That line of code doesn’t make sense. If you’re adding a row, you get back one row not a list. What are you actually trying to accomplish with that line?
You don’t say which background task you’re actually using now, but I’ll assume it’s func_1. You have this code:
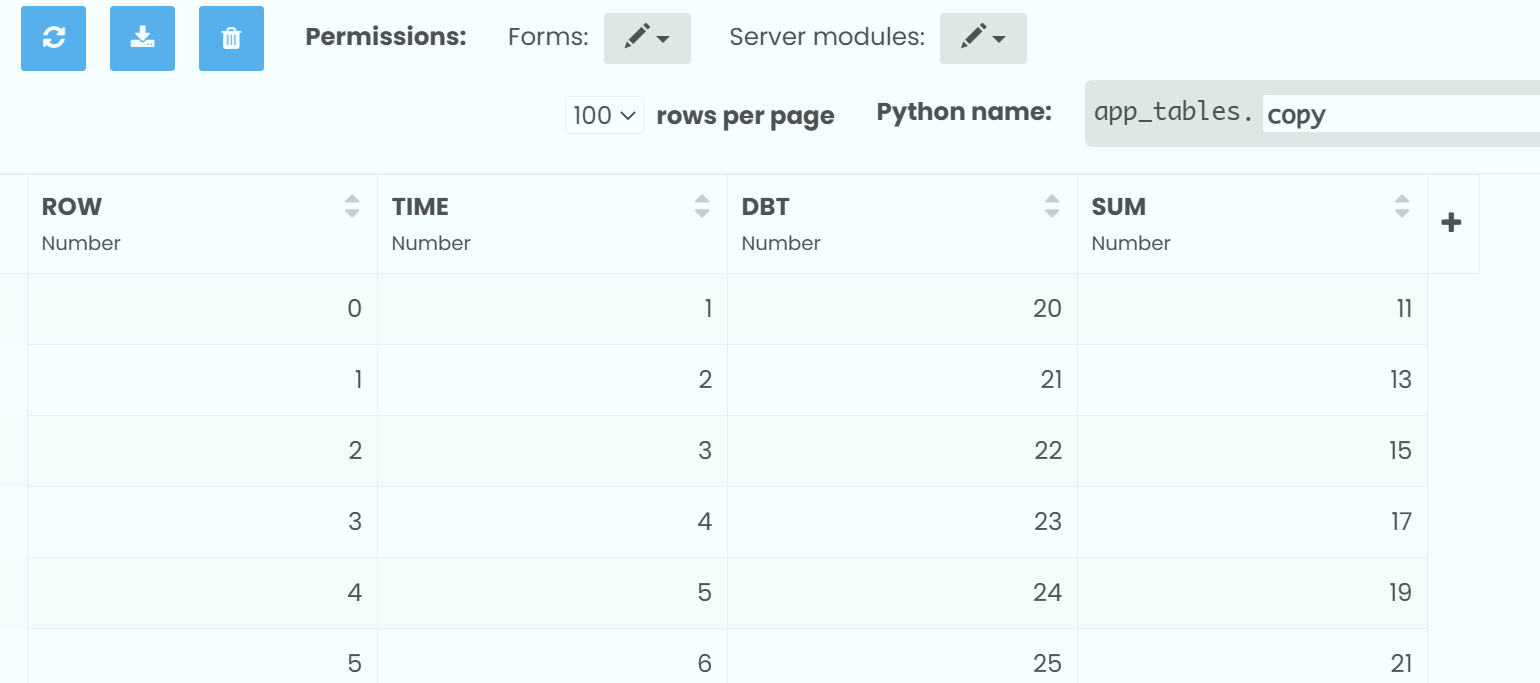
all_rows = app_tables.copy.search()
for row in all_rows:
row['SUM'] = None
for row in app_tables.data.search()[startrow:stoprow]:
SUM = (row['TIME'] + row['DBT'])
print(SUM)
app_tables.copy.add_row(SUM = SUM)
for row in itertools.islice(itertools.count(), startrow, stoprow, step):
print(row)
app_tables.copy.add_row(ROW = row)
for row in app_tables.data.search()[startrow:stoprow]:
DBT = (row['DBT']+10)
app_tables.copy.add_row(DBT=DBT)
I don’t know why you’re doing identical searches, or why you’re doing an add_row instead of modifying the existing row you already have. You modify the existing row when you set the Sum column to None, so I’m not sure exactly what you’re trying to accomplish with the add_row calls.
I have to make a lot of assumptions, because the code I’m seeing doesn’t match up with what I thought you wanted to do. Either I’m wrong on what you wanted to do, or you’re confused about the coding. If I’m wrong, you’ll have to explain in detail what you’re trying to accomplish.
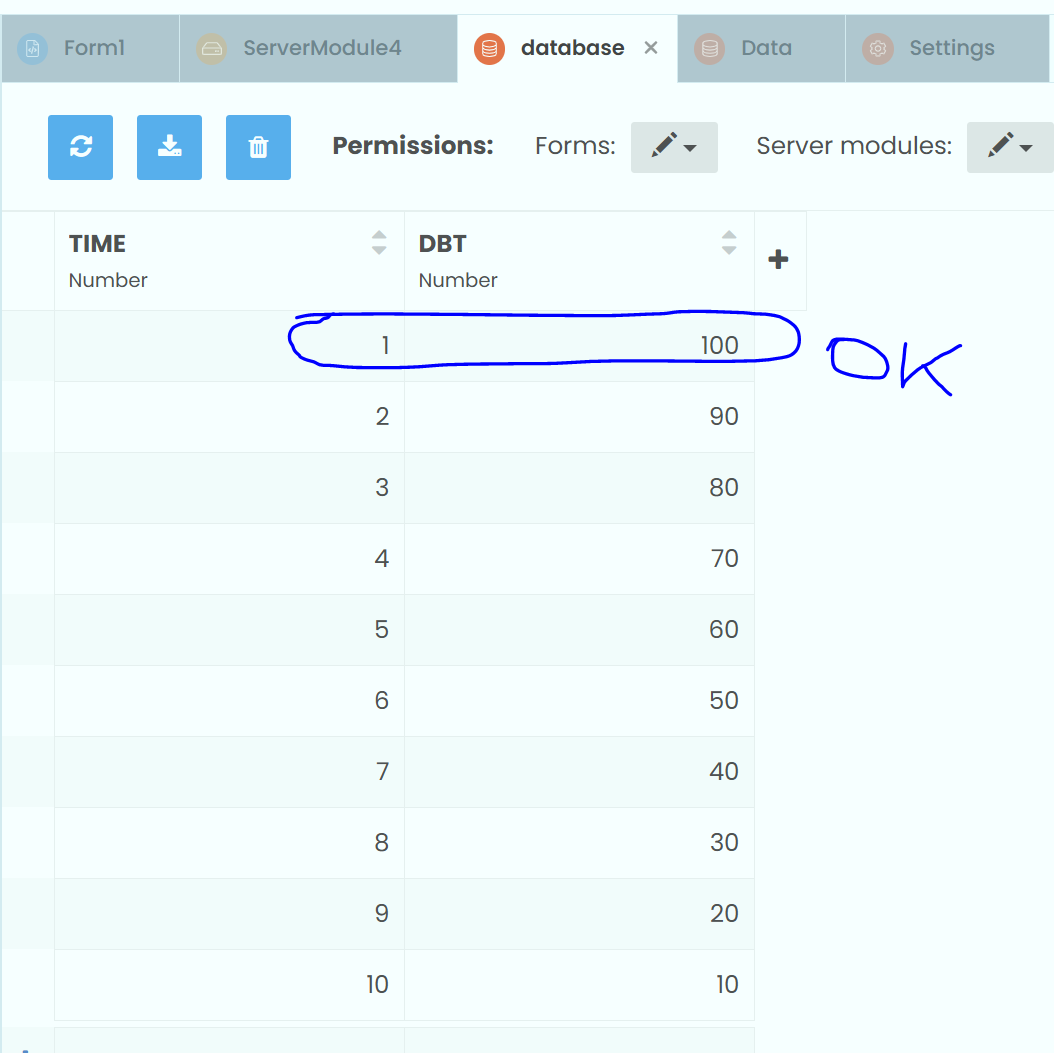
On the chance that you’re confused about the coding, I’ll show you the code to do what I thought you’d wanted to do (this is limited to just a couple of the calculations, you can extend it from there if this is what you’d intended) :
all_rows = app_tables.copy.search()
for row in all_rows:
row['SUM'] = row['TIME'] + row['DBT']
row['DBT'] = row['DBT']+10
You only use add_row if you actually want to add a brand new row. If you want to edit an existing row, don’t use add_row.
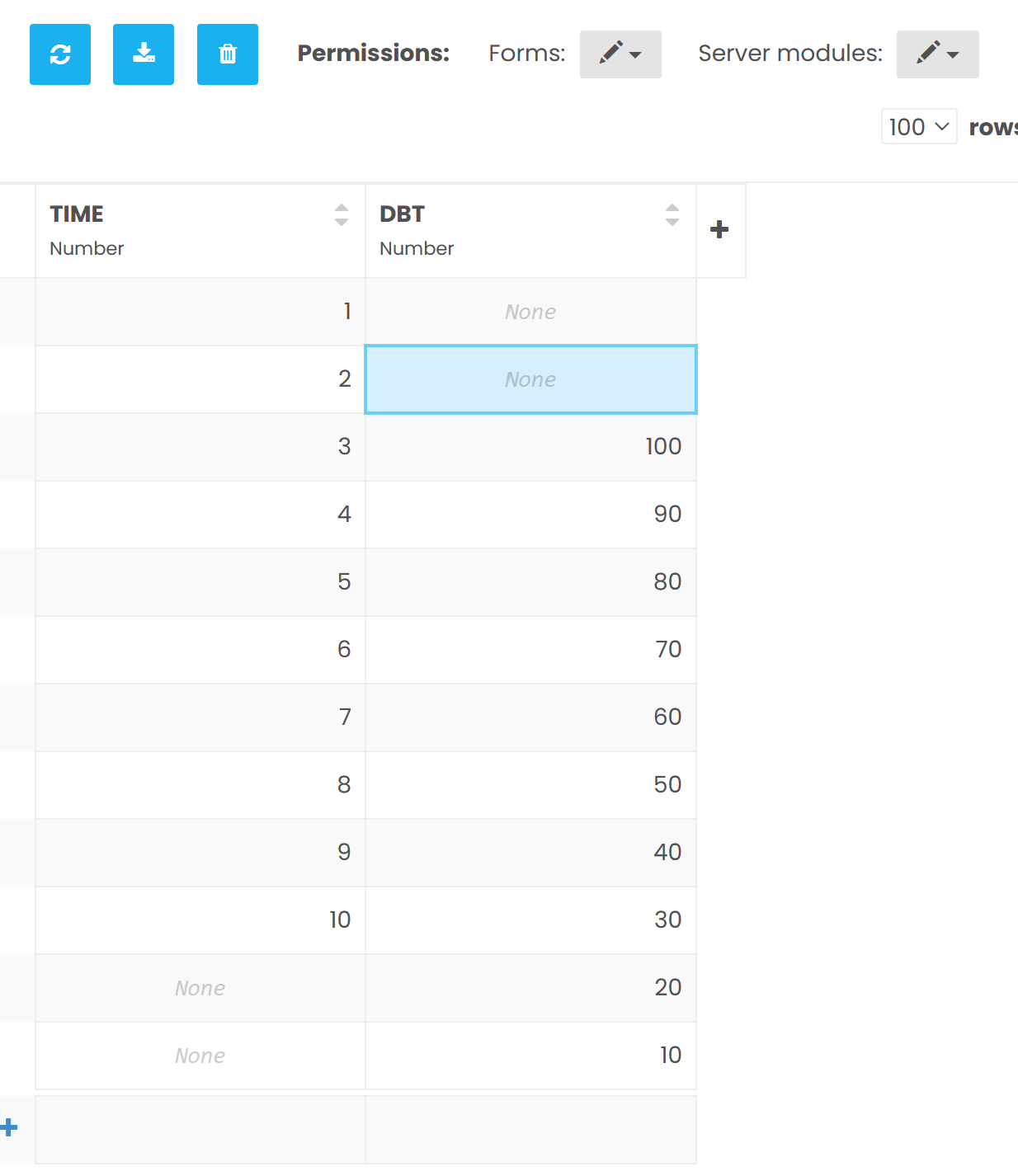
You have some other code that also doesn’t make sense. You do slicing on the results, e.g. app_tables.data.search()[startrow:stoprow] but you have not specified an order by clause. The order in which results are returned are only predictable if you tell the search how to order the results. Slicing on results only make sense when you also have them ordered.
I have no idea what you’re trying to do with the itertools loop. If you can explain that without code, we might be able to help you accomplish your goal.