Hi
I dont know if any of you are familiar with the Google Gemini API but here goes anyway
basically I have a Gemini API in the server which works
import google.generativeai as genai
from google.generativeai.types import HarmCategory, HarmBlockThreshold
#AI API Key
@anvil.server.callable
def call_ai():
genai.configure(api_key="WILL NOT SHOW FOR OBVIOUS REASONS")
#AI Generator Settings
generative_config = {
"temperature": 10,
"top_p": 0.95,
"top_k": 64,
"max_output_tokens": 150,
"response_mime_type": "text/plain",
}
there is obviously more code than this but you get the point
I called this function from the client and I am able to chat with the AI
but the issue is … ITS TOO SLOW!!!
I think the main reason is because the function keeps configuring a new AI everytime the client calls the function and it takes like 30 seconds for one message
if there is anyone who knows a different method to solve this problem, that would be great
Or, if you don’t want uplink, you can use the persistent server, which is only available in some paid plans. With the persistent server you will be usually (but not always) lucky and your server calls will be managed by a server already configured.
If you’re just playing around with it, I think Uplink is your best bet (assuming you’re not on a plan that offers persistent server), but just to add to the set of options, for a full-scale app that uses an AI backend, a long-running background task that does the AI API calls is the way to go.
That background task configures the client once on startup and keeps it around. The background task can then start a loop that look at data tables to see if there are requests pending, and execute them one at a time.
The server function can insert the requests into the data tables, and then you’d have other server functions the client can use to check on the status of a request.
The background task can manage rate limit issues, can use asyncio if needed, etc. It can get pretty sophisticated as the needs of the app grow. You’re also not limited to AI calls that complete in the 30 second server call timeout window.
Definitely not something to do just to play with AI calls, but if you decide to turn it into a production app for other users, it’s something to consider.
By the way, if you want to go for hosting it elsewhere, you should take a look at Workers AI
It’s basically free for now (even though it says that is has some usage quota but that doesn’t seem to apply to most models). It has lots of models (including Gemma) and the performance is great (Because you get Cloudflare infrastructure).
Although you will have to use it using an HTTP request (and you will have to write some js code for it). I am already using that on my Anvil app so I can help with that if you want.
File "/Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py", line 1352, in connect
self._real_connect(addr, False)
File "/Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py", line 1343, in _real_connect
self.do_handshake()
File "/Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/ssl.py", line 1319, in do_handshake
self._sslobj.do_handshake()
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)
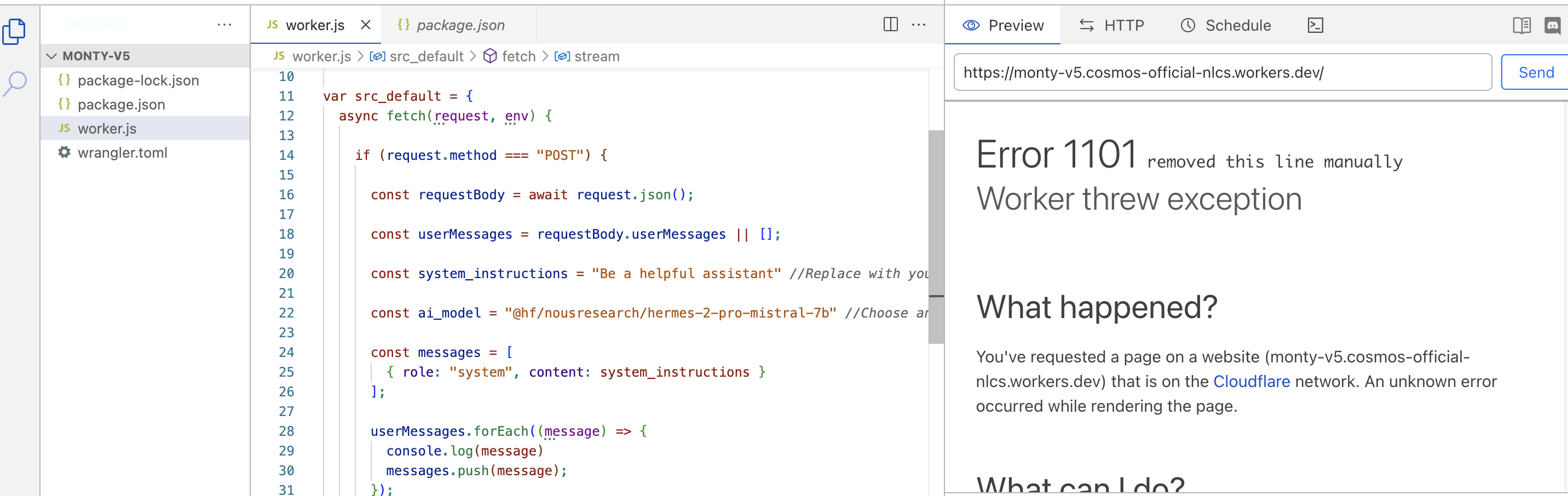
Paste this in index.js. Modify some of the variables to suit your case (check their comments)
var src_default = {
async fetch(request, env) {
if (request.method === "POST") {
const requestBody = await request.json();
const userMessages = requestBody.userMessages || [];
const system_instructions = "Be a helpful assistant" //Replace with your own instruction
const ai_model = "@hf/nousresearch/hermes-2-pro-mistral-7b" //Choose another model ID from https://developers.cloudflare.com/workers-ai/models/
const messages = [
{ role: "system", content: system_instructions }
];
userMessages.forEach((message) => {
console.log(message)
messages.push(message);
});
const stream = await env.AI.run(ai_model, {
stream: true,
max_tokens: 1000, //Adjust accordingly
messages: messages,
});
return new Response(stream, {
headers: { 'Content-Type': 'text/event-stream',
'Access-Control-Allow-Origin': '*',
"Connection": "keep-alive",
'Access-Control-Allow-Methods': 'GET, POST, OPTIONS',
'Access-Control-Allow-Headers': 'Content-Type'
}
});
}
}
};
export {
src_default as default
};
Copy the URL of the worker
Using with Anvil
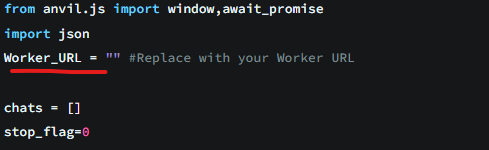
For using this with Anvil you can use the worker_ai_call module in this app Anvil | Login. Replace the Worker_URL variable in the module with your worker URL
There is also an example form for testing the response
Just ignore the preview. It happens because we are not handling any GET request in our worker (which preview makes). But in our app, we are doing a post request.
Try running the clone link I shared and see if the AI is able to give you answers