I built a data collection app to validate and transcribe audio for training speech recognition models in Mongolian.
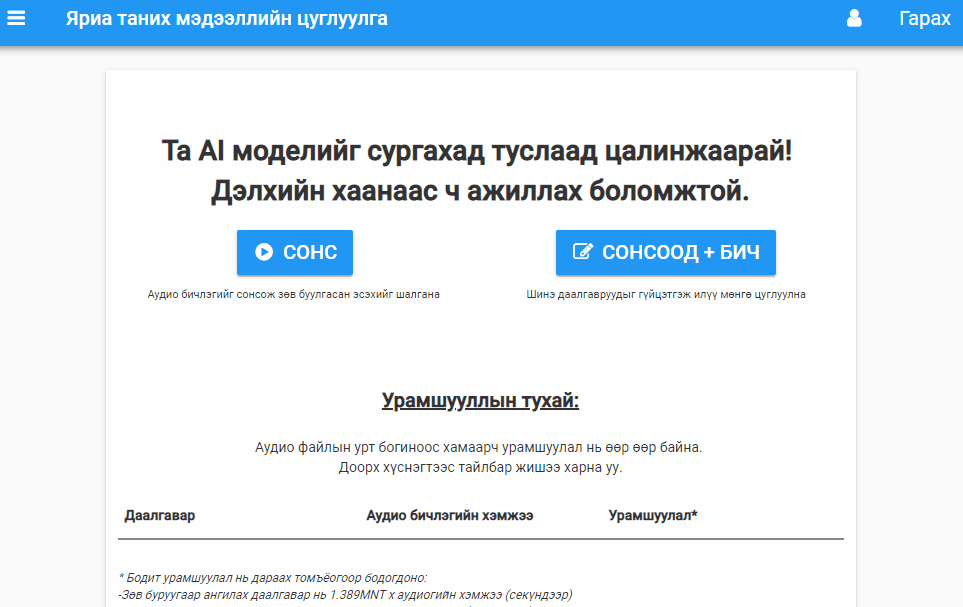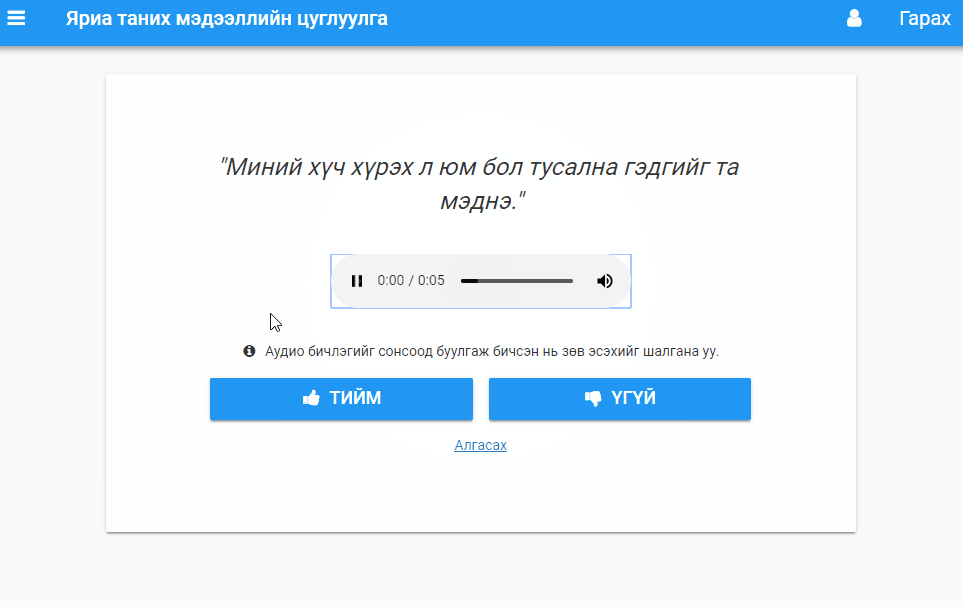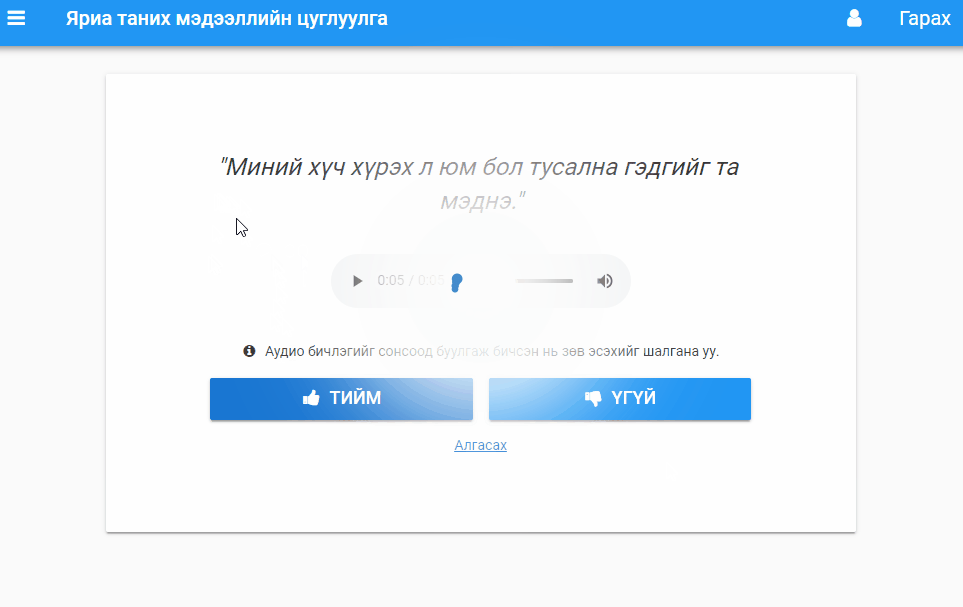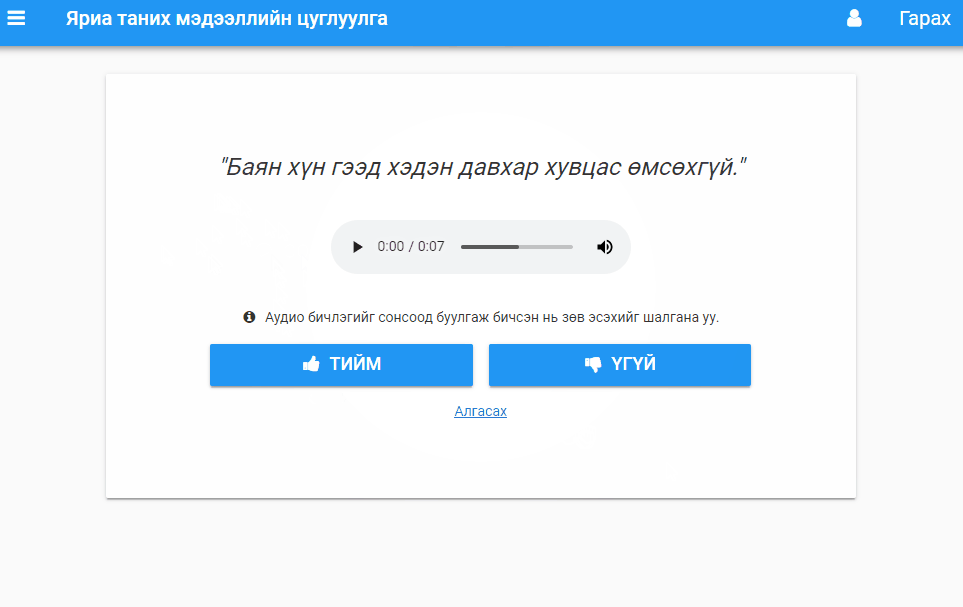
Validation task. Users listen to audio and vote up or down (or skip to the next clip).
Transcription task. Users listen to audio and transcribe in Mongolian. There is a validation function to verify that the input is Cyrillic and not Latin characters (other validation seems to be too time consuming).
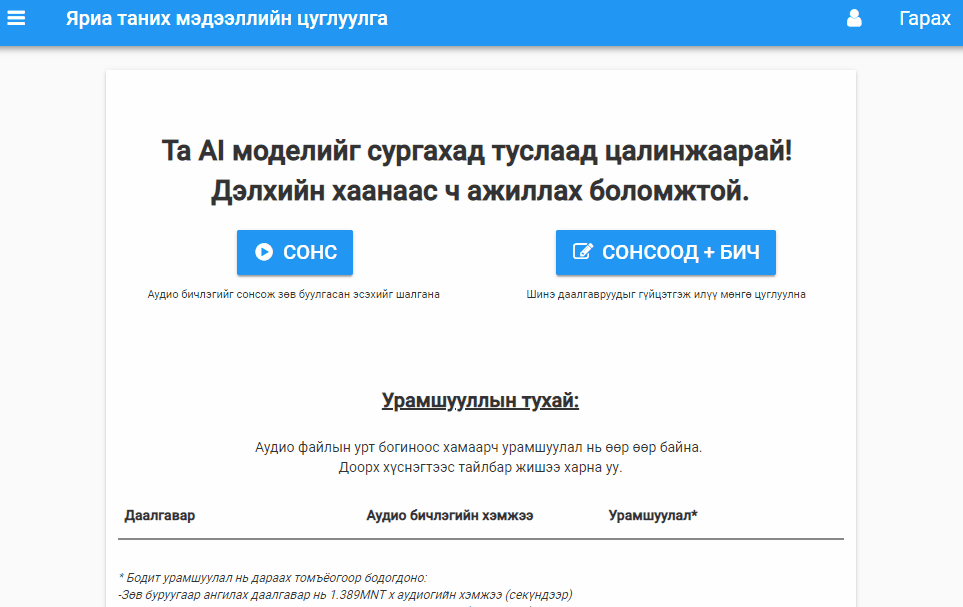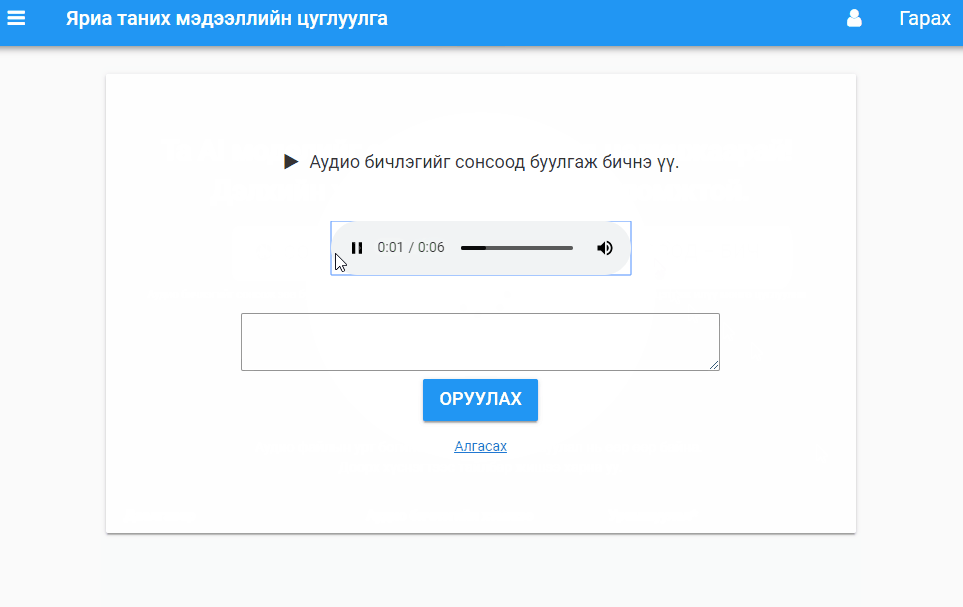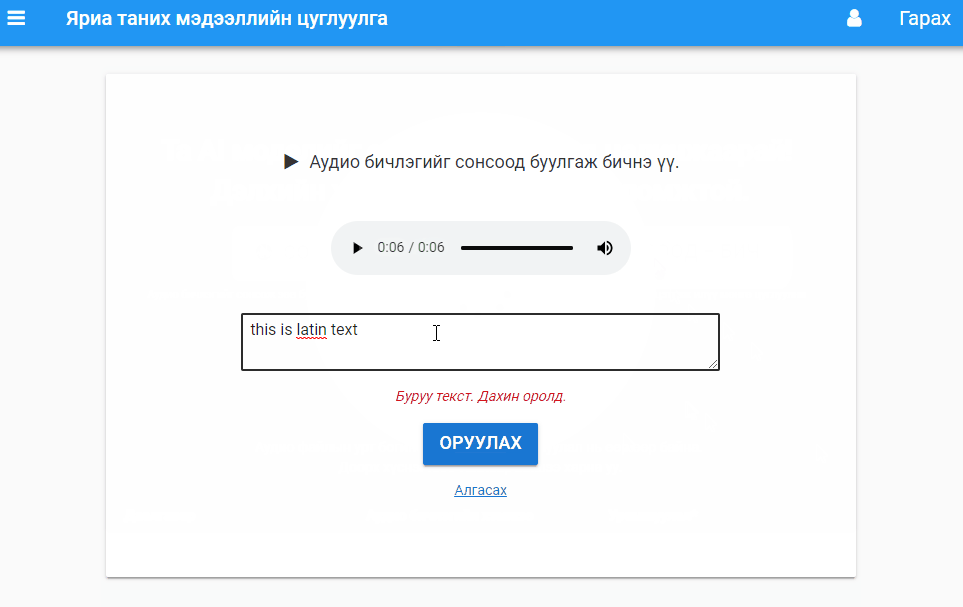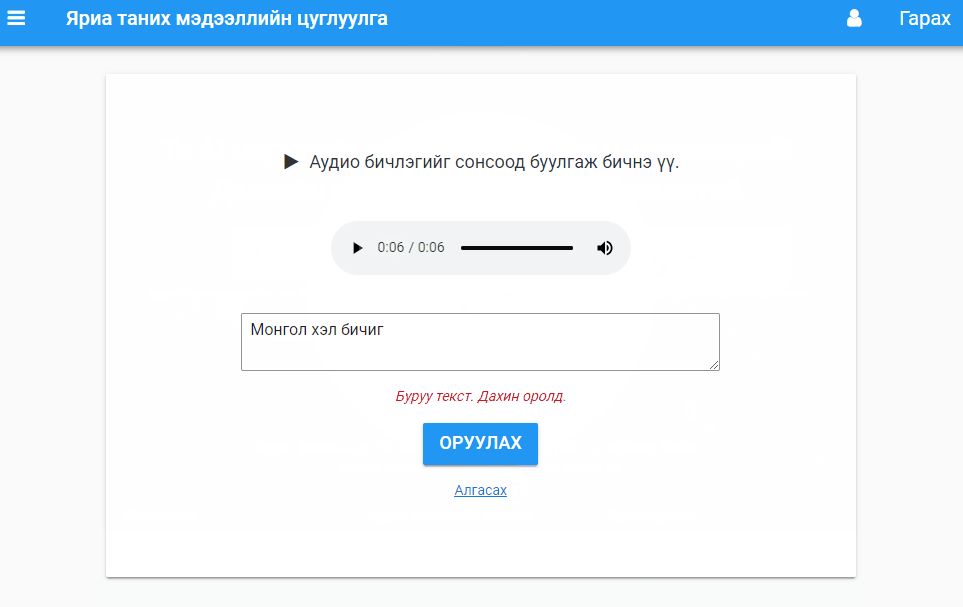
Overall the development process was very quick! I faced two issues when developing this app:
- Forms are based on Python 2.x so unicode strings won’t display unless you declare them as unicode. Ex:
'Монгол хэл'vsu'Монгол хэл'. Easy once I figured this out. - Dynamically updating the source of the audio file seems to only be possible with Javascript, which I had basically no experience with. Luckily some simple StackOverflow searches got me what I needed. Eventually I asked a web developer friend who helped me write it a bit better and ensure the code works in edge cases.
The audio player is a custom HTML form based on the HTML5 audio tag, so it renders different depending on the browser (Edge is particularly ugly, but most look good). All audio is MP3 so it is supported very broadly.
Also, I used the excellent custom login app based on the Anvil tutorial (link) as I needed a login form in another language. I think it may be possible to also provide a translation dictionary, but realized this may not work for translating emails so didn’t attempt it. If it is possible let me know, as it would probably be easier.
Most of the coding was actually on the back end. I had assumed most of the work would be making the front end, but that was actually the easy part (thanks to Anvil). I used an external SQL server and object storage as the size of the data seemed to be a bad idea based on what I’ve read (the dataset will be 100’s of thousands of rows).
All in all a great and fast development experience.