Here’s an Anvil app that uses numpy and the random library to pick from three different distributions, and plot the results.
https://anvil.works/ide#clone:B7EUK42GBSNWWD5X=2VOUNLJAQB6IDMDPHBTC6ZTR
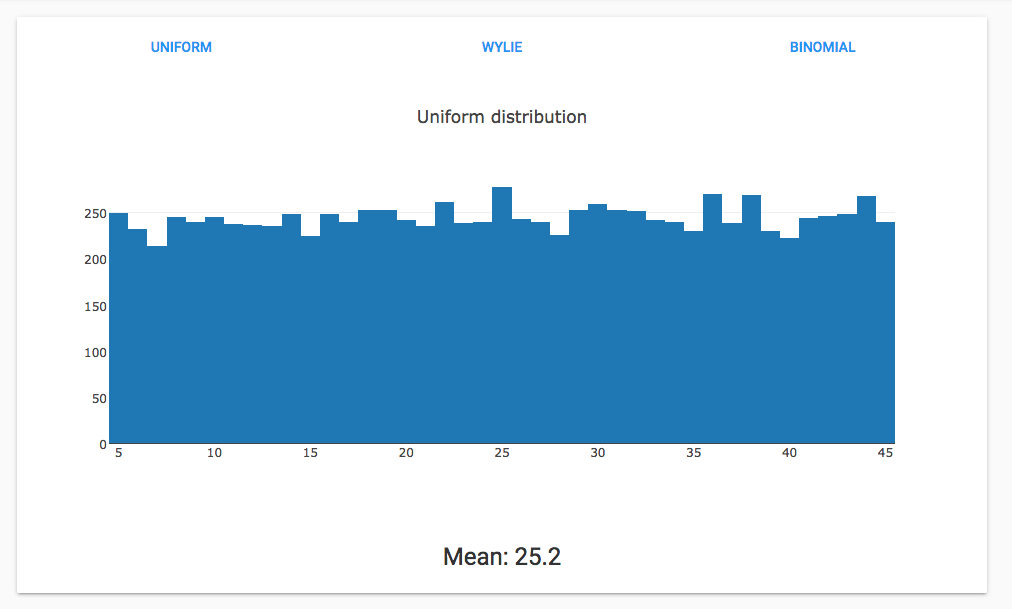
Here’s a uniform distribution between 5 and 45:
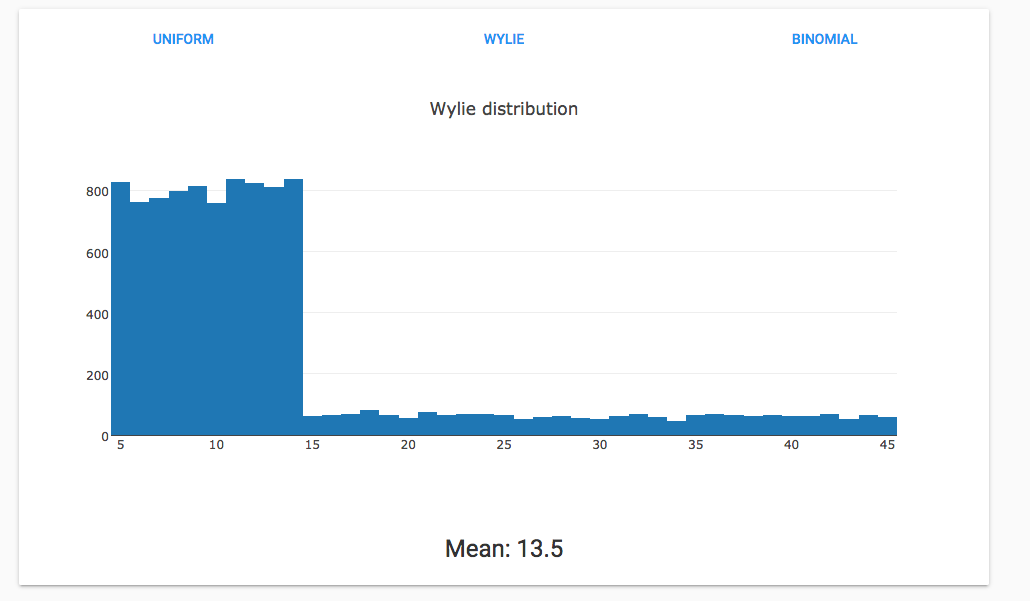
Here’s what happens when you have two uniform distributions that are weighted differently to give a mean of approximately 14:
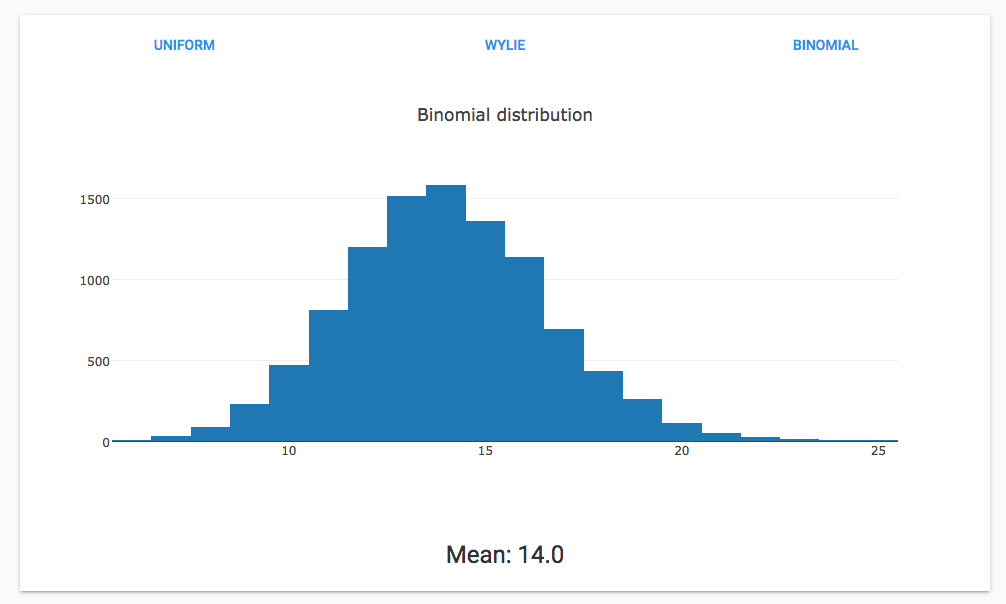
Here’s a Binomial distribution with a mean of 14:
(Credit to @meredydd for the app)
The Wylie distribution picks 4 times from a uniform distribution between 5 and 14 for every 1 pick between 15 and 45.
How to do it without libraries
If you want to do it without needing numpy or the random library, you have to implement an algorithm to pick from a probability distribution yourself. (You still need a random number generator).
You need to work out a Probability Density Function with a mean of 14, call it f(x). This is the probability of picking a number x. For a uniform distribution, it is constant. For a Normal distribution, it is the familiar ‘bell curve’ (see fig.1 below).
To pick a number from it, you need to have its inverse function, called the Cumulative Distribution Function. Let’s call it f^-1(p). Then:
- pick a float from 0 to 1, call it
p
- calculate
f^-1(p)
For example, this is a Normal distribution (fig.1):

And this is its Cumulative Density Function (fig.2):

The algorithm I described picks a number on the Y-axis of fig.2. The answer is the corresponding value on the X-axis of fig.2.
You can see that most values picked from the Y-axis of fig.2 are going to come out with an X value near to 0. This makes sense, because most of the probability density in fig.1 is around X=0.