Hi There!
I’m creating an app which allows a sales person to take down orders. Since they are ridiciously fast typers i need to have the articles cached on client side.
When creating a dictionary server side, which is then shipped to the client, i get a timeout error.
I know why the error occurs (<30sec) and i know that I could circumvent this with a background task.
However, since I belive 1000 rows should be iterated faster, the error must be in my code or understanding of the search iterator.
I’ve tried several things (even launching two background tasks in parallel which take first and second half of the table and merge them together later  ) but none improved the speed significantly.
) but none improved the speed significantly.
Here is an exemplary app with my datatable.
https://anvil.works/build#clone:IFYXW5PLY45QBNKL=NZ6WYD2SVKTCLQK6CBBC6W2N
Code
print('rows',len(app_tables.article.search()))
for i in app_tables.article.search():
ret[i.get_id()] = {'name':i['name'],'row_id':i.get_id(), 'id': i['id'],'no_discount': i['no_discount'],
'price':i['price'],'ust':i['ust_dropdown'],'ks':i['in_kuehlraum']}
Exception
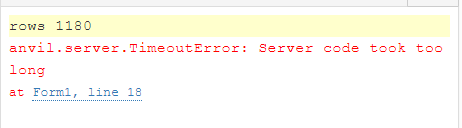
Any help or suggestions are appreciated.
Cheers, Mark
 .
. . Also I havent explored much into splitting up the datatable or caching the cache in a separate column, but that would proboably be worth a look.
. Also I havent explored much into splitting up the datatable or caching the cache in a separate column, but that would proboably be worth a look.