I nearly took you up on that semi-implied challenge, but cut my post down when even I couldn’t be bothered to read it all back 
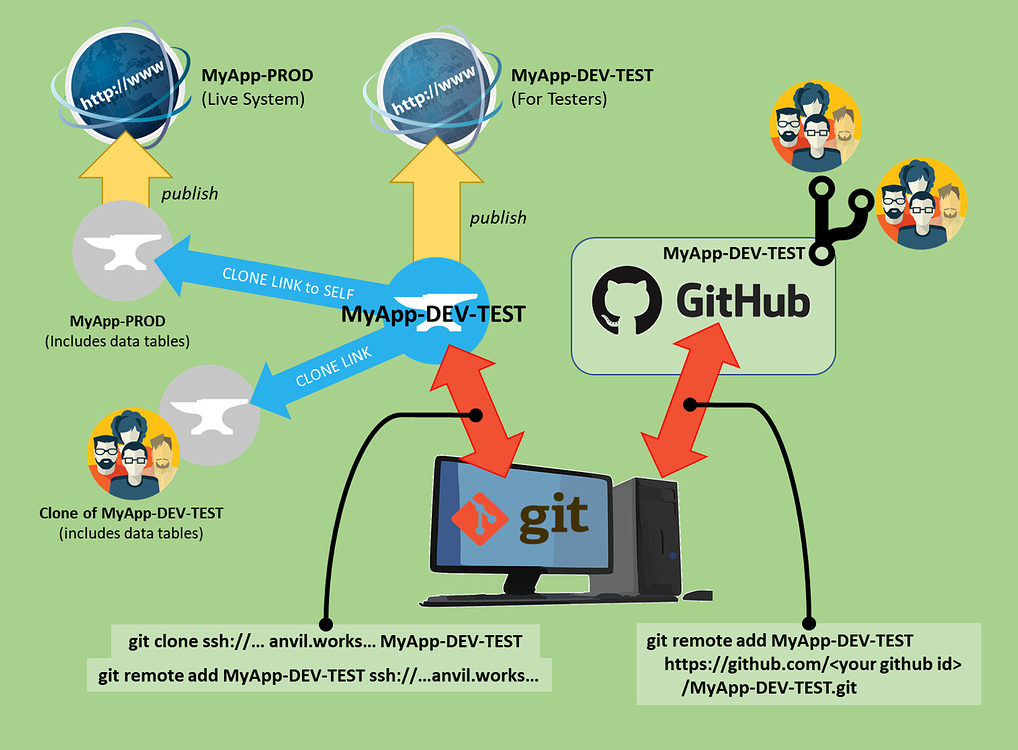
One of the “problems” with programming languages and their environments becoming easier to use is that one can lose sight of the fact that developing is hard. Anvil has lowered the bar to web development significantly but to do that it has had to hide and simplify some quite complex processes, as well as prioritise features. Team development moves you into non-trivial land.
I would love to see a version control built in that allows you to check out a package, blocking anyone else from working on it, and then merges all the changes, highlighting errors, creating a test environment just for you then…etc., etc. The problem is, I’ll bet there’ll be as many competing, incompatible ideas from others of varying development experience. And actually, that’s only what I think I want. If I ever got that I might end up saying, “Oh, no, that’s not as good as it sounded in my head!”
It’s a tough one, but I think when you are working on a project with a team, you have stepped onto the next rung of skills expectations and need to bite the bullet (which you’ve done).
I’ll bet that once you’ve worked through your list for the 40th+ time on large & non-trivial projects you won’t even notice the “Git incantations” (great phrase, by the way) as being anything other than just “what you need to do to make things work”.
What I would like to see is a really, really clear set of instructions, with pictures, of a team project set up where, for example, 2 people are working on the UI and 2 people are working on the back end. Advice on how to ensure no one clashes, what to do if they do, how to merge all the code, best practises. A proper guide that idiots like me could stick up on my wall and use as a bible, from someone(s [sic]) who really, really understand the process.