I was wondering if there’s a way I can try to import existing data from a data frame/excel/csv into a data table?
I’m just about to embark on a form to upload a csv,parse it and insert it.
I’ll let you know how I get on, if that is any use to you.
1 Like
This seems to work for small-ish csv files. No idea what the file size limit is. Probably have to use google drive for bigger files or xlsx.
Hope it helps someone kick off anyway.
In your form, add a FileLoader. Then add this event -
def file_loader_1_change (self, files, **event_args):
# This method is called when a new file is loaded into this FileLoader
for f in files:
filedata=f.get_bytes()
anvil.server.call('read_csv',filedata)
Next, create a server module and add
import csv
...
@anvil.server.callable
def read_csv(csv_string):
# Turn the string into a list for csv_reader.
csv_list=csv_string.split()
# Create csv reader instance
cr=csv.reader(csv_list)
for csv_line in cr:
# Each field is [0],[1], etc.
print(csv_line[0])
EDIT:
Doubt this need saying, but there’s no error checking in there, so please don’t use verbatim!
EDIT 2:
Just tested with a 3meg file (300k rows) and it worked - took about 10 seconds.
Hi David,
That looks like a good solution, I just have one suggestion: Pass the entire Media object (in this case file_loader_1.file) to the server function, rather than just the byte string, then call get_bytes on the server side. This will avoid any unicode string encoding issues, and also avoid message size limits in our underlying transfer layer.
By sending the Media object, you will be take advantage of binary streaming, with no encoding issues and no size limit (within reason).
2 Likes
Here’s an example for reading a very simple CSV server side (which is all I need right now). Would welcome an example for reading more complex CSVs. Hope this might help someone somewhere.
Example file contains -
line1field1,line1field2,line1field3
line2field1,line2field2,line2field3
Client side code -
def file_loader_1_change(self, files, **event_args):
# This method is called when a new file is loaded into this FileLoader
for f in files:
anvil.server.call('read_csv', f)
Server side code -
@anvil.server.callable
def read_csv(csv_object):
# Get the data as bytes.
csv_bytes = csv_object.get_bytes()
# Convert bytes to a string.
csv_string = str(csv_bytes, "utf-8")
# Create a list of lines split on \n
line_list = csv_string.split('\n')
for line in line_list:
# Create a list of fields from line.
print("line=", line)
field_list = line.split(",")
for field in field_list:
print("field=", field)
You should see the following in the output window -
line= line1field1,line1field2,line1field3
field= line1field1
field= line1field2
field= line1field3
line= line2field1,line2field2,line2field3
field= line2field1
field= line2field2
field= line2field3
1 Like
@david.wylie @daviesian Thanks for the suggestions. I tried @david.wylie’s first suggestion and got some errors I haven’t worked out yet, but haven’t tried the second. I have a large csv file (26,000 rows and 20+ columns), so I’m hoping one will work. I’m wondering, if I just need to get data into a Data Table, do I have to have a FileUpload in my app? Would the Server Uplink work for this also? Which will work better?
@chris - be aware I am using Python 3 syntax. So, for example, “print” is a statement in Python 2 but a function in 3, eg - “print varname” in v2, print(varname) in 3).
Hi Chris,
It’s really up to you whether you use a FileUpload component or an Uplink script to get data into your app. Both should work just fine. If you want to make something reusable then a simple GUI with an uploader might be better. If you want to do some data processing before sending to Anvil, then you’d be better off with a script. It’s entirely your call.
I’m trying the Uplink script method since I do have some data processing and don’t need a reusable uploading capability. I’m getting this error message:
AnvilSerializationError: Cannot serialize return value from function. Value must be JSON serializable
at Form1, line 13
Here’s what I’m trying on the Anvil side:
from anvil import *
from tables import app_tables
import anvil.server
class Form1(Form1Template):
def __init__(self, **properties):
# You must call self.init_components() before doing anything else in this function
self.init_components(**properties)
# Any code you write here will run when the form opens.
#
input = anvil.server.call("import_row", 0)
print(input)
print("Hello World!")
# Add row from excel file to Data Table
app_tables.data_table1.add_row(input)
And here’s what I have on the “server” side (my computer):
# This is a simple program using Anvil Uplink to serve
# an Excel file from my hard disk.
import pandas as pd
import numpy as np
import anvil.server
# Create data frame for Excel file, which is a basic spreadsheet of 26 columns and 26,000 rows
df = pd.read_excel('../normalized_DB.xlsx', header=0)
@anvil.server.callable
def import_row(row_num):
return(df.loc[row_num])
anvil.server.connect("[key]")
anvil.server.wait_forever()
Ultimately, I’d like to iterate over all the rows and get them into the Data Table, but I’m just trying to get the first row working here. Do I need to convert the data to JSON? Is there any way to keep it simple and avoid that step?
Hi Chris,
Anvil can return a lot from a server function, but custom classes like Pandas data frame rows will fox it. If you want to return data like this, I’d suggest turning it into a dict (Pandas’s to_dict() method will help you here).
In fact, if you’re using the uplink, you don’t even need to return this data from a server function - you can add it to the data table directly! You can call add_row() on a data table from Uplink code, same as server code.
Something like this, perhaps:
import anvil.server
from tables import app_tables
anvil.server.connect("[key]")
df = pd.read_excel(...)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
app_tables.my_table.add_row(**d)
Does that do what you want?
1 Like
Meredydd,
Wow, incredibly simple. From what I can tell, it should have worked but I hit another error I can’t figure out:
Anvil websocket closed (code 1006, reason=Going away)
Traceback (most recent call last):
File "Uplink.py", line 30, in <module>
app_tables.my_table.add_row(**d)
File "/usr/local/lib/python2.7/site-packages/anvil/_server.py", line 29, in item_fn
return _do_call(args, kwargs, lo_call=lo_call)
File "/usr/local/lib/python2.7/site-packages/anvil/server.py", line 193, in _do_call
return _threaded_server.do_call(args, kwargs, fn_name, lo_call)
File "/usr/local/lib/python2.7/site-packages/anvil/_threaded_server.py", line 210, in do_call
raise _server._deserialise_exception(r["error"])
File "/usr/local/lib/python2.7/site-packages/anvil/_server.py", line 183, in _deserialise_exception
return _named_exceptions.get(error_obj.get("type"), AnvilWrappedError)(error_obj)
AttributeError: 'unicode' object has no attribute 'get'
A couple of assumptions I made in trying your code:
It looks like I don’t need to use the @anvil.server.callable decorator. I also run this code from my Mac, when you say “Uplink code”, not in Anvil. I tried keeping the anvil.server.wait_forever() in there to no avail. I also assume I need to “Run” my Anvil app before running my Python code on my machine. I haven’t added anything in my Anvil code. I can’t think of much else to do, but it’s not working.
Hrm. That’s a bug - you’ve got some sort of exception sent back from the Anvil server, but it’s failed trying to unpack the exception. Quick check - are you using the latest uplink library? Try:
pip install anvil-uplink --upgrade
Annoyingly, that sample code is working perfectly for me, so I’m going to need some help from you to reproduce that! If you’re OK sharing it, would you be able to send your uplink script (and Excel file) by email to support@anvil.works?
Update: Chris and I have corresponded by email. An Uplink upgrade reveals the real error, which was “You can’t store NaN values in data tables”. Now he is converting his NaNs to Nones, his import is working.
2 Likes
Hi,
I have hard time understanding the code, is it possible to post an example app to show how to upload data (excel file) to the app.tables ?
Thank you for your help
1 Like
@adhamfaisal Hi there.
Here’s a little app that downloads some sample data onto your computer, and then allows you to upload it into a data table. I hope this helps to clarify things.
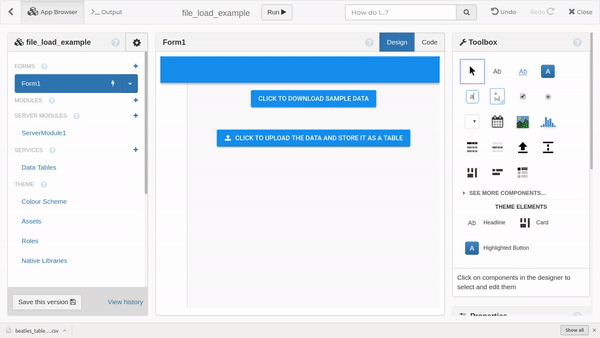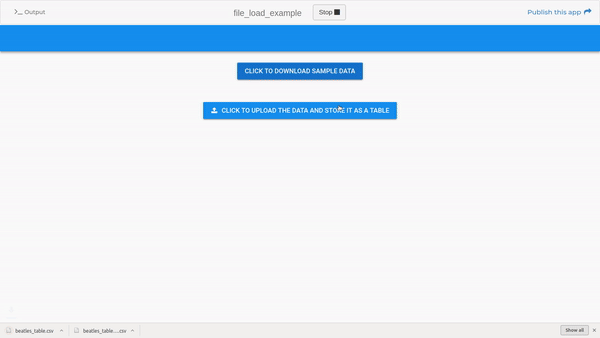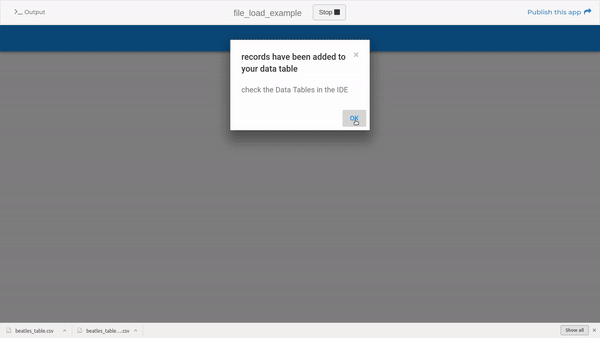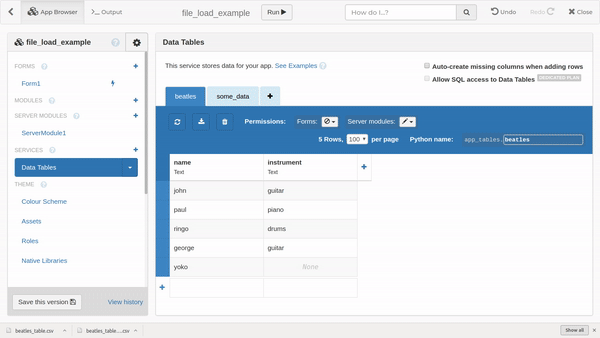
clone:
https://anvil.works/build#clone:TIBQ7CSOSPIXHJ4R=UGRKSUZCMLOVGKR7NAAF3TDN
5 Likes
Thank you for sharing the app., Unfortunately; I don’t have full python 3 runtime library at current time (I am still in the learning stage), can you please modify the app so it can work with the regular membership.
Thank you.
I would suggest learning uplink as you will be able to use modules that are not available in the python 2 runtime.
The uplink tutorial is a good one. In the IDE, click the  icon and then “uplink” and follow the instructions.
icon and then “uplink” and follow the instructions.
Perhaps try to modify the app I sent previously (change the runtime to python 2 and remove/ignore the “click to upload” button). Then, on your computer make a script with the following details:
import anvil.server
from tables import app_tables
import pandas as pd
anvil.server.connect("<paste in the uplink key you get from your app>")
df = pd.read_csv('beatles.csv') # or any CSV file with columns that match your DataTable
df = df.replace({pd.np.nan: None})
for d in df.to_dict(orient="records"):
app_tables.beatles.add_row(**d)
Basically, you just want to move the server function that was using pandas to your local computer.
5 Likes
Thank you, I will give it a try.
Thank you it works great!
3 Likes
Hi all,
I am trying to execute the code offered by @alcampopiano on my pc, however I get the following error
anvil.server.connect(“Key”)
df = pd.read_csv(r'\Pm_flow_deliverables.csv')
df = df.replace({pd.np.nan: None})
for d in df.to_dict(orient="Doc_number"):
app_tables.deliverable_store.add_row(**d)
print(d[0])
print(d['doc_name'])
Traceback (most recent call last):
File “c:/Users/dpnan/OneDrive/Documents/Python/PM flow/PM_flow_upload.py”, line 17, in
app_tables.deliverable_store.add_row(**d)
TypeError: item_fn() argument after ** must be a mapping, not str