What I’m trying to do:
I want to make a nice , sleek, datatable thats quick to search so i am making one with just a few columns and then all the big info is in another datatable which is linked to the first.
What I’ve tried and what’s not working:
as above - just wondering if linking in this way makes the searches and queries slow?
(obviously i expect that having one more column would make things SLIGHTLY slower, but will this linking make queries noticeably slower?)
Many thanks!! 
If the searched columns are properly indexed, then it doesn’t matter how many columns are in the database. It is going to use the index to do the sorting and the filtering, then it is going to read the required columns only for the filtered rows.
Without indexes on the other hand, I don’t know it the database is smart enough to read only the columns involved in filtering and sorting or if it gets the whole row only to filter it out later. Databases are smart, but when they don’t find an index they may not care or be able to optimize the query.
In Anvil we don’t have complete freedom to generate any kind of indexes. I have a dedicated plan and I have 3 options per column. Here is what I see when I right click on a column header:
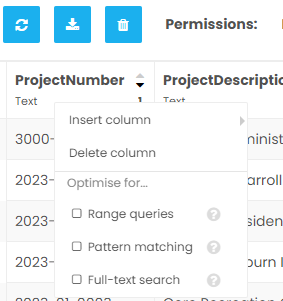
I would just make sure you are using the accelerated tables and you are getting only the columns you actually need, whether they are from linked tables or not. With accelerated tables you can specify what columns to get, including from linked tables, while with the old library (if I remember correctly) only columns of certain types are cached immediately, while accessing the other columns, including linked tables, requires one additional query. Per row!
Linked tables were so slow that I have religiously avoided them. It wasn’t the filtering or sorting part, it was accessing the linked table part, after the filtering. I haven’t created any new apps since the advent of accelerated tables, but I plan to give them and linked tables a try in my next app.
1 Like
That’s a matter of how the data are stored. With rowwise storage (most relational databases), entire rows are retrieved from disk. The hardware unavoidably fetches values from unwanted columns, but the filters ignore them.
Occasionally one sees columnwise storage, and in this case, many rows’ worth of the column’s values can be retrieved with a single disk access. This tends to be very good for queries, as the engine fetches only the needed columns’ values, but can be slower for insertion and deletion of rows.
Long variable-length column values (blobs and long text) may be stored elsewhere.
As I understand it, columnwise storage is more common in data warehouses and the like, where the data are not being updated in real time, but are being heavily queried. In all other cases, rowwise storage is the norm.
2 Likes
thanks so much @p.colbert and @stefano.menci !!!