Is the issue retrieving the file from the database or that the Media Object you get from it doesn’t behave like the TempFile? Or is it an issue with querying based on the file_object?
Update: I made some modifications to your function and used the url property instead of a TempFile.
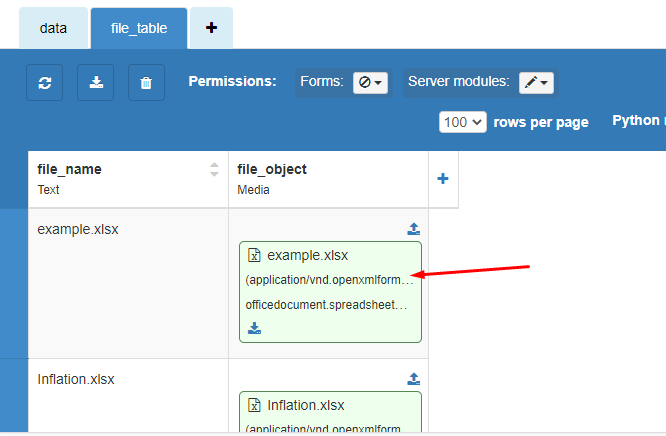
(My DB Table only has a file_object file, and you can’t query on Media Columns)
@anvil.server.callable
def read_csv():
file = app_tables.table_1.search()
file = [f['file_object'] for f in file if f['file_object'].content_type == 'text/plain'][0]
print(file.content_type)
if file.content_type == 'text/csv':
df = pd.read_csv(file.url)
elif file.content_type == 'text/plain':
df = pd.read_table(file.url)
else:
df = pd.read_excel(file.url)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
# app_tables.data.add_row(**d) This Outside
print(d)
pass
dft = pd.DataFrame.from_dict(df) #New line for read the file
print(dft)
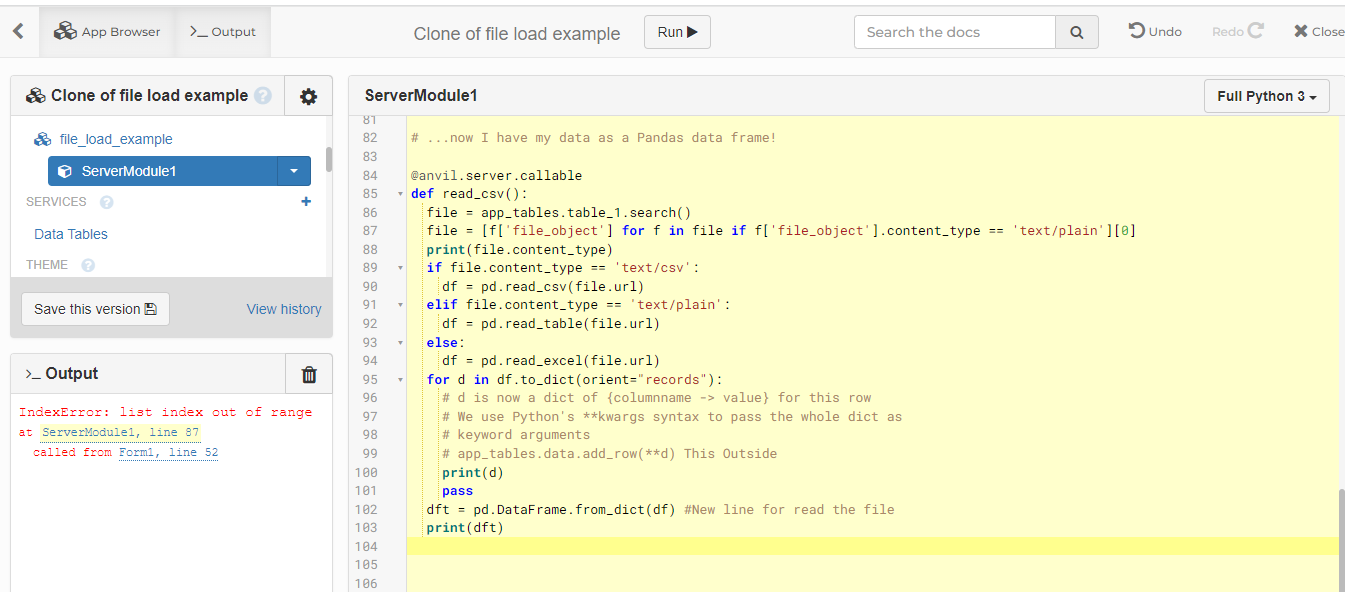
The problem is to recover the file from the database in order to transform it into a Pandas dataframe. I have tried to replicate your code in the application (database included) and I get an error message:
The error is because you kept the if statement in the list comprehension so it only gives you text files while not.having any in your db. if you remove that it will work. For actual data querying, you’ll wanna have some text column to search on, with some query as an argument in the search function like q.full_text, q.ilike, q.like, etc.
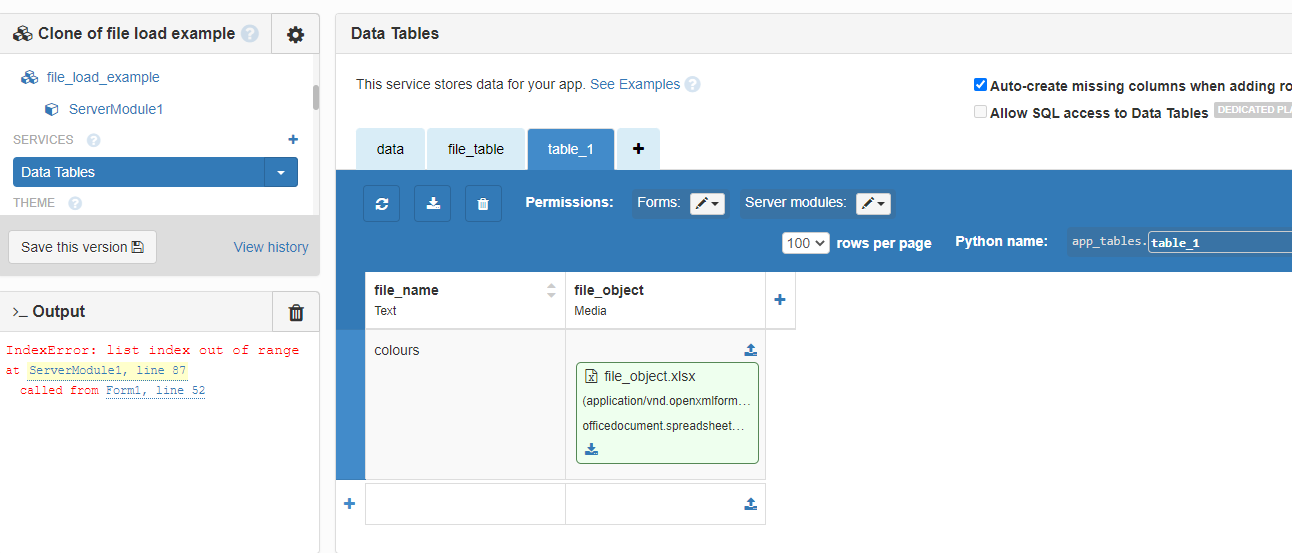
Thank you for your response. But I have removed the if’s and it doesn’t work.
@anvil.server.callable
def read_csv():
file = app_tables.table_1.search()
file = [f['file_object'] for f in file]
df = pd.read_excel(file.url)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
# app_tables.data.add_row(**d) This Outside
print(d)
pass
dft = pd.DataFrame.from_dict(df) #New line for read the file
print(dft)
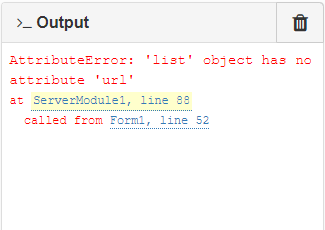
Oh, it also looks like file in this case is a list, so I’m not sure why any of that is being done.
this whole thing should probably be like:
@anvil.server.callable
def read_csv():
for row in app_tables.table_1.search():
file = row['file_object']
df = pd.read_excel(file.url)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
# app_tables.data.add_row(**d) This Outside
print(d)
pass
dft = pd.DataFrame.from_dict(df) #New line for read the file
print(dft)
It looks like pandas is having trouble reading data from the url of the media object in the database, but I don’t know how or what pandas does with a url
Obviously from the error it is passing it to pythons requests library, but I don’t know what else.
Also, I just noticed I’m the one who created this file load example
#put this at the top with the imports:
import io
@anvil.server.callable
def read_csv():
for row in app_tables.table_1.search():
file = row['file_object']
f = io.BytesIO(file.get_bytes())
df = pd.read_excel(f)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
# app_tables.data.add_row(**d) This Outside
print(d)
pass
dft = pd.DataFrame.from_dict(df) #New line for read the file
print(dft)
This works because io.BytesIO() takes a bytes string from the media object and turns it into an object that looks like a file to pandas. (It loads a file-like object in memory instead of the disk)
For what it’s worth for future reference, the url property of a Media object fetched from a data table is a special URL only good for the current browser session. The way Pandas is using that URL is probably not counted as being in the current browser session, so the URL doesn’t resolve.
That makes alot of sense.
If you even wanted to get it to work, you might have to fiddle with using the python requests library, passing around SSL certificates, cookies, credentials etc, and if you got that to work, the point of using pandas to read a url string (for ease of use) goes out the window.
I think pandas can work with the url property, but it definitely struggles with it: I got it to work, but was definitely plagued by intermittent 400 errors