You can get to a media object from a DataFrame by serializing the DataFrame.
You can get to a DataFrame from a media object by reading the media object’s bytes.
Here is an example showing some back-and-forth conversions for both json and csv content types.
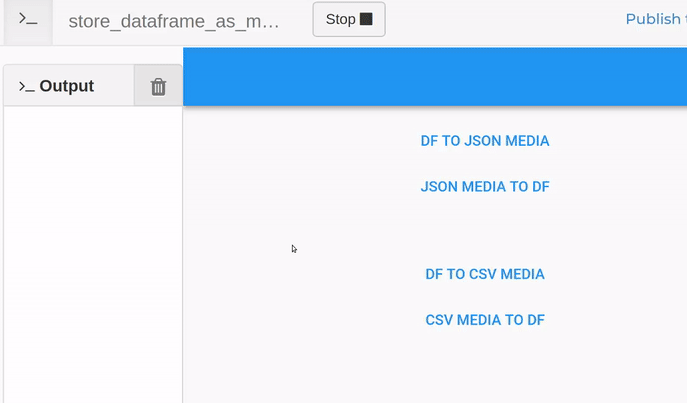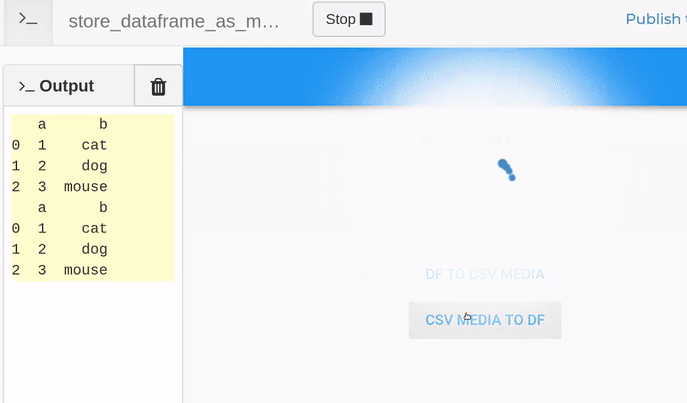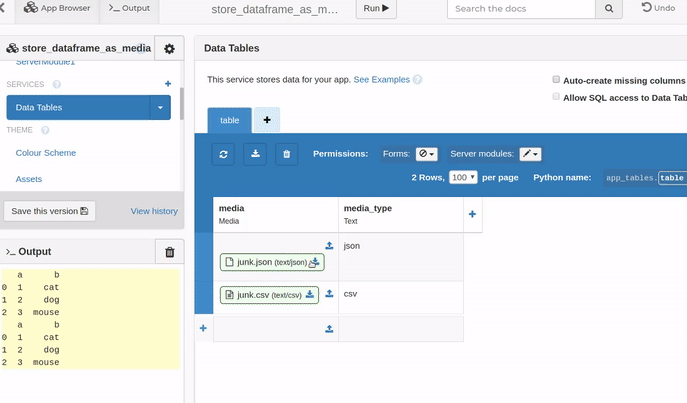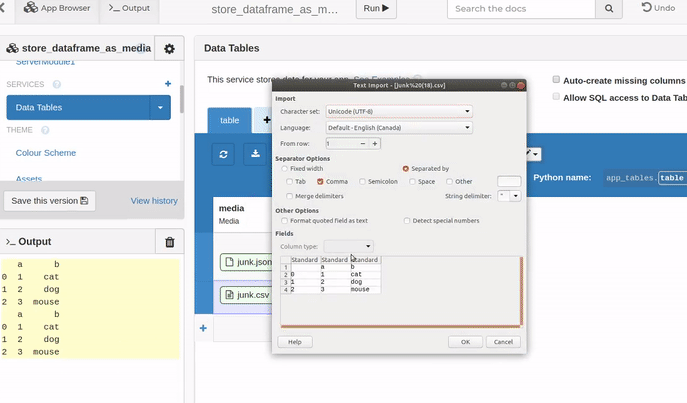
clone the app:
https://anvil.works/build#clone:FIMSJJBV5EYKZQ7K=NJH74Q6AGAH4HHPWH7N2TVID