Hi There,
When implementing object detection in a real world application, one must consider the whole pipeline.
And at least in our case the labeling itself had to be integrated seamlessly into the application.
After some unsuccessfull and quite frustrating attempts to include 3rd party labeling tools, I have tried to create one myself.
A few more words on the intention of this component. If you want to simply label an image I’d recommend https://www.makesense.ai/
However if you need an integration of the labeling process this might be your way to start.
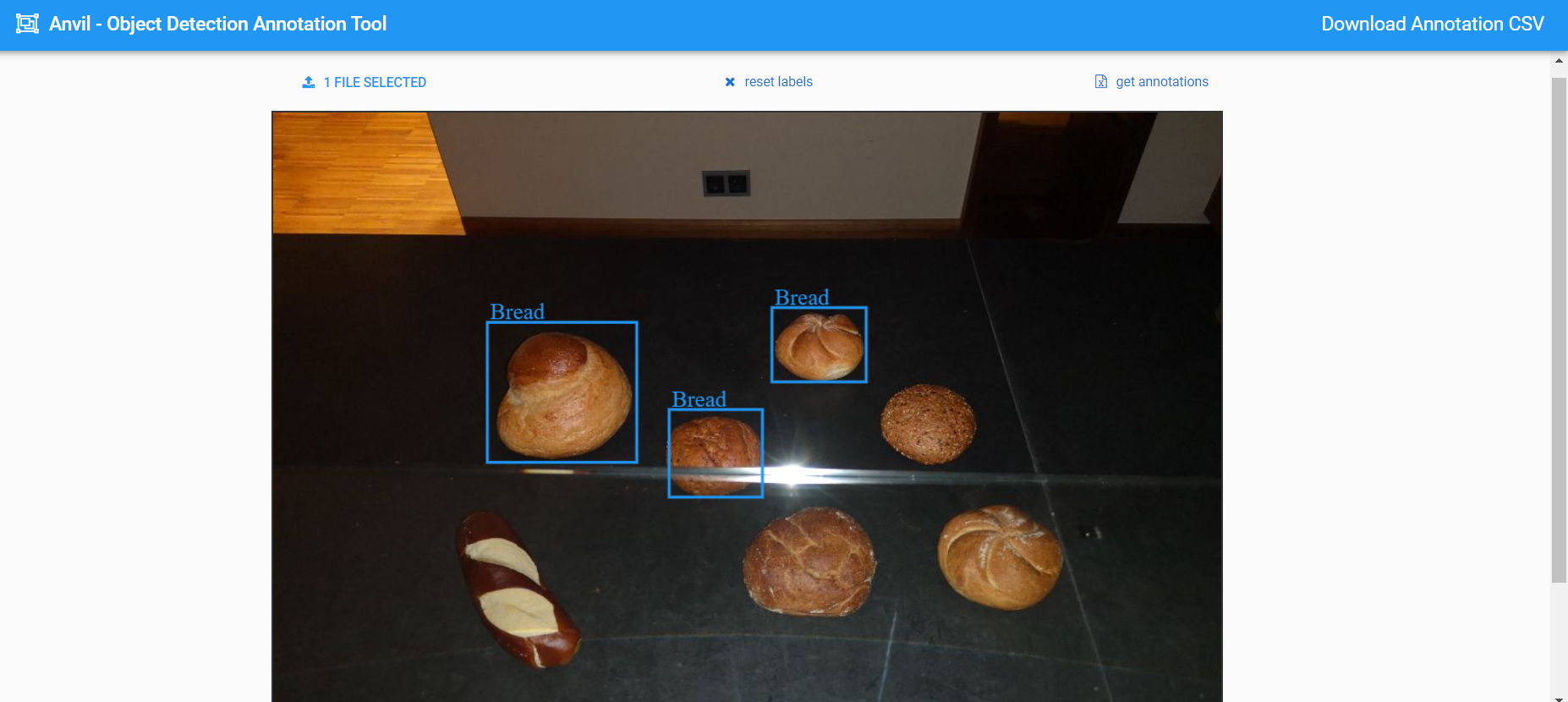
The App below consists of two parts:
The Label Engine is the component wich you can use to start your own object detection tool.
Basically you can set the image and the max size to which the image should be sized and then label it.
With get_annotations() you can receive the object label coordinates.
Further improvements would be to make painted object rectangles resizable. But that a task for another Day(;
The Home Form simply showcases a minimal example on how you could build a computer vision app around the labeling component. You can upload images, annotate them with the label engine and then, with “save annotations” the coordinates and images are stored in the data tables.
If your done, simply click on Download Annotation CSV and the data table is transformed to a CSV with the TF Object Detection CSV Format. https://roboflow.com/formats/tensorflow-object-detection-csv
The “Home Form” could be arbitrarily expanded. One simple approach would be to store images and csv on the google drive, and use an uplink on a local machine to train a model for further inferences.
Which would result in a Computer Vision Pipeline exclusively in anvil.
https://anvil.works/build#clone:SW7T6FDQ6TL2FBLW=EVM2UIY2NKFUNSIEIXIUPAOK
If anyone finds this usefull, feel free to copy, change and add code as you like!
Bye the way, no js was used to create this 
Cheers, Mark