I have just come across a strange error with Anvil when trying to directly load it from http endpoint.
So my basic idea is to return the entire HTML source code of my Anvil app from an HTTP endpoint (See Browser Routing (React - like) for Anvil Apps for more)
So far, everything has been working succesfully. However, it appears that any row that I get on client side from the data table does not work. I get an error saying that the row is from an expired session. However, if I fetch the same row from a server call, I am able to work with it.
I know that this error happens due to the absense of anvil session cookie when loading app from an HTTP endpoint.
Steps to Reproduce
- Go to
https://quintessential-meaty-frog.anvil.app . You will see that the value is fetched from both client side query and server side.
- Now go to
https://quintessential-meaty-frog.anvil.app/_/api/app . You will see that the value from row returned through server call is displayed but an error occurs when displaying it from client side (Make sure that you visit from a private window or clear your cookies otherwise the previous session cookies may still be there)
And here’s a clone link Anvil | Login
My guess is it’s a security feature ngl. Is there a reason you need to get the row specifically from the client rather than the server?
Mostly just for faster access (I only give permission to data why is not sensitive).
But if it’s a security feature, why allow server calls to be made.
This is not an answer, it’s just a comment made with the assumption that you are talking about a form with access to the data tables.
If my assumption is wrong, then I misunderstood the question and you can ignore this.
Giving a form access to a table is often slower than doing a server call. When the form has direct access, it tries to do its best, guessing what you need when you need it, and sometimes things go wrong and it ends up doing many useless roundtrips. If you make one server call to get what you want, you have better control over what’s going, you can collect all you need and pass it back to the client in one single roundtrip.
Server calls call a function, and the function decides what the client can do.
Giving direct access to the table doesn’t allow you as much freedom to fine tune what the client can do.
An hacker in front of a form with access to a table could delete the content of the table, even if the code in the form wouldn’t do that.
Thanks for your opinions.
I have also tried the single call approach you mentioned earlier during development and concluded that it wasn’t suitable.
Why?
Maybe its the nature of my app. For starters, lets just discuss the problem in home pages. In my home page, I want to display books in (lets assume n) categories.
If I make a single server call that fetches all records for those n categories, maybe the overall time will be faster but the user will have to stare at a blank screen for a long time.
Instead, if I execute this queries one-by-one, the user will keep getting new content to browse. And most likely, by the time he finishes checking out category a, category b would have been loaded. Even though the loading time will be more, the user will still not be kept waiting.
And I only give read access to my data tables (and only some of them).
In cases like this I have a server call that fetches a variable number of items.
The form_show event fetches a small number of items and shows them immediately, then either the tick event of a timer or the mouse wheel event will read another number of rows. I just went back and searched a post where I describe something similar, and look, you contributed to it too, thank you!! 
This would ensure one roundtrip only for the first items to be displayed and a second trip for the remaining items. There will never be additional trips done at the whim of the logic behind the row objects.
But you already knew this, my old post has your very own contribution, so if you think it’s unsuitable for your current use case, well, I’m sorry I don’t have an answer.
Actually I just got curious and ran some tests for running the same query on client and server
Client seems like the winner here (Although the server is unstable and sometimes give more faster results than client, possible due to varying ongoing sessions)
I am not sure if I did something wrong here though
Here are some result screenshots
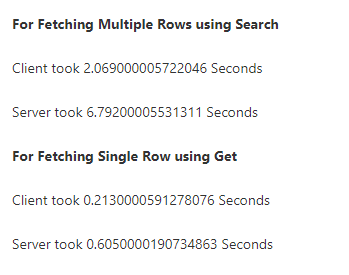
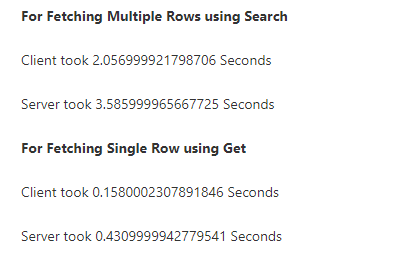
Anyway, I think we are drifting away from the main purpose of this post.
Your time measurements only look at a search and don’t use the result of the search.
If you try to use just a copule of rows, you see that server calls are already twice as fast, regardless of whether you use accelerated tables or keep server running.
This test shows exactly what I was talking about: row objects and table iterators are very well optimized, and they often do a good job at guessing what you need. But as soon as you need something slightly different from their guesses, their performances can kill your app and be orders of magnitude slower than server calls.
Here I have added my version of server call, where I return dictionaries instead of row objects, and you can see that with just 2 rows we are already twice as fast:
no accelerated tables - no keep server running
Client took 3.200999975204468 Seconds
Server took 4.150000095367432 Seconds
Server2 took 1.480000019073486 Seconds
Client took 0.2909998893737793 Seconds
Server took 0.5590000152587891 Seconds
Server2 took 0.3329999446868896 Seconds
no accelerated tables - yes keep server running
Client took 3.216000080108643 Seconds
Server took 3.745999813079834 Seconds
Server2 took 1.233000040054321 Seconds
Client took 0.5090000629425049 Seconds
Server took 0.4000000953674316 Seconds
Server2 took 0.4110000133514404 Seconds
yes accelerated tables - no keep server running
Client took 2.898000001907349 Seconds
Server took 3.594000101089478 Seconds
Server2 took 1.364000082015991 Seconds
Client took 0.1559998989105225 Seconds
Server took 0.3919999599456787 Seconds
Server2 took 0.4040000438690186 Seconds
yes accelerated tables - yes keep server running
Client took 3.368000030517578 Seconds
Server took 3.846000194549561 Seconds
Server2 took 1.38100004196167 Seconds
Client took 0.2170000076293945 Seconds
Server took 0.6310000419616699 Seconds
Server2 took 0.4000000953674316 Seconds
Here is the server code:
@anvil.server.callable
def return_rows():
return app_tables.table_1.search()
@anvil.server.callable
def return_row():
return app_tables.table_1.get(someid=1)
@anvil.server.callable
def return_rows2():
return [dict(row) for row in app_tables.table_1.search()[2:3]]
@anvil.server.callable
def return_row2():
return dict(app_tables.table_1.get(someid=1))
And here is the client code:
def form_show(self, **event_args):
summary = []
start=time.time()
rows=app_tables.table_1.search()
x=[dict(row) for row in rows[2:3]]
print('1==============')
print(x)
end=time.time()
summary.append(f"Client took {end-start} Seconds")
start=time.time()
rows=anvil.server.call('return_rows')
x=[dict(row) for row in rows[2:3]]
print('2==============')
print(x)
end=time.time()
summary.append(f"Server took {end-start} Seconds")
start=time.time()
rows=anvil.server.call('return_rows2')
print('3==============')
print(rows)
end=time.time()
summary.append(f"Server2 took {end-start} Seconds")
start=time.time()
row=app_tables.table_1.get(someid=1)
x=dict(row)
print('4==============')
print(x)
end=time.time()
summary.append(f"Client took {end-start} Seconds")
start=time.time()
row=anvil.server.call('return_row')
x=dict(row)
print('5==============')
print(x)
end=time.time()
summary.append(f"Server took {end-start} Seconds")
start=time.time()
row=anvil.server.call('return_row2')
print('6==============')
print(row)
end=time.time()
summary.append(f"Server2 took {end-start} Seconds")
print('\n'.join(summary))
EDIT
If the IDE showed all the roundtrips, including the ones triggered when accessing a value in a row object when the row object already exists on the client side, but needs a roundtrip to fetch a value, one would have an idea of whether using row objects on the client is slowing down the app and should be optimized by using static dictionaries as in my example, or they don’t trigger too many roundtrips and can be used because they make the code more readable.
Nice observation there.
But even in your code, client is still faster in some cases. Also, returning the row as a dictionary is not always possible (at least in my case because there are some simple object columns that take time to load and I don’t want them to be loaded unless needed.
What I mean is, there is not a single solution that fits all cases.
Also, I checked out your feature request and it definitely seems like a useful suggestion.
And moving back to the topic, still wondering if there is any way to manually “create a new session” when using http endpoints.
With server calls you can decide what to put in the dictionaries, with row objects you have some control, but it is at best as good as server calls.
At the end of the day you need a certain amount of data to travel from the server to the client. You can do it in one shot when you know you need it, or you can do it when the app thinks you need it, and end up splitting it in little chunks.
There may be reasons why row objects would be faster, but I doubt it. For example without persistent server, but my little test with a minimal app didn’t show any difference. It would be interesting to put the test inside a real app with large imports and test it with persistent server vs without.
I know this is not an answer to your question. But considering that the way you are using the app is not as intended, maybe switching from row objects to dictionaries would solve the problem and speed up the app. I obviously understand that “why is the app broken” shouldn’t be answered with “write another app”, but this is the only answer I have.
1 Like
This is often the only pragmatic answer. The more complex a library, and the more moving parts (internet infrastructure) that sit between it and the app developer, the more variables there are, outside of your own control, and the less reliably you can reason about the results. It’s easy to “deduce” things about the underlying machinery that aren’t entirely reliable, due to those other variables, or limitations of the tests.
Basing a design and implementation on those deductions is entirely understandable. But when the observed system behavior stops matching those deductions, then perhaps it’s time to revisit those deductions, and perhaps some parts of the design. I’ve had to do this on many occasions as I gained more experience with Anvil, and with other systems long before that.
1 Like