I am trying to extract data from my data table on the server side to present in the following format:
[[{row contents}], [{row 2 contents}, {row 3 contents}] ...
At the moment, I can get the format correct, but I get the row being returned, when I really want a dict with the row values returned:
[[<LiveObject: anvil.tables.Row>, <LiveObject: anvil.tables.Row>, <LiveObject: anvil.tables.Row>], [<LiveObject: anvil.tables.Row>]]
[[<LiveObject: anvil.tables.Row>, <LiveObject: anvil.tables.Row>, <LiveObject: anvil.tables.Row>], [<LiveObject: anvil.tables.Row>]]
Each of the anvil.tables.Row items above refers to a “Push” that’s stored in the linked_pushes column - here’s the table Row I’ve searched for:
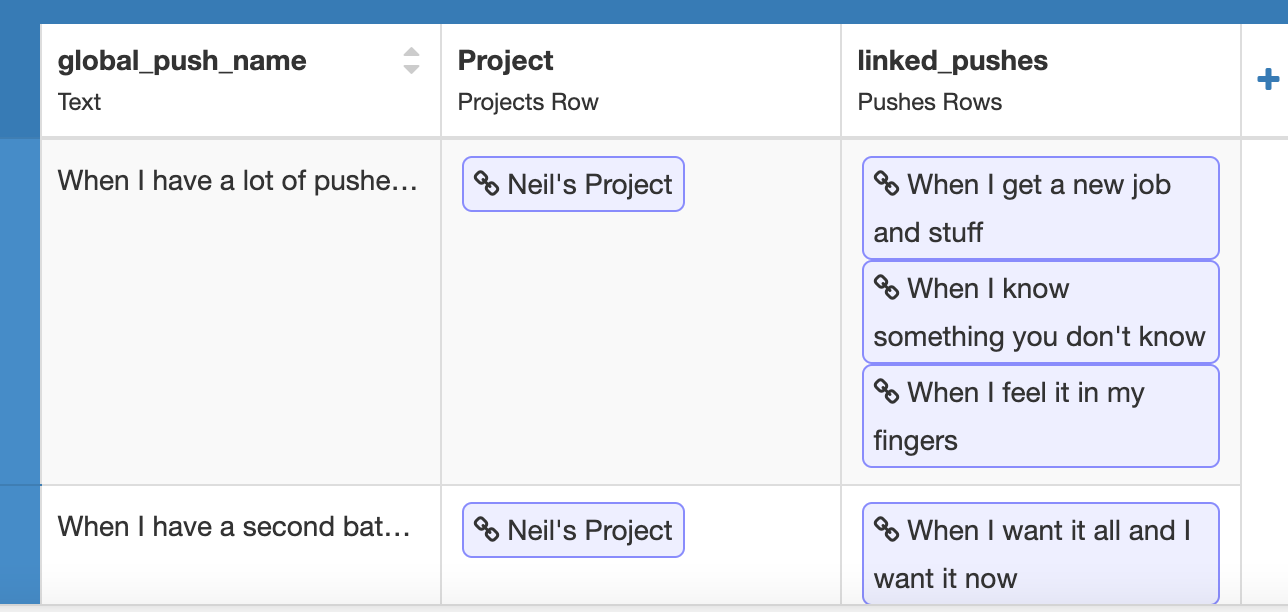
I’m using this code to extract the list above:
@anvil.server.callable
def get_push_global_pushes(my_project):
ilist = [
{
'linked_pushes' : r['linked_pushes']
}
for r in app_tables.global_push.search(Project=my_project)
]
irowlist = [d['linked_pushes'] for d in ilist]
return irowlist
The output should be a list, where each row in the Global_Push table has an embedded list of “linked_pushes”, and each of these is unpacked into a dict giving me the Push text and linked Interview “interviewee_name” - see the Push table below:
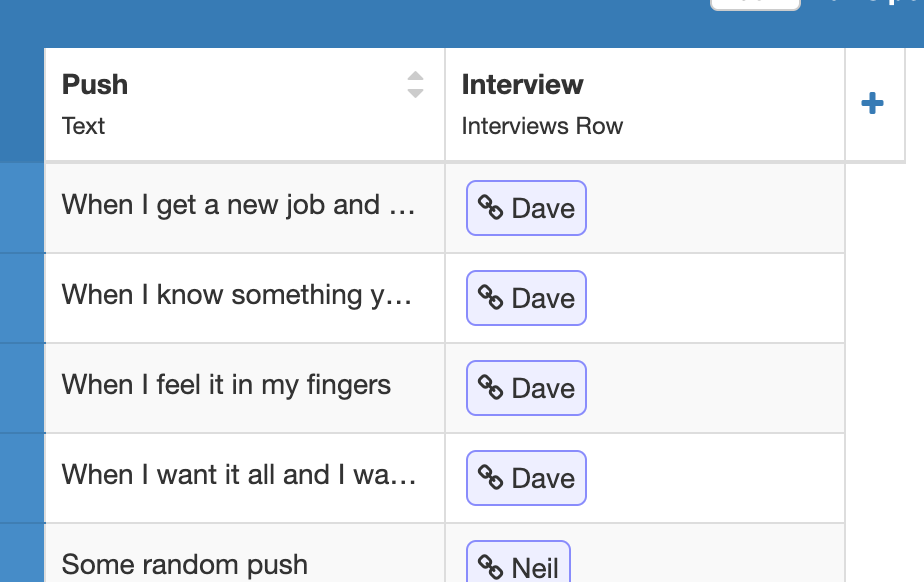
And here’s the Interviews table:
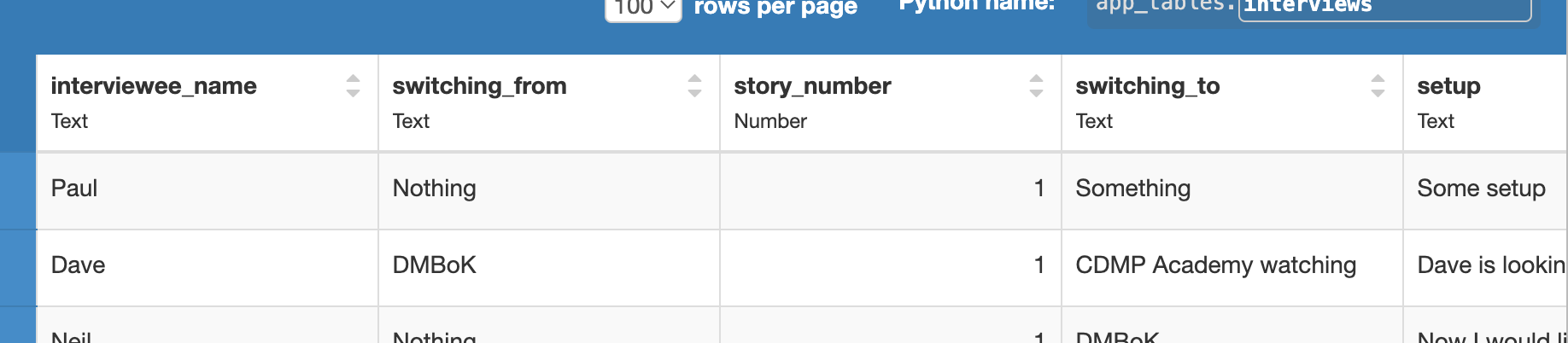
I keep trying various convoluted methods to extract the information, but I’m tying myself in knots. Is there a straightforward way for me to iterate over the list output I’ve shared above, and turn each Row into a dict like this:
[[{Push : When I get a new job and... , Interview.interviewee_name : Dave}]