I have been working on Amenity Detection ML Algo. I have the ML code whose input and output both is in the form of photo. I am not able to integrate it. Can someone please help me ?
Hello and welcome!
Is there a way you could provide a bit more detail? For example, how are you integrating this with Anvil?
If you could show a bit of code, or perhaps isolate and explain a specific issue, folks here would be happy to help 
Hey,
So this is the google collab code on Amenity Detection -
https://colab.research.google.com/drive/14nWU0lKCGAsGsL-_OIYUzGKCqA6ye1gy#scrollTo=nCJPjIWv982h
The attached photo is of how I want my app to look like -
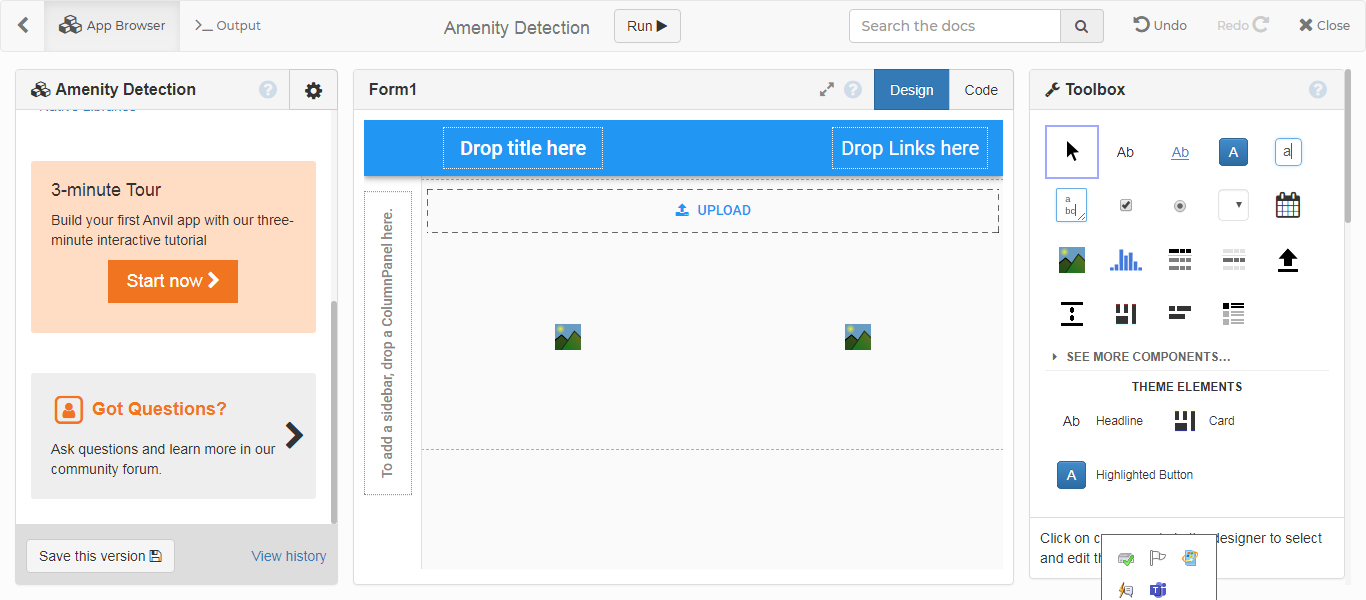
Here the input photo will be uploaded and then after detection from google collab. It should give an output of the detected photo. The two photographs can be seen in the google collab code.
I would recommend using Uplink (more info in the documentation), and checking out this tutorial:
Here, the notebook is Deepnote rather than Google Colab, but the principle is the same.
I hope this helps.
I saw this post. But I wasnt able to understand how will i able to do this in my project. Since I am not very well aware of anvil and app fucntionalities.
I would suggest working through the tutorials here:
This will help you become familiar with Anvil. Eventually you will be able to apply that knowledge to your particular project.
Good luck!
1 Like