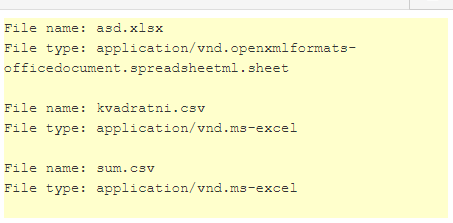
In the screenshot, you can see that I upload one .xlxs, which is the standard excel file and the type is “application/vnd.openxmlformats-officedocument.spreadsheetml.sheet”.
The second and third examples are CSV files where the type is “application/vnd.ms-excel”
However, in the documentation Anvil Docs | CSV and Excel import, it suggests that a CSV file should be of type “text/csv” and the normal excel file should be of type “application/vnd.ms-excel”(In my solution I also use pandas together with anvil.media and the full Python 3 version). Am I doing something wrong here?
The newer xlsx file type is really just an XML file. CSV files can also be opened by Excel, and Excel will sometimes change the MIME type to it’s vendor-specific (vnd prefix) MIME type. Because you know…Microsoft.
You aren’t doing anything wrong. This is a larger issue in the tech world. This StackOverflow post shows that this question can have many answers.
If you want to be “more correct” with your CSV files, definitely always save them with a “text/csv” type. The data people in your life will thank you.
To be honest, I don’t trust MIME types between CSV and Excel. I would use the file extension (CSV vs xls or .xlsx). As you have seen a CSV file can show the wrong MIME type. Blame Microsoft for this.
You could change your code to this and it might work better. It’s certainly not elegant but it might help with your issue.
This of course assumes the person uploading the file named the file correctly. This is not a reliable assumption, but it should work more often than not.
Looking at one of my .xlsx files, the first two bytes are ‘PK’, indicating that it is a zip file. In fact, it opens with 7zip (et al), showing a substantial substructure of folders, containing subfolders and files, only some of which have an xml extension.
Attempting to read an .xlsx as an xml file (e.g., with Python’s standard library) does not look like it’s going to work. But there are other, third-party Python libraries that can read it. Some of them can be found here: Anvil’s List of Packages