Very likely the value you pass to the function do not match any of the rows, so row is None row['Name'] fails because “‘NoneType’ object is not subscriptable”.
1 Like
Here’s a solution with no data tables required (using a random list of 50000 randomly generated ‘names’ (just random strings 4-10 characters long)):
https://anvil.works/build#clone:I4NOPEMWVKYSINZR=XLP4HINEDNVMWUSZCJYIR3U3
Names are simply stored in a list of lists in a server module, with each sub-list containing name, gender, and count:
[[‘Jane’, ‘female’, 5], [‘George’, ‘male’, 8], ['Bill, ‘male’, 6]]
This example shows how the random names were generated, along with the full logic:
import random
import string
namelist=[]
for i in range(100000):
name=''.join(random.choice(string.ascii_letters) for i in range(random.choice([4,5,6,7,8,9,10])))
gender=random.choice(['male','female'])
amount=random.choice([4,5,6,7,8])
namelist.append([name, gender, amount])
# print(namelist)
gender='male'
length=4
amount=6
first_letter='a'
possible_list=[]
for name in namelist:
if (
gender==name[1] and
amount==name[2] and
first_letter==name[0][0] and
length<=len(name[0])
):
possible_list.append(name)
print(random.sample(possible_list, 1))
1 Like
I could fix the error with “None Type”, however, there is another issue.
With the server function
@anvil.server.callable
def name_function(letter, length, gender, amount):
row = app_tables.names.get(
Gender=gender,
Anfangsbuchstabe=letter,
Laenge=length)
name_list = row['Name']
return random.sample(name_list, amount)
I only get returned letters instead of words.

I guess this is because I uploaded lists of names in my Data Table.
If I return the entire name list it looks like this:
@anvil.server.callable
def try2(letter, length, gender, amount):
row = app_tables.names.get(
Gender=gender,
Anfangsbuchstabe=letter,
Laenge=length)
name_list = row['Name']
return name_list

Any idea how I can solve this so that I get random names instead of letters?
app_tables.names.get returns 1 unique row.
row[‘Name’] returns the name field from that row.
In your data table, the ‘Name’ column is currently set up as a field of type ‘Text’, so random.sample(name_list, amount) returns random characters from that text string.
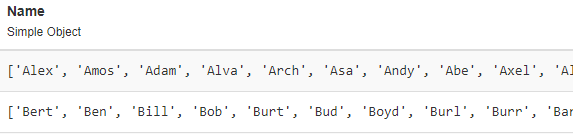
The ‘Name’ column needs to be set up as a field of the type ‘Simple Object’


In the simple object column you need to store the list, not the list converted to a json string.
Sorry I don’t understand. I uploaded the names as lists from a Python Script with the help of Uplink.

The code in the Python Script:
def import_excel_data(file):
with open(file, "rb") as f:
df = pd.read_excel(f)
for d in df.to_dict(orient="records"):
# d is now a dict of {columnname -> value} for this row
# We use Python's **kwargs syntax to pass the whole dict as
# keyword arguments
app_tables.names.add_row(**d)
import_excel_data('Names.xlsx')
What do I need to change?
I don’t know what’s on your Excel file and I don’t know what pd.read_excel does, so I don’t know what to fix.
But I’m guessing that your Excel file has a column with strings containing the representation of a list of names and you are writing that string (not that list of names that it represents) on the simple object column in Anvil.
Here l is a list of names, while s is a string that looks like the representation of the list of names, and can be converted to a list of names with the json.loads:
l = ['joe', 'mary']
s = '["joe", "mary"]'
print(json.loads(s))
I think we are getting closer.
I tried
@anvil.server.callable
def try2(letter, length, gender, amount):
row = app_tables.names.get(
Gender=gender,
Anfangsbuchstabe=letter,
Laenge=length)
name_list = row['Name']
converted_list = json.loads(name_list)
return random.sample(converted_list, amount)
But this leads to the error:
JSONDecodeError: Expecting value: line 1 column 2 (char 1)
Try to print(name_list) before the error to see what’s in it.
… but I would do the conversion before writing to the datatable. Better than writing a text on a table and then converting it from string to list of strings every time you read it.
1 Like
Check that there are no quotes around the list in your ‘Name’ column…
1 Like
JSON requires double quotes, while your string (as shown in your data table image) is using single quotes.
1 Like
So I finished the Name Generator and it works eventually. Thank you everybode for your help in various ways.
While the running time of the app is all right I am sure that the code can be improved. I am very thankful for any advice on how my code can be optimized.
The code I used looks like this.
Server:
from anvil import *
import anvil.tables as tables
import anvil.tables.query as q
from anvil.tables import app_tables
import anvil.server
import random
import json
import re
@anvil.server.callable
def name_function(letter, length, gender):
row = app_tables.names.get(
Gender=gender,
Anfangsbuchstabe=letter,
Laenge=length)
name_list = row['Name']
name_list2 = re.sub("\'", '"', name_list)
converted_list = json.loads(name_list2)
return random.sample(converted_list, 5)
Client:
from ._anvil_designer import Form1Template
from anvil import *
import anvil.tables as tables
import anvil.tables.query as q
from anvil.tables import app_tables
import anvil.server
class Form1(Form1Template):
def __init__(self, **properties):
# Set Form properties and Data Bindings.
self.init_components(**properties)
# Any code you write here will run when the form opens.
def button_1_click(self, **event_args):
result = anvil.server.call('name_function',
letter = self.letter.selected_value,
length = self.length.selected_value,
gender = self.gender.selected_value
)
self.results.text = '\n'.join(result)
One mini improvement is on the string replacement: I think that name_list.replace would do the same job as re.sub, but much faster. If it was called thousands of times in a loop, this could have a noticeable performance hit. Here you have only one call with a long string, it may be fast, but I wouldn’t bother re for this simple replacement.
One bigger improvement is on the column type: It looks like your Name column is a string column containing a list of strings delimited by single quotes, and you always convert the single quotes to double quotes, then parse the string into json.
If you make that a simple object column, you can convert this:
into this:
return random.sample(row['Name'], 5)
Using a simple object column is cleaner than using a text column and converting to json. Cleaner code always wins, unless it’s very slow and it bothers you. You could test the speed of the two solutions and go with the fastest, but I have the feeling that simple object columns are going to be faster.
3 Likes
Many thanks for highly appreciated help.
If I change the code to
return random.sample(row['Name'], 5)
I again get only five starting letters of names.
Remember that I had to upload my names as list of strings in a Python Data Frame due to the limit of 50K rows in the free version.
Regarind the suggestion with “replace”: This sometimes yields the error message
JSONDecodeError: Expecting value: line 1 column 32768 (char 32767) at /lib/lib-python/3/json/decoder.py, line 231 called from /lib/lib-python/3/json/scanner.py, line 40 called from /lib/lib-python/3/json/scanner.py, line 67 called from /lib/lib-python/3/json/decoder.py, line 355 called from /lib/lib-python/3/json/decoder.py, line 339 called from /lib/lib-python/3/json/init.py, line 361 called from [ServerModule1, line 19](javascript:void(0)) called from [Form1, line 17](javascript:void(0))
This happens if row['Name'] is a string.
If you delete the text column Name, create a new simple object column Name and populate it with lists of strings, then it will work.
Populating it with a list of strings means something like this:
names = ['Joe', 'Jim']
app_tables.names.add_row(names)
Looking back to this post, I guess this could do the job:
def import_excel_data(file):
with open(file, "rb") as f:
df = pd.read_excel(f)
for d in df.to_dict(orient="records"):
d['Name'] = json.loads(d['Name'].replace("'",'"'))
app_tables.names.add_row(**d)
import_excel_data('Names.xlsx')
2 Likes