Hi @jim, here are some answers to your questions:
When do you not need to keep the Uplink running?
If you want to call functions in the Uplink script, you need anvil.server.wait_forever() to keep the websocket connection alive and listen for calls. But if you want to call functions in Server Modules from the Uplink script, or use Data Tables (or do anything else), you don’t have to keep the Uplink script running. These scripts do not need to be kept running:
import anvil.server
anvil.server.connect("key")
anvil.server.call("do_something_in_a_server_module", [1, 3, 4, 7])
and
import anvil.server
import sys
anvil.server.connect("key")
app_tables.customers.add_row(name=sys.argv[1], zip_code=sys.argv[2])
Running an Uplink script in App Engine
You can certainly run the Uplink in App Engine! The Uplink is a pip-installable library, so you just need to add it to requirements.txt.
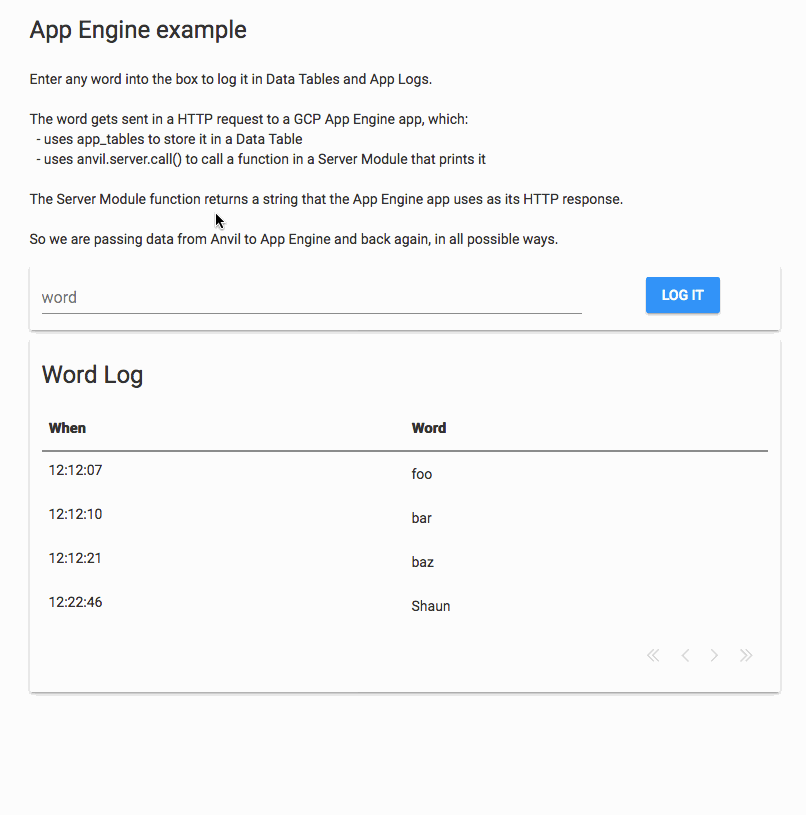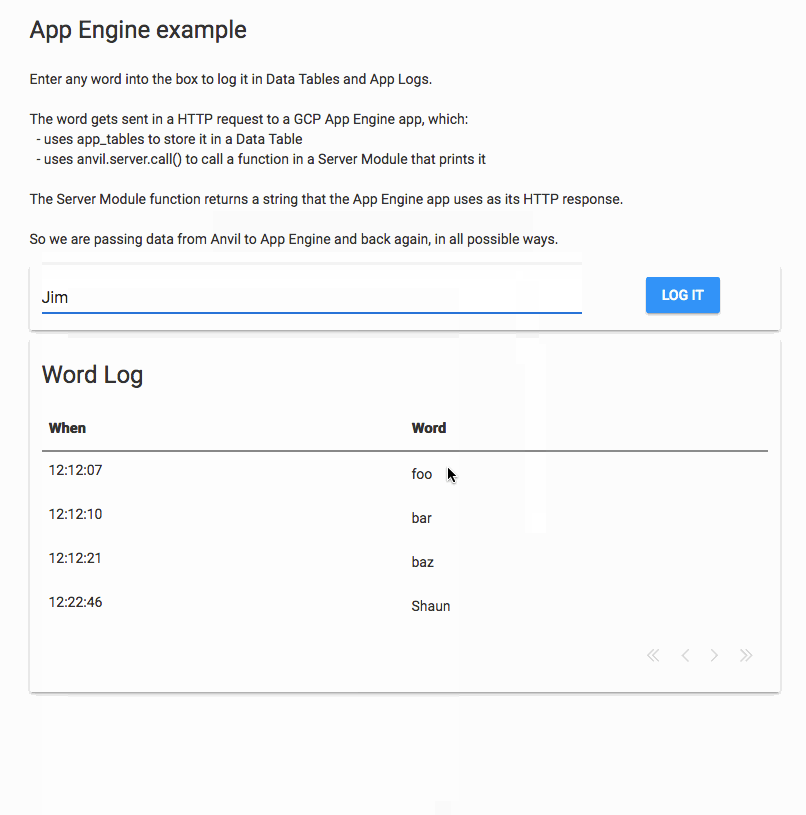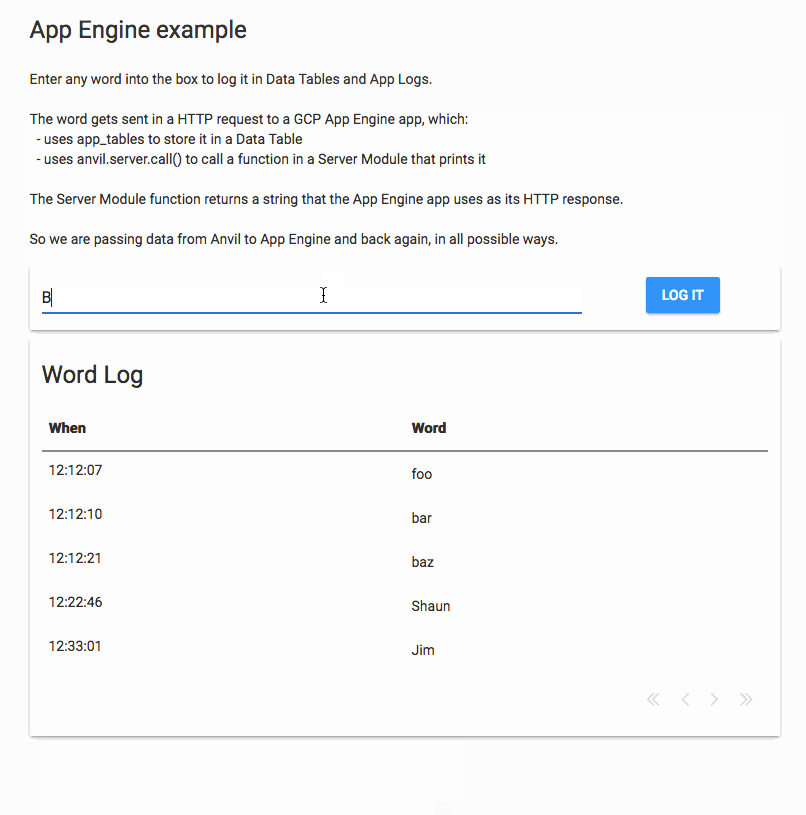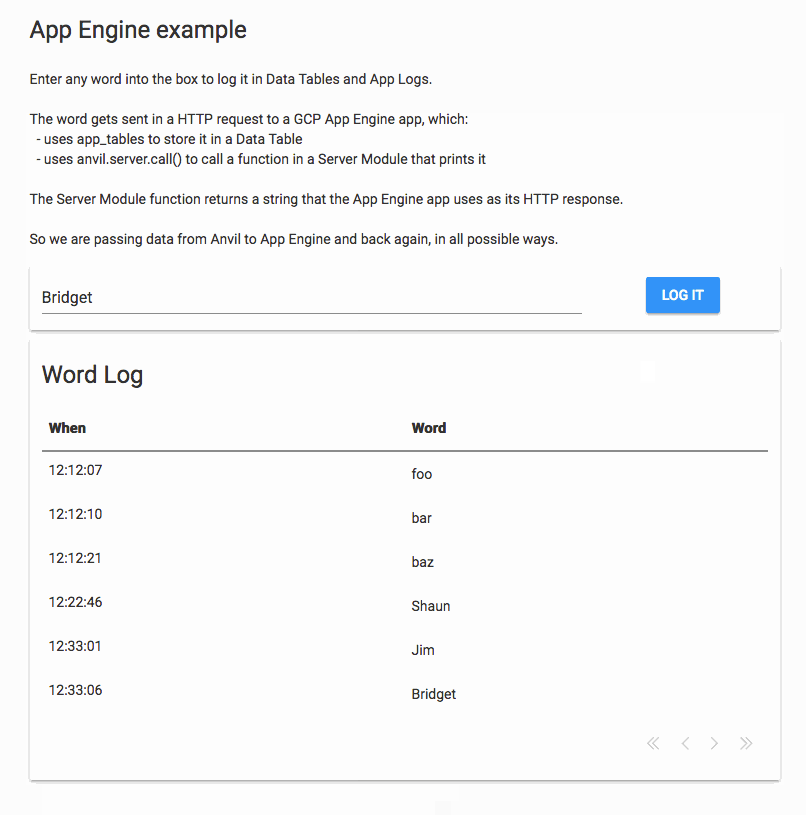
I’ve just successfully tried this out. I created an Anvil app that sends data to an App Engine script, which in turn sends data back to the Anvil app.
The Anvil app has a Button that hits an App Engine app, passing in a name in the path:
# On the client
anvil.server.call('hit_app_engine', self.text_box_1.text)
# On the server
APP_ENGINE_URL = 'https://golden-memory-255409.appspot.com'
@anvil.server.callable
def hit_app_engine(name):
# This could be a POST request if you had lots of data to send.
anvil.http.request(APP_ENGINE_URL + '/logme/' + name)
The App Engine app is a Flask app that uses the Anvil Uplink to store the name in Data Tables, and call a server function.
#!/usr/bin/env python3
import logging
from datetime import datetime
from flask import Flask
import anvil.server
from anvil.tables import app_tables
anvil.server.connect('LB4MGWIXKJOVJHRZXQ7AWZQT-ST5S6MYBRAXYDFUR')
app = Flask(__name__)
@app.route('/logme/<name>')
def log_name(name):
"""Log the request path in a Data Table."""
app_tables.name_log.add_row(name=name, when=datetime.now())
result = anvil.server.call('log_the_name', name)
return result
The Anvil Uplink library is installed by including it in requirements.txt:
~/gcp-projects/anvil-uplink $ cat requirements.txt
Flask==1.0.2
gunicorn==19.9.0
anvil-uplink
This demonstrates sending data from Anvil to App Engine and back in several ways.
Here’s a GIF of that app running:
And here’s a clone link so you can take a look:
https://anvil.works/build#clone:ST5S6MXBRAXYDEUR=NZYBDDU3N4YHRC47AO4PBRU5
I’ve put my App Engine app in Github, it’s here:
Can you make concurrent calls to Uplink scripts?
Yes, it’s a fully multi-threaded server. If you create a script that does this:
#!/usr/bin/env python3
import anvil.server
from time import sleep
anvil.server.connect('GTLMTUIUVQI63IW7BWRWZ4Q6-F25JU2MCAKFCK5PX')
@anvil.server.callable
def run_the_thing():
print('running...')
sleep(5)
print('done')
return 'done!'
anvil.server.wait_forever()
And run run_the_thing in quick succession from different instances of your app, you get this output:
running...
running...
running...
running...
running...
done
done
done
done
done