What I’m trying to do:
Run segmentations on CSV imported to data table
What I’ve tried and what’s not working:
Followed the instruction to import a CSV into a data table but get an error on execution. Funny thing is that I can see the data in the data table. Also, need instructions on how to access the data table to perform my models (can’t find tutorials)
Code Sample:
# code snippet
import pandas as pd
import anvil.media
def import_csv_data(file):
with open(file, "r") as f:
df = pd.read_csv(f)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
app_tables.data.add_row(**d)
import_csv_data("data.csv")
Clone link:
https://anvil.works/build#clone:R2ZWFCDCSO2NXCVW=47V3C3ZMZ4AIES3CVM36KQXC
Thank you for answering. The error I was getting was run-time, and the data seems imported.
Regarding the second question. I saw the cat/dog tutorial where someone drops a file (picture) on the app and the model runs. I want to do the same with regressions. Saw that to work with csv files I would need to import them into a table. Am I understanding correctly that to run the model I would need to access the table, or can the notebook access the csv directly? (because the classification accesses the pic directly).
The reason for using a Table is simple: data lifetime. If it’s not saved to a Table, then it disappears as soon as the end-user closes their browser tab.
Now, it’s also possible for the notebook to provide a browser-callable function, which could receive the file directly, without going through a Table. But then, every user of your App could conceivably call that function at any time, day or night, even within milliseconds of each other. So if you want the notebook to handle things on its own schedule, instead of the users’ schedules, then a Table makes a well-organized staging area.
In both cases, your notebook will see the file as an Anvil Media Object. You’ll want to look it up in Anvil’s (excellent!) documentation, to see how your notebook’s code can work with it.
I recommend bookmarking the Docs link at the top of this page, and using the Search features you’ll find here and there. They’re often surprisingly effective.
Thanks for the reply, but I am still overlooking how to have my notebook work with a file. Basically, I need the equivalent of the .read_csv or .read_xls method that allows pandas to read a file. Is this a multi-step process?
I think (possibly) that I was able to work through this problem, but now I’m trying to pass the .describe method and get the following error message “AttributeError: ‘StreamingMedia’ object has no attribute ‘describe’”
This is the code in my notebook
import pandas as pd
import anvil.server
anvil.server.connect(“CCVGNUZUULPYZ32N6TOSIBFW-2XLHIJ52PF7D3LXG”)
import anvil.media @anvil.server.callable
def EDA(file):
“Load and view loaded file”
data = file
print (’\n1. SUMMARY STATISTICS’)
print (data.describe().T.round(2))
print (’\n2. NULL VALUE AND DATA-STRUCTURE REVIEW’)
print (‘number of zero values per column’)
print (len (data) - data.astype(bool).sum(axis=0))
print (data.info())
print (‘Libraries and data loaded’)
data.to_csv(‘Loaded_correctly.csv’)
The problem is one of type. file is receiving a value of one type; data is receiving a value which is the exact same object, so its value has the same type; but the value you want is of a different type, a type that has a function member named describe.
So the puzzle, now, is how do you convert a value of the type you’ve got (StreamingMedia) into a value of the type you want. We can think of this a building a bridge. There are two anchor points: the known features of the type at the start-end of the bridge, and the features of the type at the destination-end of the bridge.
StreamingMedia, for me, is a partially-known quantity. It is documented at Files, Media and Binary Data. Like a file on disk, it contains a sequence of bytes. It can expose those bytes to your code as an object of Python type bytes.
I don’t know what type you want it converted into. Does that type have a way to read a bytes object directly?
Typically, it is a multi-step process. Anvil provides objects of its own types. These can be converted into objects of more generic Python types. With any luck, you can convert one of these more-generic objects into something of the type you actually need.
I see. Basically, I need to use pandas and other python libraries on a csv. Do you think this could be solved by loading the file into a data_table? I also attempted this but think I need the converter-bridge you mention, but it shouldn’t be that difficult because the tutorial " Turning a Jupyter Notebook into a Web App with Anvil" states that a notebook can access data_tables.
A Jupyter Notebook, running a Python program, can use Anvil’s Uplink to access Anvil’s data tables. That could solve other problems, but it isn’t a “magic bridge” for this problem.
Building this bridge is a little like a puzzle. We have a “starting” data-type, and an “ending” data-type, and we’re looking for a step-by-step way to convert a value of the 1st type into a value of the 2nd type. There will almost certainly be other data types along the way.
I have no direct familiarity with Pandas, but it should have a way to read a file-like object, to produce a value of the 2nd type. That’s half of the bridge. I think I can provide the other half.
Edit: For what it’s worth, this is a fairly common condition in Python. Library X’s data types do not (and should not) know anything about Library Y’s data types, and vice versa. But both of them know about Python’s “native” data types. So we can use these “native” types as a bridge.
I saw that it can be done in the server module. In principle, it should meet my needs if I can deploy from there. What concerns are there on scaling from it?
Anvil almost certainly has many more computers available than you do. So it should scale to more users, and more simultaneous users, fairly well. Anvil’s machines also run 24/7, which is a lot harder to guarantee for any personal computer.
Compute time is probably not an issue. If jobs take long enough to time out, then you can convert them into Background Tasks.
For a large enough job, memory space might become an issue. Right now that seems unlikely, to me, but I don’t know the size of your data sets. If you suspect that this might become an issue, then consider how you might work around it.
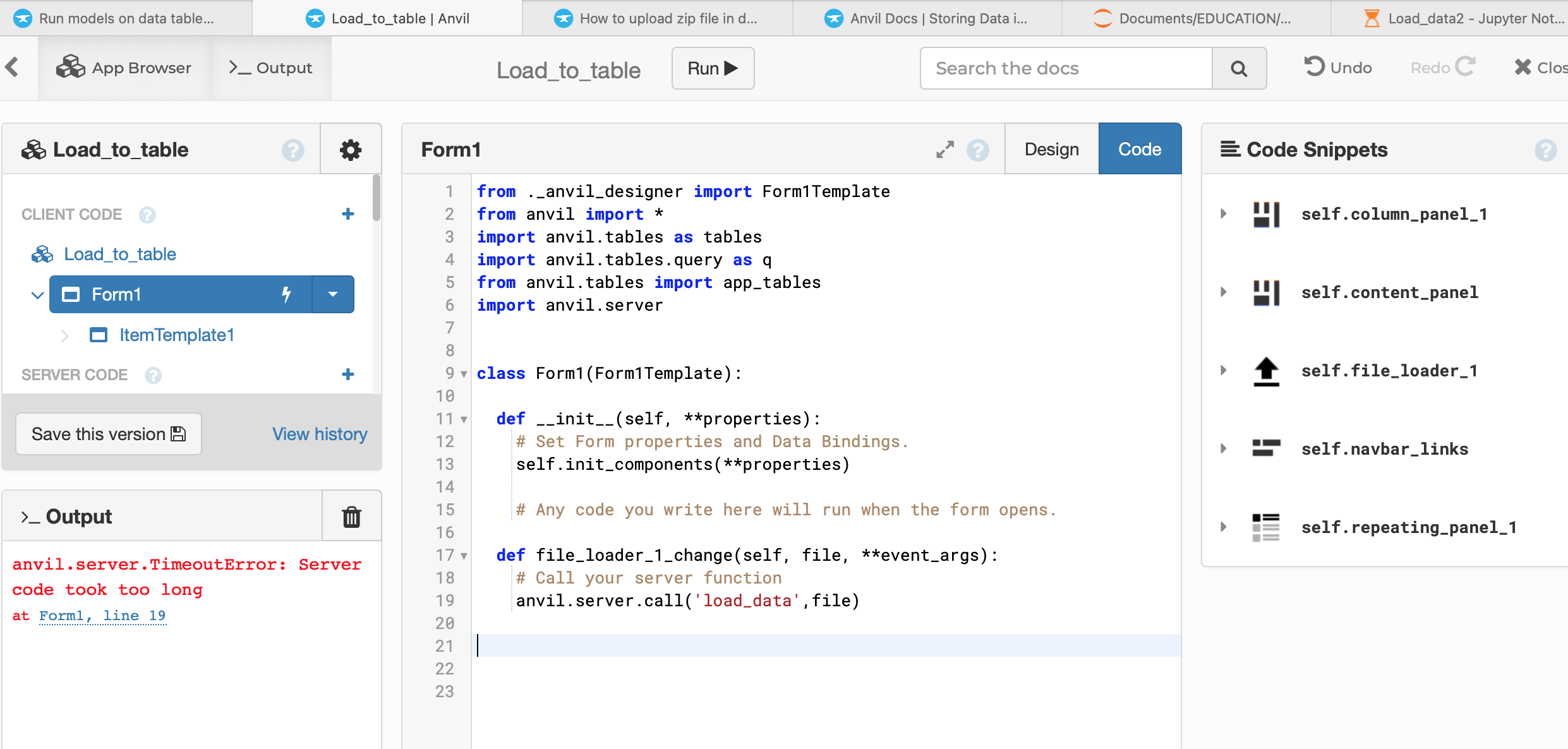
Hi Brooke, I’m rather new at this so most probably the data was loaded incorrectly. I made some progress today in loading a CSV into a data table but got a run-time error. I’m loading a 5000 by 14 CSV, which should be commonplace. I believe I just need to link the notebook to the app with the uplink and include a @anvil. server.callable instruction, right? I’ve also read in the documentation that notebooks can access data tables like a SQL database, but that’s a different plan than I’m in. I followed some of the tutorials but it seems I am not finding the correct one. Could you point me to the right one, please?
I’m including a screen pic of the error and a link to my app.
Pandas has different methods to look at data, mostly as a dataframe, and can change its data-type. What should it be converted to, and what does the-second-half of the puzzle look like.
I don’t understand. I opened a question on how to access data-tables from my notebook and you answered about a multi-step bridge… I was following-up on you starting vs ending data-types comment.