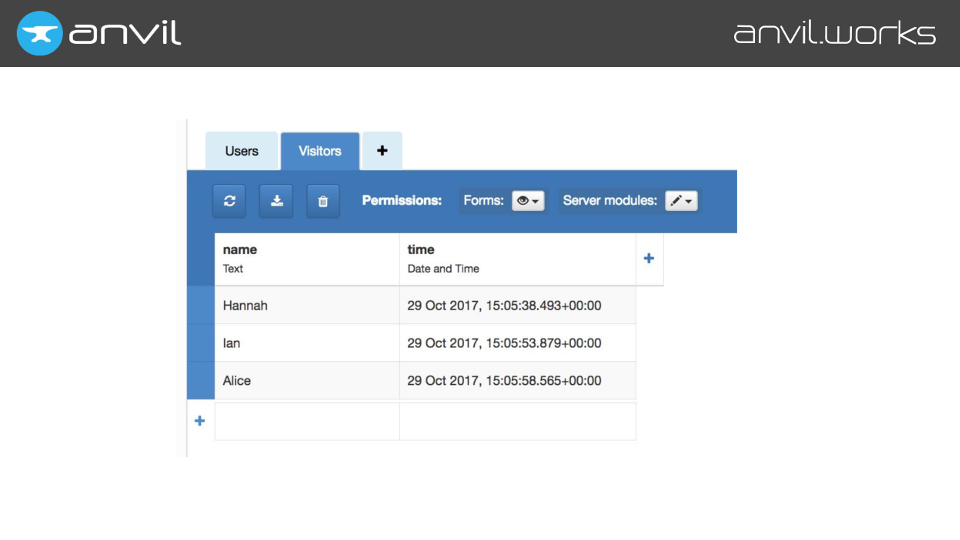
…to your client-side code. And it’s got to autocomplete all of them.
What’s more, Anvil is web-based, and Jedi is expecting a filesystem. And when you’re hitting the Tab key, there’s just not enough time to go back to the server to fetch your completions.
So we had to write it ourselves, in Javascript. Which means that, yes, here I am, talking about my Javascript project at a Python conference. (Please save the rotten fruit until after the photos at the end.)

So, what do we do?
Conveniently, because Anvil runs all your client-side Python code in the browser, we have a Javascript parser for Python just lying around the place. (We use the open-source Skulpt project.)
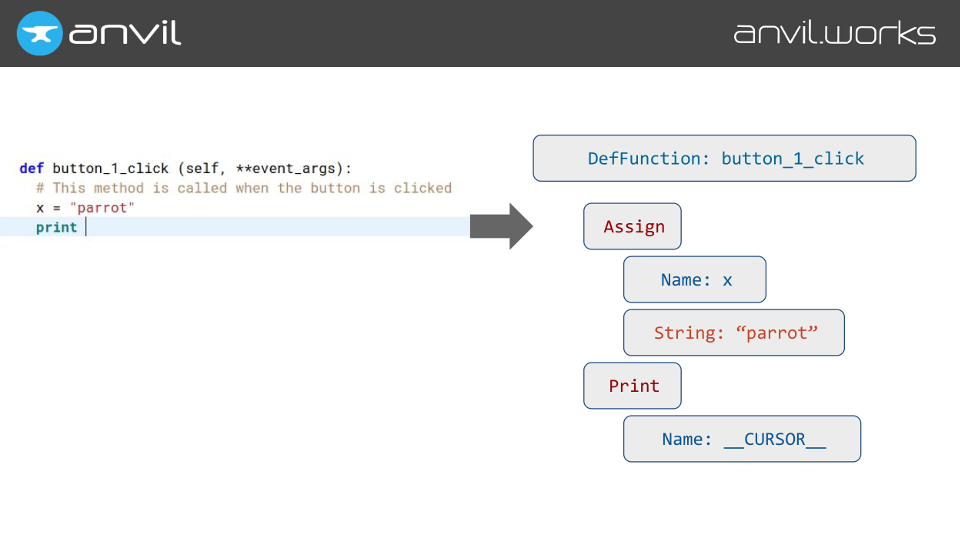
So we can take your code, insert a random symbol at your cursor position, and then feed it to the Skulpt parser. The parser then produces an abstract syntax tree that represents your module.
We can then recursively walk this tree, and build up a representation of what’s in scope at any given point in the code. We actually use Javascript’s prototypical inheritance for this: Inside scopes (like inside a function) prototypically inherit all the names that are in scope from outside scopes (like the module globals).
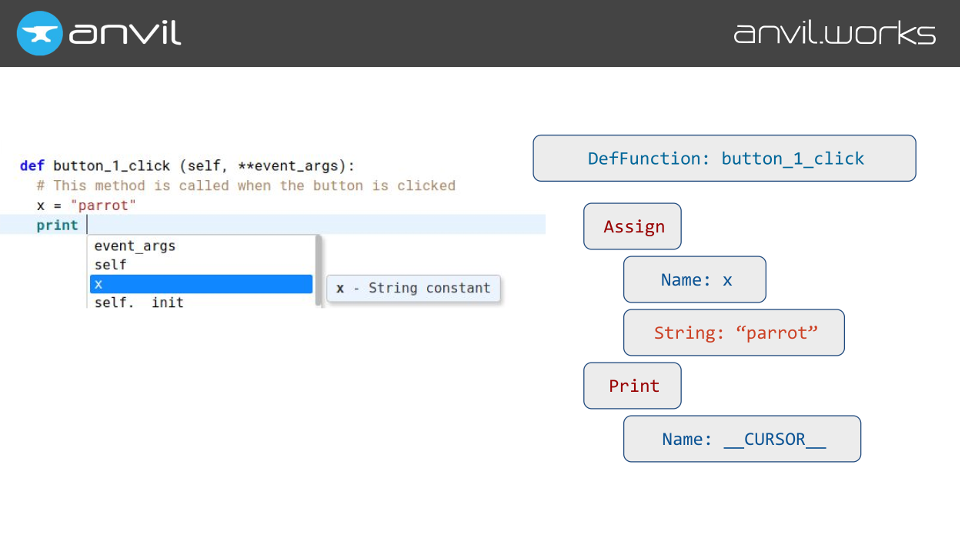
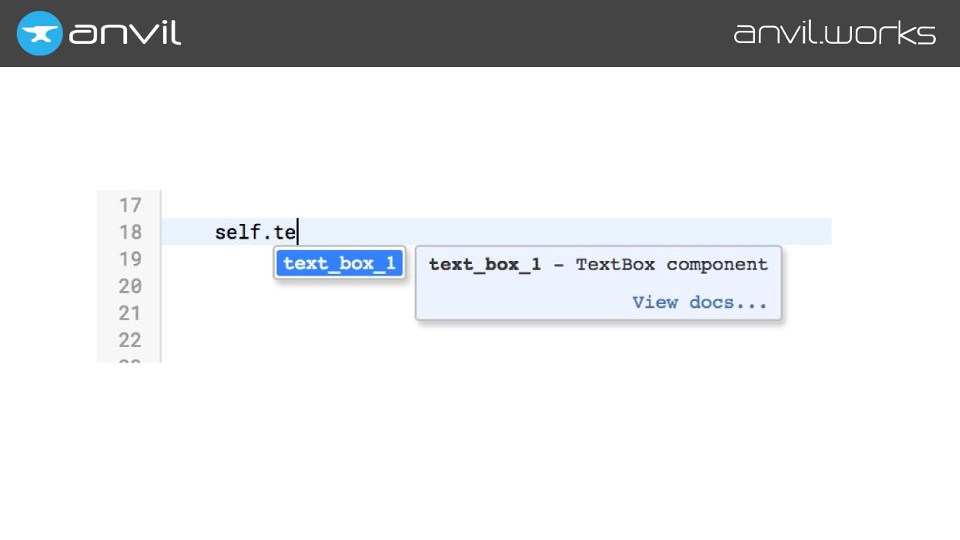
Name node that contains the magic cursor symbol, we can just suggest all the things that are currently in scope.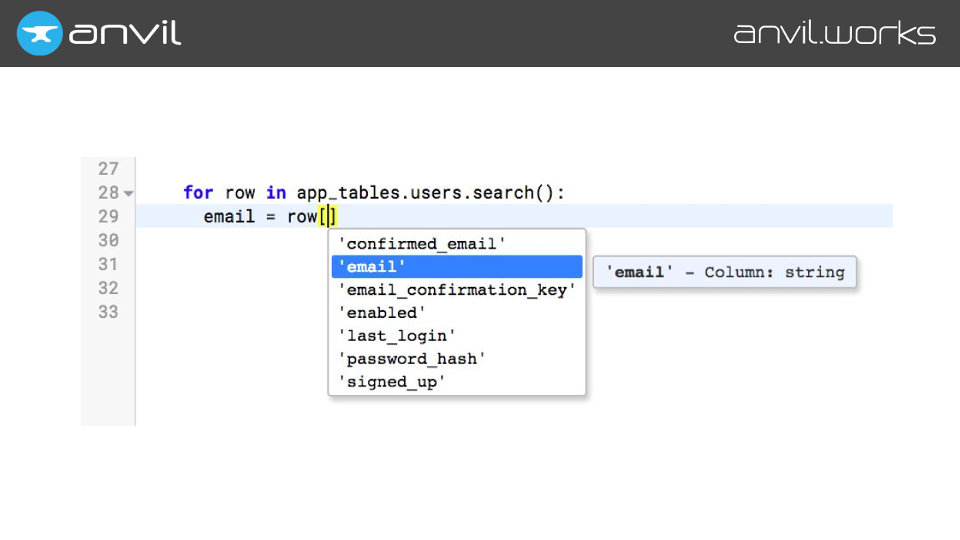
That’s not the only thing we want to autocomplete. For example, you can access Anvil’s database rows like dictionaries, using square brackets (aka getitem). So we have to store which items are available on each type.
We also compute and store what you get if you iterate over an object, what its attributes are, what you get if you call it as a function, and so on.
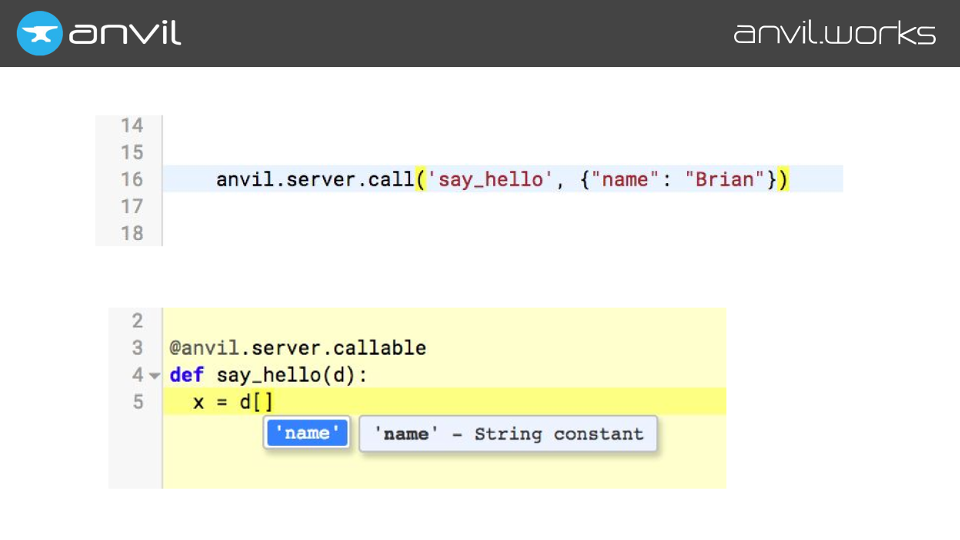
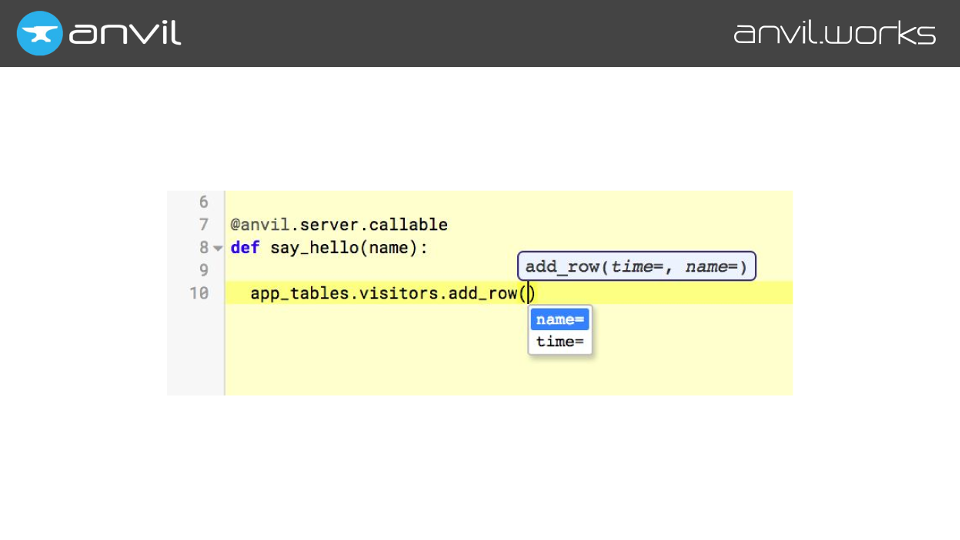
Speaking of function calls, we also need to infer between modules. For example, in Anvil you write your server code in Python, and you call it from the client with a Python function call. And if you pass something into that server code, you want to be able to autocomplete it inside that server function.
So, as well as saving the top-level scope of every module (so it can be used in import statements from other modules), we also store every outbound call from a module – including calls to the server.
So when we parse this client code, we store this outbound call, along with the types of its arguments. And then when we’re parsing the server code for autocomplete, we can just pull out the type information for those arguments, and stick it into the local scope, where it autocompletes.
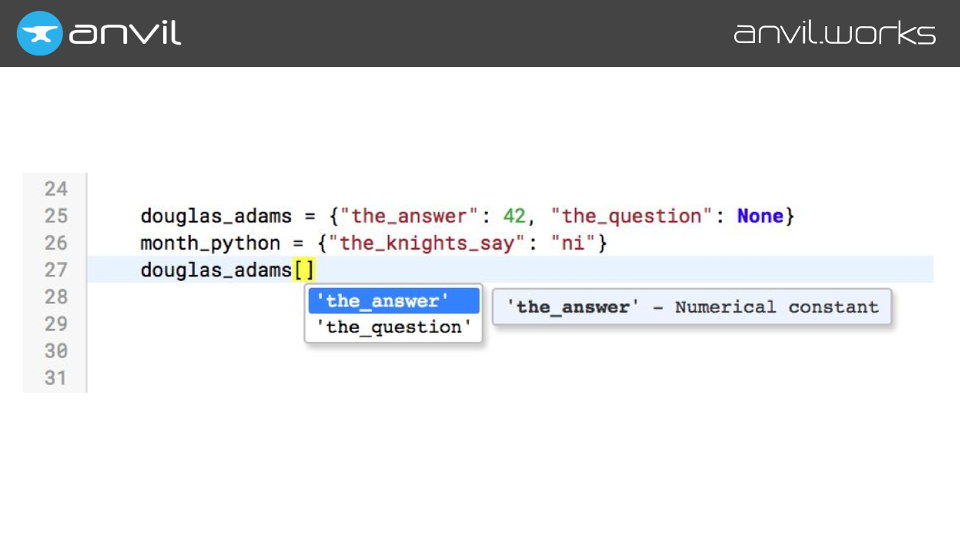
We can store a lot of information about types. This leads to a rather philosophical discussion about what, exactly, a type is.
You might say, “that’s easy, the type of an object is its Python class”. But of course, in Python, you can dynamically add attributes to individual object instances. And, arguably, even two dicts aren’t really the same type.
So what we actually do is mostly forget the Python class – our autocompleter is duck-typed. As far as we’re concerned, these two dictionaries are two separate types, with separate item mappings, and should be treated as such.

There’s so much more I could talk about, but this is a short talk. And so, if you remember only one thing, make it this:
Ladies and gentlemen of Pycon UK 2017, use autocomplete!
Thank you very much.