My app has been fairly slow for awhile (7-15 second data grid load time for ~500 records), and I finally got around to investigating it deeper. I will probably write another post soon with some questions about best practices. However, I seem to have gotten to a point where I may need to abandon Anvil Data Tables altogether due to performance so wanted to see if I am missing anything before doing so.
I have gone through a ton of performance posts. Here are a few good ones:
- Suggestions to Optimize Performance
- Database calls: single vs multiple (cost and performance)
- Server code takes more than 15 seconds to iterate over 1000 rows?
However, I was still struggling to get down to a <3 second load time for my data grid. After investigating, it seems that a lot of my issues arose from constructing lists of dicts/AnvilRows from a table.search(). For many solutions on the forums and docs, people construct these dict lists from the table row iterator (ex. Table search question).
Anyways, I decided to time some of these constructions for a 21 column / 500 record Anvil data table. There is an example here:
https://anvil.works/build#clone:HJYFARTFSFW5S7X2=OEKV3BR4O6E4IQ6TSS2SOYVR
Basically, by clicking the “GET” button, it runs this code:
def button_3_click(self, **event_args):
print("Anvil table with 21 columns and 500 rows\n")
then = datetime.datetime.now()
columns_21_without_images = anvil.server.call('get_it')
print("(1) Server load 21 columns w/o images:")
print(" Time: " + str(datetime.datetime.now() - then) + '\n')
then = datetime.datetime.now()
columns_21_with_2_image_columns = anvil.server.call('get_it2')
print("(2) Server load 21 columns with 2 image columns:")
print(" Time: " + str(datetime.datetime.now() - then) + '\n')
then = datetime.datetime.now()
dict_columns_21_without_images = [r for r in columns_21_without_images]
print("(3) Create list of dicts from search w/o images:")
print(" Time: " + str(datetime.datetime.now() - then) + '\n')
then = datetime.datetime.now()
[r for r in columns_21_with_2_image_columns]
print("(4) Create list of dicts from search with images:")
print(" Time: " + str(datetime.datetime.now() - then) + '\n')
then = datetime.datetime.now()
[r for r in dict_columns_21_without_images]
print("(5) Create list of dicts from list of dicts:")
print(" Time: " + str(datetime.datetime.now() - then) + '\n')
with an output of:
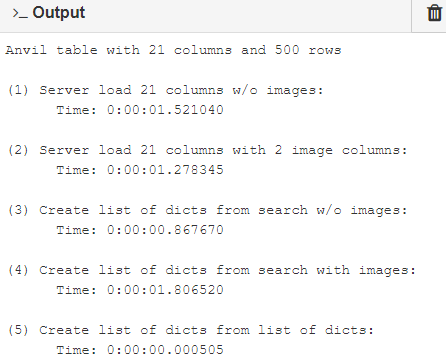
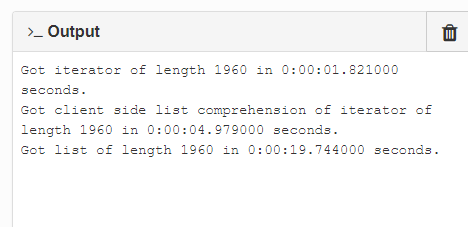
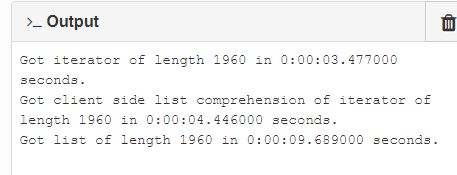
The point is that any time I have to run a loop over the 500 record search iterator, I burn 1-2 seconds of load time. The last case I have in there is doing the same thing with a list of 500 dictionaries (this performs at 1000-2000x speedup). This seems to suggest a lot of relative overhead for Anvil rows (also see stefano.menci’s comment here).
Why would I want to loop over the search? Well, there are many reasons. I will give one (simplified from my real case) example, and I can give more if needed. One case is that each of my Anvil rows has a category column. The category column is actually a link to another Anvil table, but let’s just pretend it is text. So each one of my 500 records is assigned to say, one of 10 categories. I would like to make a dropdown that displays these 10 categories so people can filter using them. One way to do this would be to construct a list of dictionaries using my 500 row search iterator and feed that into the dropdown.
Sorry for the long post. I actually really enjoy aspects of the Anvil tables and am hesitant to give them up. But my questions are…
Questions
- When Anvil tables get past the size of 100-1000 rows, do they stop becoming useful?
- Is the performance of the Anvil row iterator really as bad as I am getting (compared to list of dicts)? Am I doing something incorrectly? Any ideas on speeding it up?
- If the answer to (1.) is yes, what is the best alternative? Should I store data in an external SQL database and call a server function to ask the database for a list of dicts? Then, send that list of dicts to my data grid? Could someone describe an example of a workflow they use for a database with >1000 records?
- In particular, I am very interest in creating something like an Amazon-like display. You have 1000 inventory items and you want to give the user dropdowns and boxes to filter things. So should the workflow be to request a large, unfiltered amount of data from your database with one server call and then construct a pandas dataframe (or an alternative) on the client side for all filtering events? Or should I make a server call every time a new filter is requested? Example, I would ask the server to ask the database to give me all the items and then send them to the client. Then, the user wants to filter out expensive items. So I go back to the server with the query and ask the database to apply the filter then return to the client exactly what needs to be displayed in a list of dicts. Which one do you guys go for?
Again, sorry for the long post. These questions have built up over 6 months, and I have many details around each. Thanks for any help.