My app accepts a large spreadsheet (10-20k rows x ~8 columns) and loads them to two datatables. The next time I upload the spreadsheet, the code seeks out new records or modifications and updates the datatables accordingly. This works OK.
In another part of the app, I now interact with the records. Common operations include: “give me twenty random records”, “show me all records that look like X”, “get me a random record that looks like Y.” While in this part of the app, there will be many such interactions. Previously, I was making a db call for each transaction, but I was paying that lookup tax every time – ~2-5 seconds. I’ve pivoted to now trying to pay the tax all at once upon launching the screen, instead of upon each transaction. Now, with the data now residing in the client, the screen load takes a while (which I’m OK with), but subsequent interactions are lightning fast. I’m impressed with Anvil; my friends are impressed with Anvil. All is good.
However, as the underlying tables have grown, my 30 second limit is regularly exceeded. I converted my large calls to background tasks. Being on the Personal Plan, I hoped I would no longer see the timeout issues but still am. The server is running Full Python 3. In some cases, if the calls return fast enough, I receive the Downlink Disconnected error (due to how much data is getting returned). I love, love, love the Anvil product and very much hoping to stay entirely within its boundaries.
Other things I’ve tried to reduce return times include, but are not limited to:
- returning a generator and building the list client-side (was taking ~15m)
- converting the datable to a Pandas dataframe and returning a list of dicts (that’s the current implementation)
- pickling and/or parqueting
Here is my current construction:
client code

server code that launches my background tasks
Below is the code run four times. Seeking feedback on how to remedy both errors – or even alternate approaches.
- Background task on Personal Plan producing “Server code took too long”.
- “Downlink disconnected”.
Trial #1:

Trial #2:

Trial #3:

Trial #4:

Writing this just before I go to bed, so I might not respond again until tomorrow, but …
Trial #1 & #4 - can’t comment on as you don’t show what line 65 does.
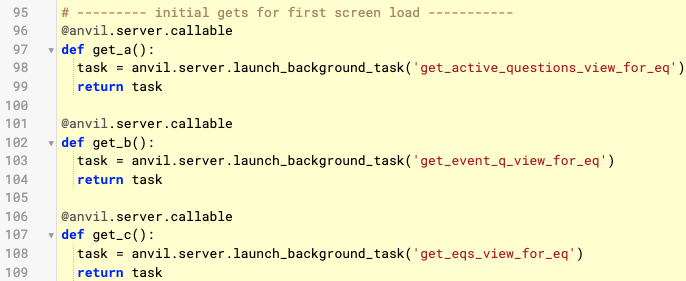
But assuming line 40 is the call to “get_c” … can you please post your background task code for “get_eqs_view_for_eq”? My guess is that it might be doing something funky.
Your background task code can take a long time on a paid plan, but if you call another anvil server function within that code, that might still be subject to the timeout.
Of note, with the three background task launches, if I change the ordering, the timeout occurs at different lines. This makes me think that the timeout isn’t sensitive to the specific function. It is specific to when I run out of time.
Here’s an example where I re-order the calls and it still bombs on the third call.
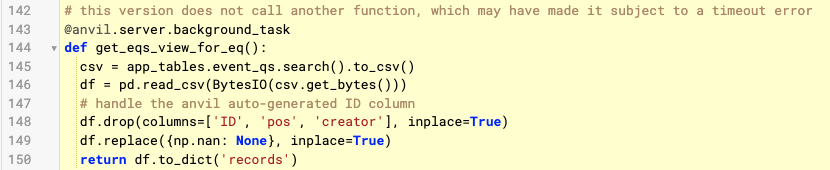
If still interested in get_c, this is it. It’s a datatable → Dataframe → list of dicts conversion. That implementation was proving faster than others.
Regarding the Downlink disconnected error …
Line 65 was the just next line of code that is run. It retrieves data from a four row datatable.
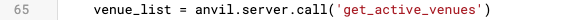
By the time I reach line 65, I’m assuming I’ve used up 99% of my permissible data, and no matter what data I retrieve next, I’ll receive the Downlink error. (Note: I commented out everything past my first three calls, but I was only able to get past the Timeout ~5% of the time. I haven’t been able to get past them in my subsequent trials to reach code completion.)
It’s late here and I’m tired & drunk, but …
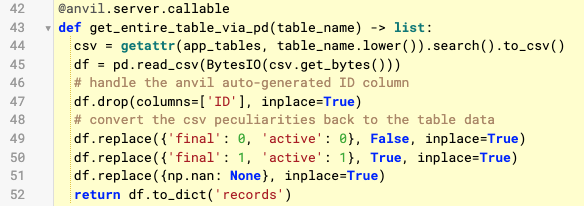
I think your issue is related to the fact you call a server function from within your background task. I can’t cut and paste the lines because they are screenshots, but in your post above line 138 calls line 43.
I think that server function call is still subject to the standard 30 second timeout even though it’s called from within a background task. My comment assumes that the function does in fact take a long time. That would be something to test.
It might take someone more knowledgable that me to confirm that, though.
2 Likes
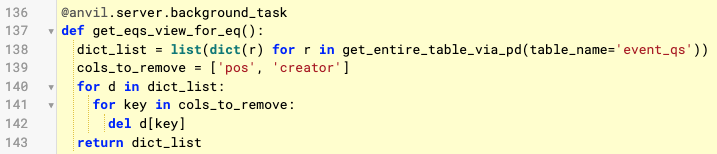
There also seems to be a lot of redundant processing going on. Anytime you’re processing every row in a data table, you should try to make sure you’re doing it just once. You’ve got four times in the server, by my count.
-
First the search().to_csv() will process every row in the data table to create the CSV records.
-
Then the dataframe is constructed from that CSV, which will need to process all the records again
-
Then there’s a conversion to a dict, which probably processes all the records again (unless that’s just exposing an internal data structure in the data frame)
-
Then you do a for loop over every entry in the dict to delete a couple of columns
Unless the conversion to a dataframe is having some other side effect that isn’t apparent, all of that could be optimized down to just processing all the rows in the search results once to construct a list of dicts with the fields you want, e.g. (totally untested):
rows = app_tables.table_name.search()
results = []
for row in rows:
entry = dict(row)
del entry['pos']
del entry['creator']
results.append(entry)
That could be generalized, of course, but it seems like you’d end up with the same list of dicts, with far less processing. As the number of rows in the table grows, even processing just once might run out of the 30 second limit, but if you keep all the processing in the background task it should avoid that limit.
David, I removed the function calls within the server functions, but still receiving the “Server code took too long.” Still not able to wrap my head around “Server code took too long” with a background task.
jshaffstall, I agree that it’s an interesting workaround.
Time trials as of this moment (consistent with their respective times when I updated the code last month):
- With Pandas: average of 38s.
- Without Pandas, using your code (which is where I started originally), 2m50s – only tried once because I didn’t feel like trying again :\
Hmm, Pandas must be doing everything in compiled code, so is taking advantage of speed there.
Can you avoid the final loop to remove pos and creator by removing those from your dataframe before converting it to a list of dicts? You’re already removing the ID column there, why not the others, too?
That’s all just trying to optimize code that shouldn’t really need optimized, though. You shouldn’t be seeing a timeout on background tasks alone.
Yeah, definitely. Based on David’s suggestion, I am doing all of the dataframe work in a single background task function now and dropping the unneeded columns in one go.
In a similar problem of mine, that was exactly the problem:
I think your issue is related to the fact you call a server function from within your background task.
In my background task I called a function with something like
result = anvil.server.call('my_function', my_param)
I just changed that to:
result = my_function(my_param)
and the timeout error went away.
I haven’t checked the thread if this has already been checked, but another thing to check is that your App is set on Full Python 3 and not on Basic Python 3.
BR and thanks @david.wylie !
In server-side code,
should be used to call Uplinked functions. But if the called function is in the server-side code, calling it directly is much faster.
1 Like
I removed the function call from inside the background task as suggested by David and Ercolani. Today, the background tasks complete. (They get data from datatable into a list of dicts.) I am able to return a task object now, which is one step better than before.
The goal is to return the data from the datatable to the client. I’m guessing this is the easy part, but in my review of this topic, I’m not seeing how to get the data returned as well.
If someone can point me towards that answer, it would wrap up my origin inquiry and help me stay fully Anvil.
My standard tactic, for any long-running process, is to reserve a durable place (create a database table row) for the result(s). You may even have such a table already, to represent the initial request.