Bug report here, since there’s no option for a bug report in the topic dropdown.
I have a 3.10 Python going in Anvil, haven’t tried this with not-3.10. The below is a client-side set of code ( (we will also see below where I found out what’s actually going on, but it’s worth showing this.)
As I am a new user, I can only upload one image which is a pain so I’ll type stuff out here.
client-side code in a form:
print(re.sub(r'^\W+|\W+$', '', "últimas", re.UNICODE))
print(re.sub(r'^\W+|\W+$', '', "niño", re.UNICODE))
print(re.sub(r'^\W+|\W+$', '', "vivió", re.UNICODE))
results in
ltimas
niño
vivi
Pretty cut and dried. Here’s how that same code works on my local computer:
últimas
niño
vivió
I typed these characters manually (no copying) with my keyboard, and here’s the unicode inspector results for those characters (proving they’re normal):
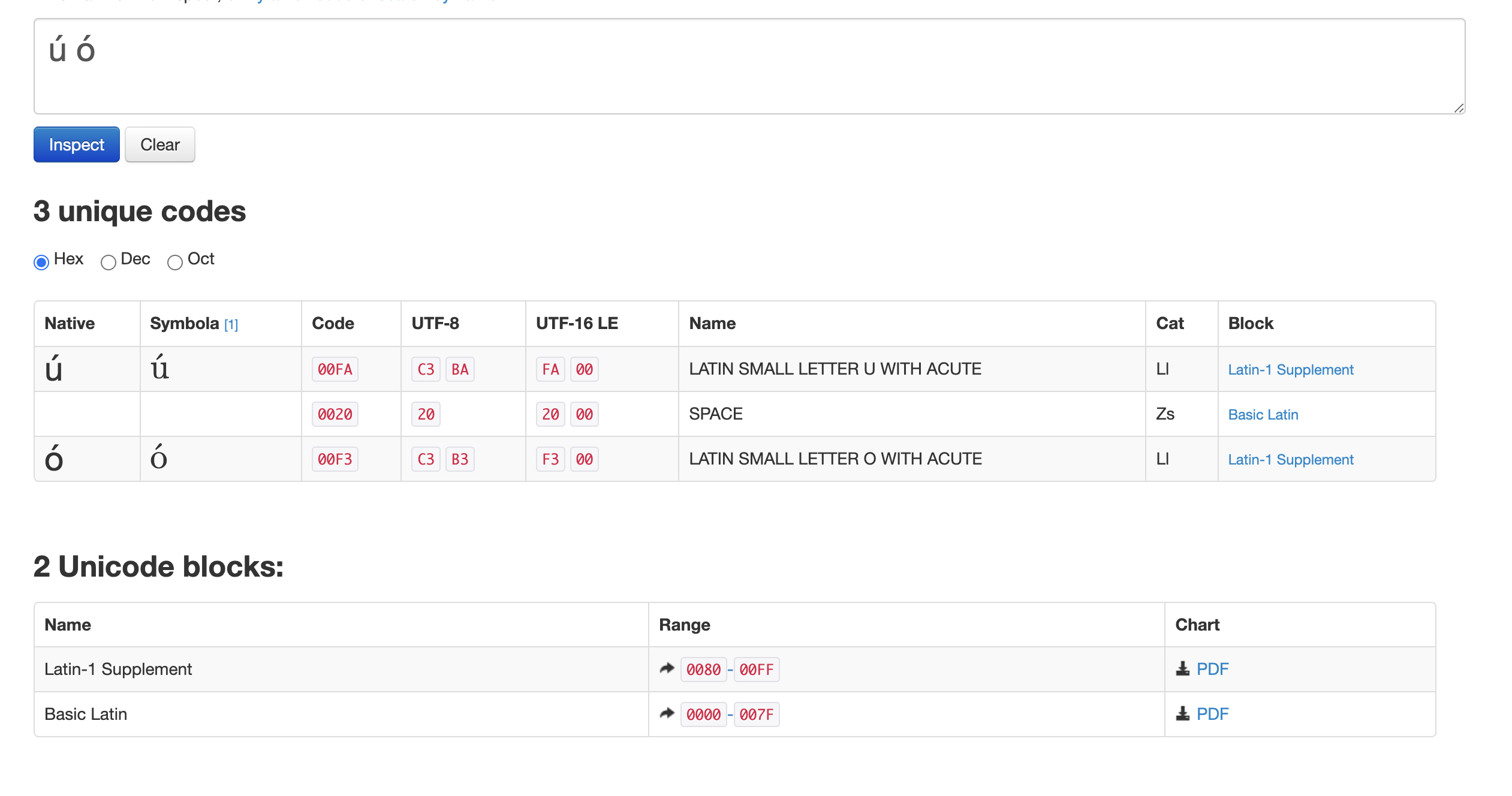
This is decidedly not how the regex module is supposed to work, and should be investigated!
It DOES work correctly if called from server-side.
Without knowing the specifics, I think [OFF-TOPIC] - Regex - strip leading non-numeric chars was on to something and saw the link to [Done] Re.sub in client side - #2 by stefano.menci ; my ultimate request here is either making it clear that the re(gex) module imported client-side does not work correctly, or forbid its usage, or something.