Hi all,
I am bit of a python newbie and I have been finding the anvil community forum a huge help on my learning journey. (A massive shout out to @nickantonaccio for his 'Learn the Python Anvil Framework tutorial/bible - this really helped to get me started).
I’m currently playing around with an app that pulls data from an external data source based on a keyword search entered by the use. It then stores the retrieved data frame in a datable. I have had success with this part, however, what I am finding is that I am creating a lot of duplicates rows in the data table when subsequent searches are executed and added to the table.
If the data was in a dataframe I could use, for example,
df.drop_duplicates(subset=['ID'])
Is there an equivalent method I could use for searching the data table? I’ve had a look around the forums and tutorials and I can’t see anything but I apologised if I have missed something.
You could also take the approach of filtering after pulling from the external source, but before adding to the data table. That way you never add the duplicates in the first place (assuming that’s the goal).
The general logic would be:
results = fetch from external source
for result in results:
row = app_tables.whatever.get(keyfield=result['keyfield'])
if not row:
app_tables.whatever.add_row(fields filled out from result)
Thanks @jshaffstall, I did consider this but the challenge I have is it is usually subsequent searches that are causing duplicates to be added.
So Search1 pulls in unique data with no duplicates within the results and these are then added to the data table.
Search2 pulls in new data and whilst there are no duplicates within the results of Search2 there may be some rows that are duplicates of Search1 which would only become apparent when they are added to the data table.
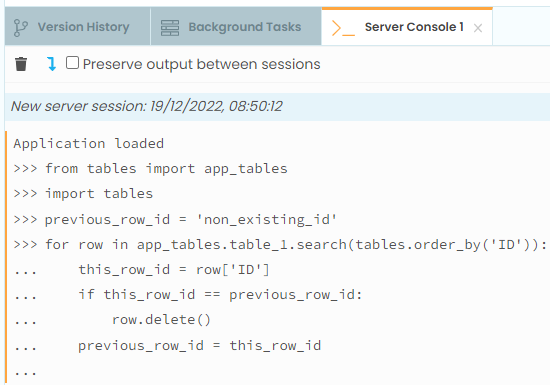
Thanks @stefano.menci and @p.colbert for your responses. I did look at queries but couldn’t get my head around how I would make it work. I will have another look and consider how I may sort by ID and delete as suggested.
The algorithm I posted handles this case. The search for duplicates is not within the search results, but the entire table. The results of Search2 would still be unable to add duplicates (based on whatever key field you use in the app_tables.get call) to the data table.
Ah, I’m showing my ignorance! Thank you so much, this does exactly what I need it to do!
I’ve slightly amended it to check for 2 columns, if both columns match it doesn’t add it to the table, if only one does then it still adds it. You’ve saved me many hours so thanks again.