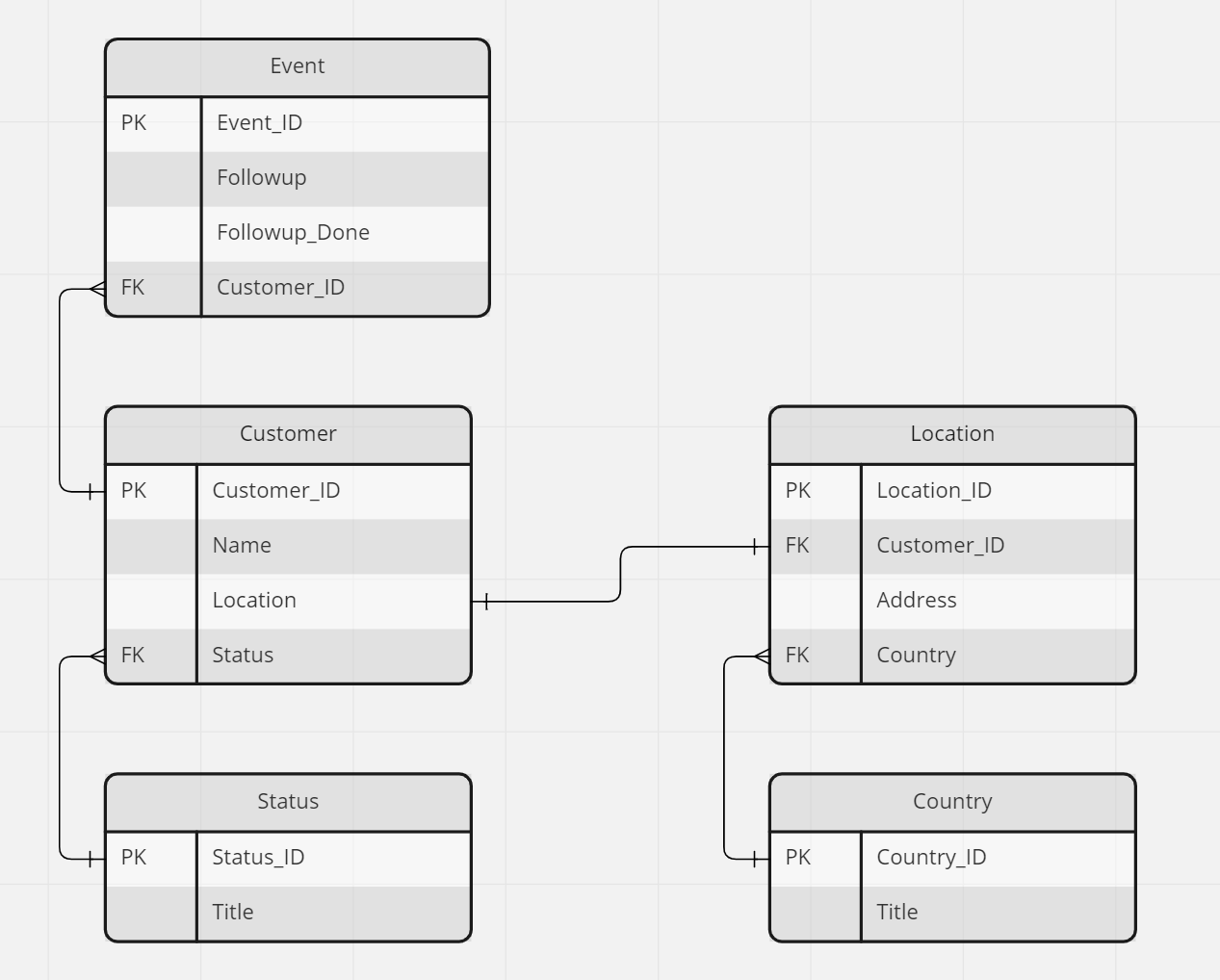
What I’m trying to do:
I have a function which fetches a list of customers, based on a few linked tables.
I am trying to optimize the speed of the query, and have at this point gotten it down to 5-6 seconds, which is okay for the use, as it is meant to be used approximately once few hours at most.
During my testing, and coming up with the correct query, I discovered, that doing one of the sub-queries as a list-comprehension saw dropped the execution time by more than double.
And “flipping” that comprehension reduced it even further.
I was hoping, someone could help me shed some light on why this is, so as to improve my query-writing skills for the future.
What I thought I knew about Anvil queries
After going through the task of optimizing queries several times, and getting some great help and learnings from the Anvil community, one thing I though was pretty important, when constructing multi-table queries, was:
Using the built-in query tools in the Anvil toolkit (q.any_of, q.all_of, etc.) was quicker, than doing the queries one by one, and using Python functions to filter, sort etc.
Adding to that, I was under the understanding, that passing a query directly as a parameter for another query, let the database handle everything internally, thus increasing speed, as there is no need to translate to and from Python objects that often
Therefore, I am not quite sure, why Method 2 and 3 in the below code, is so much quicker, than Method 1.
Am I missing something, or am I misunderstanding, what my own code is actually doing?
Thank you in advance.
Method 1
# Execution-time:
# +30s (Server took too long to answer)
result = []
seen_ids = set()
for e in app_tables.event.search(
q.fetch_only("followup", "followup_done", "customer"),
customer=q.any_of(
*app_tables.customer.search(
location=q.any_of(
*app_tables.location.search(
country=q.any_of(*country)
)
),
status=q.any_of(*status)
)),
followup=followup['has_followup'],
followup_done=False
):
seen_ids.add(e['customer'].get_id())
result.append(e['customer'])
return result
Method 2
# Execution-times:
# 16.24s
# 15.17s
# 15.08s
result = []
seen_ids = set()
for e in app_tables.event.search(
q.fetch_only("followup", "followup_done", "customer"),
customer=q.any_of(*[l['customer'] for l in app_tables.location.search(country=q.any_of(*country)) if l['customer']['status'] in status]),
followup=followup['has_followup'],
followup_done=False
):
seen_ids.add(e['customer'].get_id())
result.append(e['customer'])
return result
Method 3
# Execution-times:
# 5.90s
# 6.13s
# 5.56s
result = []
seen_ids = set()
for e in app_tables.event.search(
q.fetch_only("followup", "followup_done", "customer"),
customer=q.any_of(*[c for c in app_tables.customer.search(status=q.any_of(*status)) if c['location']['country'] in country]),
followup=followup['has_followup'],
followup_done=False
):
seen_ids.add(e['customer'].get_id())
result.append(e['customer'])
return result